pytorch学习笔记(三)——MNIST手写数据集
配套视频1
配套视频2
pytorch入门之手写数字识别
- 目录
-
- 引言——MINIST是什么?
- 基本构造
- loss
- 小结
- 非线性模型构造
- 梯度下降优化参数
- 如何进行预测
目录
引言——MINIST是什么?

现如今诸如车牌识别,验证码识别,身份证识别等应用在我们的日常生活中被使用的越来越广泛。为此有专门学者收集了基本数字从0-9不同写法的书写方式,形成一个专门的数据集,这便是MINIST手写数据集的由来。
MINIST手写数据集(官方网站)中,每个数字包含7000张图片,共70k张。每张图片的格式为28*28。训练模型时通常将数据集划分为60k张训练集和10k张测试集。
基本构造

每张输入图片为28*28格式(共784个像素点),用矩阵表示为[28,28],分别表示行列长度。每个像素点数值范围为0-1,0表示白色 1表示黑色(或相反)。
把每张图片平铺成[784]格式,再加上一个维度变为[1,784](图片中dx表示每张图片像素点数),得到输入x。
我们让输入通过第一个权重矩阵 w1:[d1,dx], x乘以w1的转置 :[1,d1],加上偏差b格式保持不变得到H1
依照这种方式依次通过三次权重矩阵得到H3,格式为[1,d3]
注意方框[]中表示的是对应维度的长度而不是数据,如[[1,2],[3,4]],它的维度是2 第一维度长度是2 第二维度长度是2 相当于两行两列的矩阵,第一维度表示行 第二维度表示列 1,2,3,4则是里面具体的数据

loss

根据上面内容我们可以知道,最后得到的输出为H3,我们需要通过H3计算loss从而优化w和b,H3格式为[1,d3],其中1表示输入照片的数量是一张其实就是batchsize,若d3用于指示每张照片对应的数字0-9,则第二维度长度为1,H3格式为[1,1]。
由于数字之间存在着大小关系,这样子表示是非常不合适的,因此采用one-hot一位热编码格式。如图所示,在对应数字下标的数据设置为1 其余都设置为0,例如[1,0…0]表示数字0
所以H3格式为[1,10],再通过以下方式计算loss,用预测的输出H3减去真实label取平方得到loss,loss越小说明预测越准确

小结


pred即为最后的预测输出,也是之前所说的H3。输出H3采用一位热编码,是一个十维的向量,分别表示0-9。pred减去真实label Y计算欧氏距离得到loss,优化loss从而得到最优解
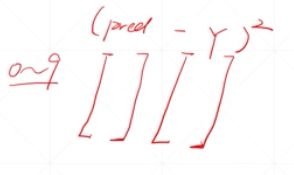
但是此时仍然有一个小问题,那就是以上的网络模型都是线性的
要进行数字识别光靠线性模型我们很难完成这项工作,因此引入了激活函数构造非线性模型。
非线性模型构造
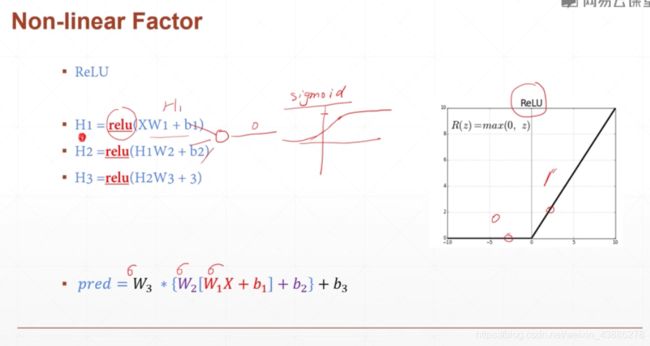
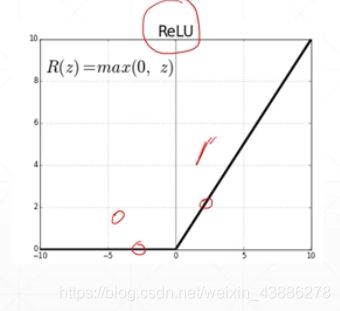
我们引入激活函数ReLU,当输入小于0时输出为0,当输入大于0时输出为本身,通过这样使得输出并非是输入的简单线性叠加,从而构造成一个非线性模型
依次通过三次激活函数,得到新的pred,获得非线性的表达能力。
梯度下降优化参数
我们要优化的目标函数为:

要使得目标函数越小越好,通过优化目标函数,得到最合适的w和b使对于输入x输出的pred能够尽可能接近真实的label y
如何进行预测
对于一个新的输入x,通过非线性模型得到pred,pred是一个十维度的向量,每个维度对应数字的概率。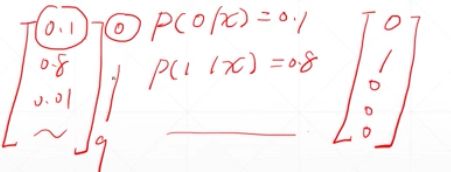
通过argmax函数返回最大值对应的数字下标,如图所示2即为最终的输出