Mysql第七章:mysql进阶(读写分离和分库分表Mycat实现)
目录
1:为什么需要读写分离
2:读写分离实现
2.1:Mysql读写分离配置配置实现
2.2:springboot读写分离代码实现
2.2.1:springboot依赖包pom.xml
2.2.2:数据源配置信息
2.2.3:自定义AbstractRoutingDataSource继承AbstractRoutingDataSource
2.2.4:编写DBContextHolder路由
2.2.5:DataSourceConfig类用来将配置文件的数据源注入动态数据源,将动态数据源注入sqlsession
2.2.6:定义切面Aop
2.2.7:最终结果测试实现类
3:为什么需要分库分表
4:Mycat分库分表实现
4.1:首先配置mycat的配置文件,然后启动mycat
4.2:Springboot整合mycat
1:为什么需要读写分离
但是数据量很大时候,我们的数据库面临着很大的压力,这时候我们需要从架构方面来解决这一问题,在一个网站中读的操作很多,写的操作很少,这时候我们需要配置读写分离,把读操作和写操作分离出来,最大程度的利用好数据库服务器。读写分离的实现就是在执行sql的时候,根据读操作还是写操作,根据读写映射到不同的数据库上。
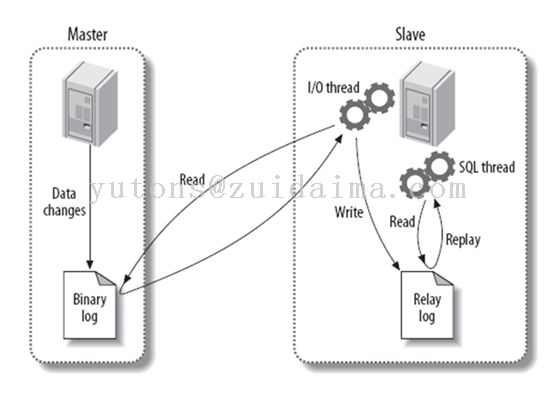
读写分离的实现原理如下图所示:
1:将主数据库中的DDL和DML操作通过二进制日志(BinaryLog)传输到读服务器,
2:然后读服务器又一个单独的IO线程,在master上保持一个链接,把主服务器的日志读取到从服务器的中继日志中
3:从服务器然后读取同步的日志,把操作写入从服务器。
2:读写分离实现
2.1:Mysql读写分离配置配置实现
首先我们在两台centos上安装两个mysql
39.105.173.150 主服务器
39.97.249.96 从服务器
#1: 主库修改配置 vim /etc/my.cnf
#读写分离主库配置添加如下
server-id=1
log-bin=master-bin
log-bin-index=master-bin.index
#读写分离主库配置
#2: 从库修改配置 vim /etc/my.cnf
#从库配置添加如下
server-id=2
relay-log-index=slave-relay-bin.index
relay-log=slave-relay-bin
#从库配置
#3:总库 从库重启
systemctl restart mysql
#4:主库设置
#查看主库状态
show MASTER status
#创建主从连接账户repl
CREATE USER repl;
#从库repl密码123456 根主库连接,有slave的权限
GRANT replication slave ON *.* TO 'repl'@'39.97.249.96'
identified by '123456'
#设置用户权限 主库可以增删改查
GRANT SELECT,UPDATE,DELETE, INSERT ON *.* TO 'work'@'%'
identified by '123456' WITH GRANT OPTION;
#刷新生效
FLUSH PRIVILEGES
#5:从库设置
#创建主库连接,master_log_file的值需要show MASTER status查询
CHANGE MASTER TO
master_host='39.105.173.150',
master_port=3306,
master_user='repl',
master_password='123456',
master_log_file='master-bin.000008',
master_log_pos=245;
#开启主库备份
START SLAVE;
STOP SLAVE;
set GLOBAL SQL_SLAVE_SKIP_COUNTER=1; #(解决状态不是yes)
show SLAVE status;
#设置work用户权限 从库使用work 只能查询数据 主库可以增删改查
create user 'work'@'%' identified by '123456'; #//从库创建work用户
grant select on *.* to 'work'@'%'; #//该用户只有select 权限
flush privileges; #//刷新生效
drop user work@'%'; # //删除用户work
show grants for 'work'; #//查询work权限
2.2:springboot读写分离代码实现
前边根据配置我们实现了主从分离,主库添加数据,从库可以查询。然后我们通过代码实现连接两个数据源,
在此我们思考,由于主从库的数据需要同步,从库的数据可能及时性差点,收到网络影响晚点才能过去,这时候从库查询不到,所以代码应该能够灵活实现有些需求插入主库之后直接从主库查询
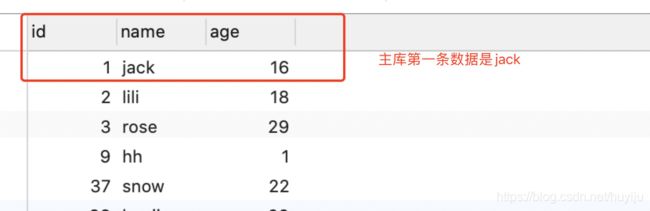
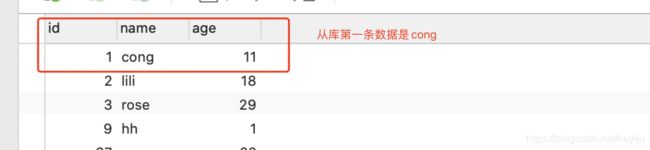
实现读写分离的核心是 AbstractRoutingDataSource,这个抽象类中定义抽象方法,通过map存放多个数据源,然后通过key的值指定具体要是用的数据源。
2.2.1:springboot依赖包pom.xml
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
org.springframework.boot
spring-boot-starter-aop
1.4.0.RELEASE
org.springframework.boot
spring-boot-devtools
true
mysql
mysql-connector-java
5.1.47
com.alibaba
druid
1.1.3
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.1
2.2.2:数据源配置信息
#端口号
server.port=8080
#项目路径
server.servlet.context-path=/rw
#1:mybatis配置信息
mybatis.type-aliases-package=com.thit.dao
#mybatis配置文件
mybatis.config-location=classpath:mybatis-config.xml
#引入映射文件路径
mybatis.mapper-locations=classpath:mapping/*.xml
#读写分离数据源配置
#读写分离数据源配置
#配置主数据库
spring.datasource.master.name=miaosha
spring.datasource.master.url=jdbc:mysql://主库地址:3306/miaosha?useSSL=false
spring.datasource.master.username=root
spring.datasource.master.password=123456
#配置读数据库(配置work账户,只有select权限,进一步增加安全性,防止从库添加数据)
spring.datasource.read1.name=miaosha
spring.datasource.read1.url=jdbc:mysql://从库地址:3306/miaosha?useSSL=false
spring.datasource.read1.username=work
spring.datasource.read1.password=123456
#配置德鲁伊连接池
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
2.2.3:自定义AbstractRoutingDataSource继承AbstractRoutingDataSource
/**
* @author :huyiju
* @date :2020-04-02 16:51
* 继承路由数据源 抽象类 复写determineCurrentLookupKey方法
*/
public class MyAbstractRoutingDataSource extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
//通过key获取数据源
System.out.println("数据源是:"+DBContextHolder.get());
return DBContextHolder.get();
}
}
2.2.4:编写DBContextHolder路由
package com.thit.rw;
/**
* @author :huyiju
* @date :2020-04-02 17:07
* 自定义路由
*/
public class DBContextHolder {
public static final String master = "master";
public static final String slave = "slave";
private static ThreadLocal threadLocal=new ThreadLocal();
/**
* 获取线程的数据源
* @return
*/
public static String get(){
if (threadLocal.get()==null){
threadLocal.set(DBContextHolder.master);
}
return threadLocal.get();
}
/**
* 设置线程的数据源
* @param dbtype
*/
public static void set(String dbtype){
threadLocal.set(dbtype);
}
/**
* 清空线程的数据源
*/
public static void clear(){
threadLocal.remove();
}
}
2.2.5:DataSourceConfig类用来将配置文件的数据源注入动态数据源,将动态数据源注入sqlsession
2.2.6:定义切面Aop
package com.thit.rw;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
/**
* 一些方法读取从库 其他的都是读取主库
* @author :huyiju
* @date :2020-04-02 18:31
*/
@Aspect
@Component
public class DataSourceAop {
//切面是读写分离的核心
//我们在指定的service包下的 以指定方法来读取从库
//其他的我们都来读取主库
//只有service下的指定方法以R_开头读取从库
@Before ("execution (* com.thit.service.*.R_*(..))")
public void read() {
System.out.println("拦截到读取从库方法");
//此处设置读取从库,采用线程安全的方法
//然后在MyAbstractRoutingDataSource
//determineCurrentLookupKey会获取从库
DBContextHolder.set(DBContextHolder.slave);
}
}
2.2.7:最终结果测试实现类
package com.thit.serviceimpl;
import com.thit.dao.TestMapper;
import com.thit.entity.Test;
import com.thit.rw.DBContextHolder;
import com.thit.service.TestService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
/**
* @author :huyiju
* @date :2020-04-02 14:21
*/
@Service
public class TestServiceImpl implements TestService {
@Autowired
private TestMapper testMapper;
//根据ID 查询数据到主库查询
public Test selectbyid(int id) {
Test t= testMapper.selectbyid(id);
return t;
}
@Override
@Transactional
//添加数据到主库,切面不拦截
public int add() {
Test t=new Test();
t.setName("worf");
t.setAge(22);
testMapper.add(t);
return t.getId();
}
//根据ID 查询数据到从库查询,切面拦截
public Test R_select(int id) {
Test t1=testMapper.selectbyid(id);
return t1;
}
}
最中测试结果跟上边截图一致。
3:为什么需要分库分表
随着系统越来愈大,系统的数据量也越来越大,首先是表的增多可能有上千张表,和表数据的增多,比如用户表用户量数亿。这个时候需要我们对系统架构进行优化。我们可以按照业务需求拆分不同的表到不同的数据库以减少单一数据库的压力,同时对于单表数据量超大进行拆分,比如用户表有1亿条数据,我们把每一千万数据拆分到user0,user1...中。降低单个表的查询效率。
按照拆分规则我们分为:
纵向拆分:不同的表按照业务结构拆分到不同的数据库中,按表拆分的方式为纵向拆分,想服务解耦合,分布式、微服务的方向进化
横向拆分:把一张大表拆分成不同的子表,这种方式就是横向拆分。
有了这个需求,我们可以选择解决方案了。我们选择适合的解决方案了。适合作用了分库分表的中间件有很多,但是我们在次选择Mycat
Mycat应用场景
Mycat发展到现在,适用的场景已经很丰富,而且不断有新用户给出新的创新性的方案,以下是几个典型的应用场景:
1:单纯的读写分离,此时配置最为简单,支持读写分离,主从切换;
2: 分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片;
3:多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化;
4: 报表系统,借助于Mycat的分表能力,处理大规模报表的统计;
5: 替代Hbase,分析大数据;作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时Mycat可能是最简单有效的选择;
6:不断强化Mycat开源社区的技术水平,吸引更多的IT技术专家,使得Mycat社区成为中国的Apache,并将Mycat推到Apache
基金会,成为国内顶尖开源项目,最终能够让一部分志愿者成为专职的Mycat开发者,荣耀跟实力一起提升。
Mycat不适合的应用场景
设计使用Mycat时有非分片字段查询,请慎重使用Mycat,可以考虑放弃!
1: 设计使用Mycat时有分页排序,请慎重使用Mycat,可以考虑放弃!(分页查询只能查询到分表之后的单表数据)
2:设计使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布,否则请慎重使用Mycat,可以考虑放弃!
3:设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请慎重使用Mycat,可以考虑放弃!
4:Mycat分库分表实现
前提1:创建两个数据库mycat1和mycat2,
前提2:在连个数据库中创建一张相同的表user,表名和字段均一致
前提3:下载mycat解压缩到本地后者服务器均可
4.1:首先配置mycat的配置文件,然后启动mycat
1:配置rule.xml文件
id
mod-long
2
2:配置 schema.xml
select user()
3:配置server.xml
123456
TESTDB
user
TESTDB
true
4.2:Springboot整合mycat
#mycat配置数据源127.0.0.1 是因为mycat 运行在本地 TESTDB是mycat的数据库
spring.datasource.url=jdbc:mysql://127.0.0.1:8066/TESTDB?useUnicode=true&characterEncoding=utf8
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=123456运行结果:
//添加方法 指定主键,如果不指定,无法做到按照配置的rule规则求膜插入不同的数据库的不同表
@RequestMapping("/add1")
public String addMycat(int id) {
System.out.println("插入数据库除了主键不同,其他的字段写死了,这里不传递");
testService.addMycat(id);
return "Hello Spring Boot!";
}
//分页查询做不到(只能查询到某一个库中的数据)
//查询全部可以返回结果
@RequestMapping("/selectall")
public String selectMycatall() {
System.out.println("mycat测试select");
List list= testService.selectall();
for (User u:list){
System.out.println(u.toString());
}
return "查询总数据量是:"+list.size();
}
//根据名字查询 可以查询到不同库的指定名字
@RequestMapping("/selectname")
public String selectname(String name) {
User u=testService.selectbyname(name);
return u.toString();
}
}