强化学习(2)——基于MC和TD的值函数估计
上一章基础博客【强化学习(1)—— 马尔科夫过程与强化学习】https://blog.csdn.net/jmh1996/article/details/94389616 的最后我们提到强化学习的本质是在马尔科夫决策过程中求得一个最优策略,而且我们指出确定性的最优策略为:

也就是说如果我们知道对于给定的状态 s s s 的所有 q ( s , a ) q(s,a) q(s,a) 的值,那我们设置使得 q ( s , a ) q(s,a) q(s,a) 最大的 a a a 的 π ( a ∣ s ) \pi(a|s) π(a∣s) 为1, π ( ⋅ ∣ s ) \pi(·|s) π(⋅∣s)的其他部分为0 不就可以了嘛???
可是现在的问题是,我们咋求 π ( ⋅ ∣ s ) \pi(·|s) π(⋅∣s) 啊????
本章就来介绍,这玩意咋求。
期望的随机逼近
因为在求 V ( s ) V(s) V(s) 和 q ( s , a ) q(s,a) q(s,a) 时,涉及到很多求期望的运算,我们先介绍一下如何通过样本估计期望。

显然,我们可以使用样本的均值来作为随机变量的期望的无偏估计。
上面这个式子还可以变成增量均值:

它的推导过程是:
u k = 1 k ∑ j = 1 k x j = u_k =\frac{1}{k}\sum^{k}_{j=1}x_j= uk=k1∑j=1kxj=
= 1 k ( x k + ∑ j − 1 k − 1 x j ) =\frac{1}{k}(x_k + \sum^{k-1}_{j-1}x_j) =k1(xk+∑j−1k−1xj)
= 1 k ( x k + u k − 1 ( k − 1 ) ) = u k − 1 + 1 k ( x k − u k − 1 ) =\frac{1}{k}(x_k+u_{k-1}(k-1))=u_{k-1}+\frac{1}{k}(x_k-u_{k-1}) =k1(xk+uk−1(k−1))=uk−1+k1(xk−uk−1)
但是,一般我们还可以使用滑动平均:把 1 k \frac{1}{k} k1 换成固定的一个权值 α \alpha α .于是有
: u k = u k − 1 + α ( x k − u k − 1 ) = ( 1 − α ) u k − 1 + a × x k u_k=u_{k-1}+\alpha(x_k-u_{k-1})=(1-\alpha)u_{k-1}+a\times x_k uk=uk−1+α(xk−uk−1)=(1−α)uk−1+a×xk.
是不是跟以前见到的计算机网络那个RTT的计算很类似??
接下来,我们就用 u k = ( 1 − α ) u k − 1 + a × x k u_k=(1-\alpha)u_{k-1}+a\times x_k uk=(1−α)uk−1+a×xk.来估计 x x x 的均值或期望。
蒙特卡洛值估计,MC

蒙特卡洛值估计的方法还是很简单粗暴啊!
我们的目标是为了求 V π ( s ) V_{\pi}(s) Vπ(s) ,于是对于每一个状态 s s s,我们采样无穷多个episode,然后计算每一个episode的各个时间步t 的 G t G_t Gt,然后对它求指数平均不就可以了嘛。蒙特卡洛方法里面每个episode都要求从 s s s 出发,最终一定会到终止状态。
有两种蒙特卡洛估计方法:
例如对于episode= ( s 1 , s 2 , s 3 , s 4 , s 5 , s 6 . s e n d ) (s_1,s_2,s_3,s_4,s_5,s_6.s_{end}) (s1,s2,s3,s4,s5,s6.send)
- 第一种叫做First-Visit MC 估计

它的特点是,每个episode就只用于更新这个episode的第一个状态的 V ( s ) V(s) V(s)。比如上面的episode,就只更新 V ( s 1 ) V(s_1) V(s1)。
显然这种方式是很浪费的,因为每个episode其实并不好采样,我们应该充分利用每一个 e p i s o d e episode episode.
- 第二种叫做Every-Visit MC估计

第二种方法是说,每个一采到底的episode都是一个具有很多状态的序列,那么对于里面出现的每一个状态 s ′ s' s′,我们都可以更新一次它的 V ( s ′ ) V(s') V(s′)。例如上面的episode,里面所有见到的状态都会被更新。
时序差分值估计 ,TD ( λ ) (\lambda) (λ)
蒙特卡洛值估计简单粗暴,而且是唯一一种能够求得最优值的方法。但是这种方法需要采集大量 到终态的episode,这是它的不足之处。
于是有人就提出,差分值估计的方法。
TD(0)的核心思想:

只往前多采一步,计算这个多采一步的 R t + 1 + γ V ( S t + 1 R_{t+1}+\gamma V(S_{t+1} Rt+1+γV(St+1 作为新的" x x x"值,对他求滑动指数平均。其中 R t + 1 R_{t+1} Rt+1 是本步执行相应动作得到的短期回报, V ( S t + 1 V(S_{t+1} V(St+1是下一个状态的长期回报。
它的示意图:

每一条 s t s_t st到终态的路径表示一个episode.
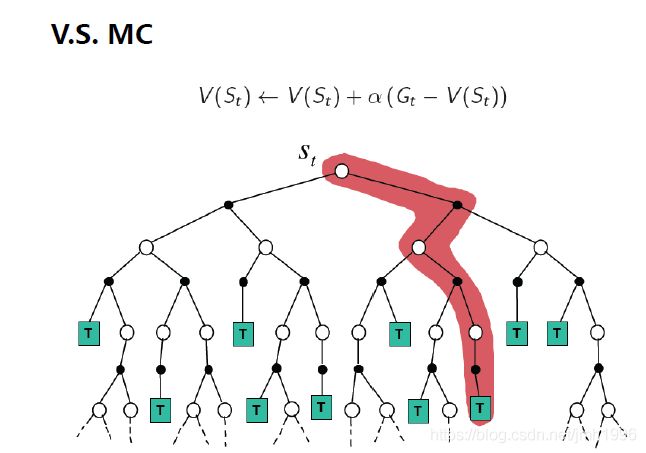
从上面两个图,可以看出MC和TD(0)算法的区别:TD只多走一步,而MC则是一走到底。
TD(0)是多走一步,为了加快收敛,防止TD(0)更新过程中 V ( s ) V(s) V(s)抖动严重,也可以多走 n n n步,于是就有 T D ( λ ) TD(\lambda) TD(λ) 算法。这个算法的核心如下:


它的核心多采n步,然后计算每个 G t ( n ) G^{(n)}_t Gt(n),然后使用一个 ( 1 − λ ) λ n − 1 (1-\lambda)\lambda^{n-1} (1−λ)λn−1的权重把每一步的差分加起来。