深度学习自学第一周(二)logistic 回归模型
继续自学深度学习。
今天主要是对logistic 回归模型进行介绍。
目录
-
- 1.logistic 回归模型
-
-
- (一)logistic 回归模型的符号
- (二)损失函数
- (三)成本函数
-
- 2.梯度下降法
-
-
- 正向传播、反向传播
-
- 3.向量化logistic 回归
1.logistic 回归模型
logistic 回归是一个用于二分分类的算法。我们以识别猫为例子。比如我们输入一张猫的图片,我们知道,在计算机中图片是由像素点表示的,每个像素点分别由R、G、B决定颜色,最后形成图片,所以我们可以认为一张图片是分别由代表R、G、B的三个矩阵构成的。我们要做的就是把这三个矩阵依次放入一个特征向量X中作为输入(X的维数n为三个矩阵的大小相加,我们可以将其表示为n维的列向量),并希望通过logistic 回归预测输出的结果Y为1或者是0。若为1代表这张图片有猫,否则没有。
(一)logistic 回归模型的符号
我们用一对(x,y)来代表一个单独的训练样本。x就是我们上面说到的特征向量,y就是我们的预测结果,值为1或0。训练集由m个训练样本组成{(x1,y1),(x2,y2)…(xm,ym)}。此外,为了方便运算,我们定义一个矩阵X,放入训练集的每个x,表示为:
X = [ ⋮ ⋮ ⋮ x 1 x 2 ⋯ x m ⋮ ⋮ ⋮ ] X=\left[ \begin{matrix} \vdots & \vdots & & \vdots\\ x^1 & x^2 & \cdots & x^m\\ \vdots & \vdots & & \vdots \end{matrix} \right] X=⎣⎢⎢⎡⋮x1⋮⋮x2⋮⋯⋮xm⋮⎦⎥⎥⎤
这样X就是一个大小为n*m的矩阵了。同样的我们定义一个矩阵Y,放入训练集的每个y,表示为Y=[y1,y2,…,ym],这样Y就是一个大小为1*m的矩阵了。
Y = [ y 1 y 2 ⋯ y m ] Y=\left[ \begin{matrix} y^1 & y^2 & \cdots & y^m\\ \end{matrix} \right] Y=[y1y2⋯ym]
接下来我们定义一个符号p,用来让计算机告诉我们这张图片是一张猫片的概率,即
p = P ( y = 1 ∣ x ) , 1 − p = P ( y = 0 ∣ x ) p = P( y=1| x ) , 1-p = P( y=0| x ) p=P(y=1∣x),1−p=P(y=0∣x)
我们再定义logistic 回归的参数为w(同样是个n维向量)和b(实数),这里的b对应为一个拦截器。再定义一个z表示如下:
z = w T x + b z=w^Tx+b z=wTx+b
已知输入x和参数w和b,我们怎么预测p呢?由于要解决的是一个二分分类问题(y=1或y=0),所以我们期望p是一个介于0到1之间的数。于是在这就出现了sigmoid函数,我们将Z的值输入到sigmoid函数中得到输出,输出介于0到1之间,这一输出就表示为p。sigmoid函数的图像如下所示:
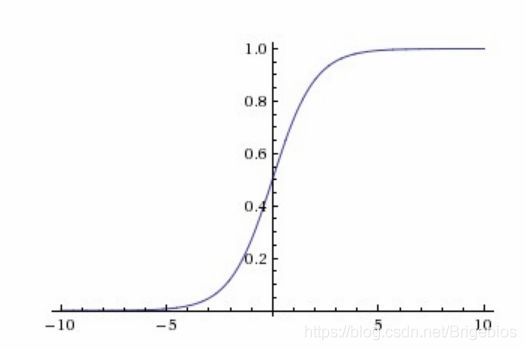
我们把这一sigmoid函数定义为f(z),为了得到0-1的输出,我们有如下函数表达式:
p = f ( z ) = 1 1 + e − z p=f(z)=\frac{1}{1+e^{-z}} p=f(z)=1+e−z1
根据上式可以看出,当z特别大时,f(z)趋近于1,当z特别小时,f(z)趋近于0,这就是这一函数的原理。
(二)损失函数
在logistic 回归中,我们还会定义一个函数,用来衡量我们的预测输出值p和y的实际值有多接近。在logistic 回归中,因为要用到梯度下降法,所以我们有一个特别的损失函数,表示如下:
L ( p ( i ) , y ( i ) ) = − [ y ( i ) l o g p ( i ) + ( 1 − y ( i ) ) l o g ( 1 − p ( i ) ) ] L(p^{(i)},y^{(i)})=-[y^{(i)}logp^{(i)} +(1-y^{(i)})log(1-p^{(i)})] L(p(i),y(i))=−[y(i)logp(i)+(1−y(i))log(1−p(i))]
也可以写成如下形式:
L ( p ( i ) , y ( i ) ) = − [ y ( i ) l o g 1 1 + e − z ( i ) + ( 1 − y ( i ) ) l o g ( 1 − 1 1 + e − z ( i ) ) ] L(p^{(i)},y^{(i)})=-[y^{(i)}log\frac{1}{1+e^{-z^{(i)}}} +(1-y^{(i)})log(1-\frac{1}{1+e^{-z^{(i)}}})] L(p(i),y(i))=−[y(i)log1+e−z(i)1+(1−y(i))log(1−1+e−z(i)1)]
上式表示的上标 i 代表某一训练个例,所以我们可以知道损失函数是针对单个训练样例的函数,它衡量了单一训练样本上的表现,即衡量我们算法的效果。
那么为什么logistic 回归里损失函数要写成这个样子呢?
前面我们了解到关于p的表达式如下
p = P ( y = 1 ∣ x ) , 1 − p = P ( y = 0 ∣ x ) p = P( y=1| x ) , 1-p = P( y=0| x ) p=P(y=1∣x),1−p=P(y=0∣x)
我们还可以写成下面的形式
i f y = 1 : P ( y ∣ x ) = p i f y = 0 : P ( y ∣ x ) = 1 − p if\quad\quad y=1:\quad\quad P(y|x)=p\\ \quad\quad if\quad\quad y=0:\quad\quad P(y|x)=1-p ify=1:P(y∣x)=pify=0:P(y∣x)=1−p
上式定义了关于P(y|x)的表达式,将它们整合到一起,我们可以写成如下的公式:
P ( y ∣ x ) = p y ( 1 − p ) 1 − y P(y|x)=p^y(1-p)^{1-y} P(y∣x)=py(1−p)1−y
为什么写成这样呢?因为我们讨论的是y=1或者y=0两个结果。当y=1时,1-p的0次方为1,P(y|x)表示的就是p;当y=0时,p的0次方为1,P(y|x)表示的就是1-p。符合我们上面的表达式。所以这一公式就是P(y|x)的正确定义。
由于log函数是个严格单调递增的函数,所以我们把P(y|x)作为输入,就有了如下的结果:
l o g P ( y ∣ x ) = l o g p y ( 1 − p ) 1 − y = y l o g p + ( 1 − y ) l o g ( 1 − p ) logP(y|x)=logp^y(1-p)^{1-y}=ylogp +(1-y)log(1-p) logP(y∣x)=logpy(1−p)1−y=ylogp+(1−y)log(1−p)
我们还要往前面添加一个负号,因为当我们训练算法时,我们会希望算法输出值概率是最大的,而在logistic回归模型中,我们需要最小化损失函数,往前加一个负号就能满足我们的要求。
(三)成本函数
我们知道了损失函数是衡量单一训练样本的表现,那么我们同样要再定义一个函数用于衡量全体样本的表现,我们称它为成本函数。我们把这一函数定义为J(w,b),直接写结论:
J ( w , b ) = 1 m ∑ i = 1 m L ( p ( i ) , y ( i ) ) = − 1 m ∑ i = 1 m [ y ( i ) l o g p ( i ) + ( 1 − y ( i ) ) l o g ( 1 − p ( i ) ) ] J(w,b)=\frac{1}{m}\sum_{i=1}^mL(p^{(i)},y^{(i)})=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}logp^{(i)} +(1-y^{(i)})log(1-p^{(i)})] J(w,b)=m1i=1∑mL(p(i),y(i))=−m1i=1∑m[y(i)logp(i)+(1−y(i))log(1−p(i))]
可以看到,相比损失函数,成本函数是基于参数的总成本,它衡量了参数w和b在整个训练集上的效果。所以在训练logistic 回归模型时,我们要选择适合的参数w和b,使成本函数尽可能小。
2.梯度下降法
刚刚提到了,我们想找到合适的w和b,来使成本函数尽可能小,那么我们该怎么做呢?这里我们要用到梯度下降法。我们可以通过下面这张图片来理解梯度下降法的原理:
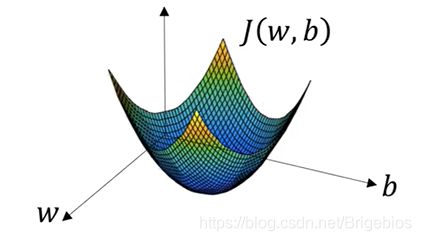
在这张图片中,我们把水平轴分别定义成w和b,尽管w是更高维的,但为了直观感受,我们暂时把w也定义成一个实数。图里曲面的高度表示函数J(w,b)在某一点的值。我们想要做的就是找到一对w和b,使得对应的函数J(w,b)为最小值。可以看到,成本函数J(w,b)是一个凸函数,正是因为我们使用了上面的损失函数才有这个形状。
为了找到成本函数的最小值,我们首先要初始化w和b的值,因为最小值只有一个,所以无论我们初始化在哪里,都应该达到同一点或者大致相同的一点。梯度下降法所做的就是从初始点开始,朝最陡的下坡方向走一步,于是我们就完成了一次迭代。在多次迭代后,我们就有可能得到最小值所在的那一点,或接近全局最优解。
更具体的来说,梯度下降法是怎么工作的呢?我们看看下面这张图:
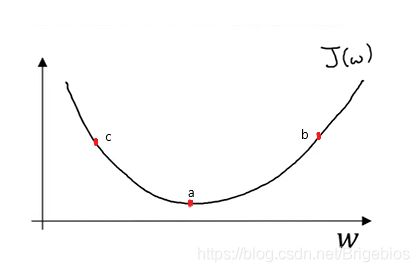
在这张图里,我们暂时把b去掉,单单看w和成本函数的关系。假设图里a点为最低点,即成本函数的最小值。我们把初始值设置在b点,我们利用下面这一式子来更新w的值:
w : = w − α d J ( w ) d w w:=w-\alpha\frac{dJ(w)}{dw} w:=w−αdwdJ(w)
上式的α我们称之为学习率,学习率可以控制每次迭代或者梯度下降法中的步长。我们用α乘于函数的导数,当我们位于b点以下,a点以上时,导数为正值,因此我们每次减去α乘于函数的导数的值时,会越来越接近a点,当位于a点时,导数值为0,w不再更新,这时我们就得到了全局最优解。同样的,我们设置初始值在c点时,导数为负值,我们每进行一次迭代,w的值就会增加,直到a点时停止迭代。这就是梯度下降法的原理。
在logistic 回归模型中,我们的成本函数定义为J(w,b),它的参数是w和b,在这种情况下,梯度下降的内循环可以定义为如下式子:
w : = w − α d J ( w , b ) d w , b : = b − α d J ( w , b ) d b w:=w-\alpha\frac{dJ(w,b)}{dw},b:=b-\alpha\frac{dJ(w,b)}{db} w:=w−αdwdJ(w,b),b:=b−αdbdJ(w,b)
在这里,我们先定义几个符号。
关于w,我们定义J(w,b)关于它的导数为dw,定义J(w,b)关于b的导数为db,定义J(w,b)关于z的导数为dz,通过计算(按照正向传播的步骤,反向求导即可得到结果,相信有导数基础可以很简单求出来),得到如下表达式:
d z ( i ) = p ( i ) − y ( i ) d w = 1 m ∑ i = 1 m x ( i ) d z ( i ) d b = 1 m ∑ i = 1 m d z ( i ) dz^{(i)}=p^{(i)}-y^{(i)}\quad\quad dw=\frac{1}{m}\sum_{i=1}^mx^{(i)}dz^{(i)}\quad\quad db=\frac{1}{m}\sum_{i=1}^mdz^{(i)} dz(i)=p(i)−y(i)dw=m1i=1∑mx(i)dz(i)db=m1i=1∑mdz(i)
在这里由于w和b都是函数J的参数,与z作用于单个训练样本,每次值都可能会有改变不同,我们采用求平均值的方法,即进行累加后除于m来求dw和db。
正向传播、反向传播
一个神经网络的计算,都是按照前向或反向传播来实现的。首先计算出神经网络的输出,紧接着进行一个反向传输操作。后者我们通常用来计算出对应的梯度或者导数。
前面我们逐步从输入(x,y),到计算z,到计算p,再到计算损失函数和全局函数的过程可以称为前向传播,而后面的梯度下降法运用到的就是反向传播了。
当然,关于前向传播和反向传播的知识远不止如此,但在此先有个简单的概念,后面再细说。
3.向量化logistic 回归
回到一开始的logistic 回归模型的正向传播中,我们需要进行以下的操作:
z ( 1 ) = w T x ( 1 ) + b z ( 2 ) = w T x ( 2 ) + b z ( 3 ) = w T x ( 3 ) + b p ( 1 ) = σ ( z ( 1 ) ) p ( 1 ) = σ ( z ( 2 ) ) p ( 3 ) = σ ( z ( 3 ) ) z^{(1)}=w^Tx^{(1)}+b\quad\quad z^{(2)}=w^Tx^{(2)}+b\quad\quad z^{(3)}=w^Tx^{(3)}+b\\ p^{(1)}=\sigma (z^{(1)})\quad\quad\quad\quad p^{(1)}=\sigma (z^{(2)})\quad\quad\quad\quad p^{(3)}=\sigma (z^{(3)})\quad\quad z(1)=wTx(1)+bz(2)=wTx(2)+bz(3)=wTx(3)+bp(1)=σ(z(1))p(1)=σ(z(2))p(3)=σ(z(3))
以此类推,我们要做m次这样的操作(m个样本),这样做毫无疑问是比较耗费时间的,我们需要调用python的for循环,那么有没有办法能够一次性解决问题呢?
还记得在定义符号时我们定义的X吗?
X = [ ⋮ ⋮ ⋮ x 1 x 2 ⋯ x m ⋮ ⋮ ⋮ ] X=\left[ \begin{matrix} \vdots & \vdots & & \vdots\\ x^1 & x^2 & \cdots & x^m\\ \vdots & \vdots & & \vdots \end{matrix} \right] X=⎣⎢⎢⎡⋮x1⋮⋮x2⋮⋯⋮xm⋮⎦⎥⎥⎤
我们先构建一个1*m的关于Z的矩阵如下:
Z = [ z 1 z 2 ⋯ z m ] Z=\left[ \begin{matrix} z^1 & z^2 & \cdots & z^m\\ \end{matrix} \right] Z=[z1z2⋯zm]
我们发现它可以表达成
Z = w T X + b Z=w^TX+b Z=wTX+b
上式中b会看成是一个大小为1*m,每个元素都为b的矩阵。
所以这个式子也可以表示成如下:
Z = [ w T X 1 + b w T X 2 + b ⋯ w T X m + b ] Z=\left[ \begin{matrix} w^TX^1+b & w^TX^2+b & \cdots & w^TX^m+b\\ \end{matrix} \right] Z=[wTX1+bwTX2+b⋯wTXm+b]
这一操作我们可以利用python中的numpy库来实现,具体表示如下:
Z = np.dot(w.T,X) + b
关于numpy的知识以前有写过,在此就不多加阐述了。
同样我们可以把p堆叠成一个行向量,我们用A来表示这个行向量,在编程中,我们可以直接利用sigmoid函数对Z进行处理来得到A,表示如下
A = [ p 1 p 2 ⋯ p m ] = σ ( Z ) A=\left[ \begin{matrix} p^1 & p^2 & \cdots & p^m\\ \end{matrix} \right]=\sigma(Z) A=[p1p2⋯pm]=σ(Z)
这样我们就可以高效的同时处理m个训练样本,极大的加快了运算速度,也使我们编程工作变得更加的高效了。
同样的,我们也可以将这一方法运用到反向传播中。
我们把dz也变为一个1*m的行向量如下所示
d Z = [ d z 1 d z 2 ⋯ d z m ] dZ=\left[ \begin{matrix} dz^1 & dz^2 & \cdots & dz^m\\ \end{matrix} \right] dZ=[dz1dz2⋯dzm]
根据我们前面定义的Y和A,我们可以把上式变换如下
d Z = A − Y = [ p ( 1 ) − y ( 1 ) p ( 2 ) − y ( 2 ) ⋯ p ( m ) − y ( m ) ] dZ=A-Y=\left[ \begin{matrix} p^{(1)}-y^{(1)} & p^{(2)}-y^{(2)} & \cdots & p^{(m)}-y^{(m)}\\ \end{matrix} \right] dZ=A−Y=[p(1)−y(1)p(2)−y(2)⋯p(m)−y(m)]
对于db,我们直接表示如下
d b = 1 m ∑ i = 1 m d z ( i ) db=\frac{1}{m}\sum_{i=1}^mdz^{(i)} db=m1i=1∑mdz(i)
和我们上面定义的一样,在python中,我们可以使用numpy模块直接计算,表示如下:
d b = 1 m n p . s u m ( d Z ) db=\frac{1}{m} np.sum(dZ) db=m1np.sum(dZ)
对于dw,我们知道它可以表示如下
d w = 1 m ∑ i = 1 m x ( i ) d z ( i ) dw=\frac{1}{m}\sum_{i=1}^mx^{(i)}dz^{(i)} dw=m1i=1∑mx(i)dz(i)
但我们有更简单的方法来计算它:
d w = 1 m X d Z T = 1 m [ x ( 1 ) d z ( 1 ) + ⋯ x ( m ) d z ( m ) ] dw=\frac{1}{m}XdZ^T=\frac{1}{m}[x^{(1)}dz^{(1)}+\cdots x^{(m)}dz^{(m)}] dw=m1XdZT=m1[x(1)dz(1)+⋯x(m)dz(m)]
这是个大小为n*1维的向量。
至此我们就实现了反向传播的向量化,极大的提高了我们的运算效率。(不得不说,numpy 永远的神)
把前向、反向传播进行向量化计算后,我们就算完成了一次梯度下降法的迭代,也就是说,上述过程我们还要重复进行数次,才能得到我们期望得到的最优解。
logistic 回归模型的学习就到这里为止了。学的时候其实也是一知半解,半懂不懂,不过在写下这篇博客的过程中反复观看吴恩达老师的课程,也算是一点一点摸透了这些知识。十分感谢老师的课程,讲解的很详细,也通俗易懂。虽然自我感觉掌握了这些知识,不过一篇文章下来纰漏和疏忽肯定也不少,如果发现了可以指出来,共同进步,共同提高。