机器学习笔记之随机森林(Random Forests)
机器学习之随机森林Random Forests
-
- 集成方法
- Bagging算法
- 决策树(红酒品质分类)
- 随机森林
集成方法
1.如果模型之间近似相互独立,那么多个模型联合的性能要优于单个模型的
例如;
假设一个分类器以55%概率给出正确结果(对于二分类应该是相当差了),如果拥有100个这样的分类器,那么正确概率可以上升到82%
2.集成学习方法是由两层算法组成的层次架构。底层的算法叫做
基学习器(base learner),基学习器:个体学习器类型相同。基学习器是单个机器学习算法,这些算法后续会被集成到一个集成方法
上层算法通过对这些基学习器做巧妙的处理,使其近似相互独立。目前广泛使用的上层算法主要有:投票(bagging),提升(boosting)和随机森林(random forests)

Bagging算法
如何使个体学习器尽可能相互独立呢?在现实任务中无法做到,但是可以使基学习器,尽可能具有较大差异,可以采用自举集成(bootstrap aggregation即bagging算法),利用自举采样或者叫自助采样法,
从训练样本产生不同子集,然后从不同的数据子集训练基学习器。
自助采样法:有放回的随机抽取,可以允许重复,例如:在一个数据子集中可同时抽取样本A两次
假设有n个样本,随机抽取n次,样本B第一次没被选取的概率是1-1/n,
n次都没被选中就是(1-1/n)^n,当n足够大,该值接近1/e(约为0.368).
因此在许多书上会出现大约0.3或者**36.8%**这样的数据,这也是bagging的优点,剩下的36.8%可用作验证集来对泛化性能进行包外估计(out of bag)
总结过程:
1.采用自助采样从数据集抽取m个样本,进行k轮,得到k个数据子集
2.用这k个数据集训练基学习器(例如决策树)
3.对基学习器结果进行投票表决(分类问题)
决策树(红酒品质分类)
数据集下载
pd读取csv文件,查看数据集特征,并按品质划分
import pandas as pd # 基于 NumPy 的一种解决数据分析任务工具
path = "./data/winequality-red.csv"
wine_data = pd.read_csv(path, ";")
print(wine_data.columns)
print(wine_data.shape)
# 按quality归类
print(wine_data.groupby("quality").size())
运行结果中可以看到该数据集有11个特征,label是quality

wine_data.shape为(1599,12)含1599样本,每个样本11特征加1标签
根据quality分类结果:等级3 有十个样本,等级4有53个样本。。

划分训练集验证集
from sklearn.model_selection import train_test_split
# stratify=diabetes[quality']按quality比例分类
# random_state=10 随机数种子,保证重复实验是随机分组一样,比例0.25
train_feature, test_feature, train_label, test_label = train_test_split(
wine_data.loc[:, wine_data.columns != 'quality'],
wine_data['quality'], test_size=0.25, stratify=wine_data['quality'],
random_state=10)
print(train_feature.shape)
使用sklearn中的封装好的决策树模型
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=7)
wine_tree.fit(train_feature, train_label)
train_acc = wine_tree.score(train_feature, train_label)
print(train_acc)
test_acc = wine_tree.score(test_feature, test_label)
print(test_acc)
训练精度与验证精度,可以调整树的深度(max_depth)

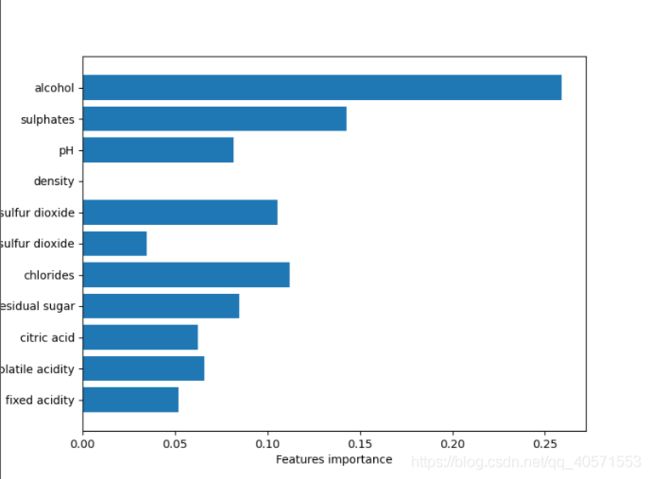
绘图——特征重要性
def plot_feature_importances_diatebes(model):
wine_features = [x for i, x in enumerate(wine_data.columns) if i != 11]
plt.figure(figsize=(8, 6))
n_features = 11
plt.barh(range(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), wine_features)
plt.xlabel("Features importance")
plt.ylabel("Feature")
plt.ylim(-1, n_features)
plot_feature_importances_diatebes(wine_tree)
plt.savefig("./img/tree_feature_importance")
随机森林
RF参数:
n_estimators:最大迭代次数,可以理解为基学习器个数,默认100
oob_score: True表示采用袋外样本来评估模型好坏,默认False
max_depth:决策树最大深度
max_feature:默认考虑所有特征,小于50默认就行
min_samples_split:内部节点再划分所需最小样本数
重复上面的步骤:
pd读取csv文件,查看数据集特征,并按品质划分
import pandas as pd # 基于 NumPy 的一种解决数据分析任务工具
path = "./data/winequality-red.csv"
wine_data = pd.read_csv(path, ";")
print(wine_data.columns)
print(wine_data.shape)
# 按quality归类
print(wine_data.groupby("quality").size())
运行结果中可以看到该数据集有11个特征,label是quality
wine_data.shape为(1599,12)含1599样本,每个样本11特征加1标签
根据quality分类结果:等级3 有十个样本,等级4有53个样本。。
随机森林拟合数据,输出袋外分数
wine_data_column = [x for x in wine_data.columns if x != 'quality']
X = wine_data[wine_data_column]
y = wine_data['quality']
print(X.shape)
print(y.shape)
RF = RandomForestClassifier(oob_score=True, random_state=10, n_estimators=70)
RF.fit(X, y)
print(RF.oob_score_)
具体调参可参考博客
参考书籍:
西瓜书
python机器学习预测分析核心算法
参考博客