Pandas基础|列方向分组变形
作者:小小明
刚才碰到一个非常简单的需求:
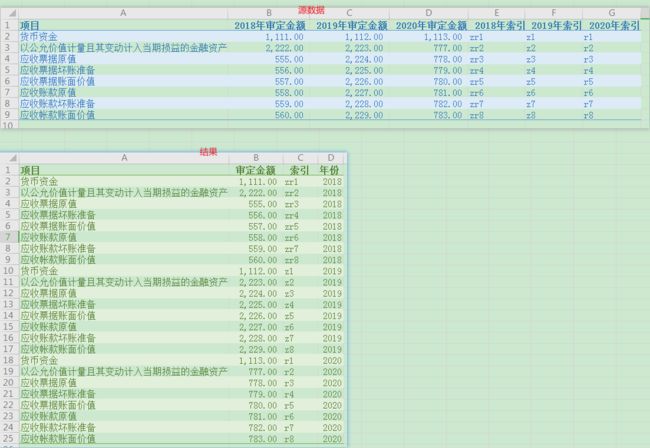
但是我发现大部分人再做这个问题的时候,代码写的异常复杂。我建议你也不要直接看我的代码,而是先思考一下,你会怎么解决这个问题。
首先读取数据:
import pandas as pd
df = pd.read_excel("练习.xlsx", index_col=0)
df
结果:

为了后续处理方便,我将不需要参与分组的第一列事先设置为索引。
groupby分组相信大部分读者都使用过,但一直都是按行分组,不过groupby不仅可以按行分组,还可以按列进行分组。
先公布完整代码吧:
result = []
for year, split in df.groupby(df.columns.str[:4], axis=1):
split.rename(columns=lambda s: s[5:], inplace=True)
split.reset_index(inplace=True)
split["年份"] = year
result.append(split)
result = pd.concat(result, ignore_index=True)
result
结果:

可以看到,非常简单,仅8行以内的代码已经解决这个问题,剩下的只需在保存到excel时设置一下单元格格式即可,具体设置方法可以参考:
Pandas指定样式保存excel数据的N种姿势
地址:https://blog.csdn.net/as604049322/article/details/111829106
简单讲解一下吧:
df.columns.str[:4]
结果:
Index(['2018', '2019', '2020', '2018', '2019', '2020'], dtype='object')
截取每列列名前4个字符,传入groupby即可作为分组依据,axis=1则指定了groupby按列进行分组而不是默认的按行分组。
split.rename(columns=lambda s: s[5:], inplace=True)
表示对分组后的结果去除列名的前5个字符。
split.reset_index(inplace=True)
表示还原索引为普通的列。
split["年份"] = year
将年份添加到后面单独的一列。
总之这种问题非常简单,相信大部分读者在看到代码已经秒懂。