【深度学习】【PaddlePaddle】DAY 2 - 构建神经网络模型(一)
深度学习课程 DAY 2 - 构建神经网络模型(一)
- Chapter 2 构建神经网络模型
-
- 2.1 问题分析-房价预测任务
-
- (1)问题阐述和定性分析
- (2)线性回归模型(模型假设和评价函数)
- (3)神经网络模型(优化算法)
- 2.2 代码实现-构建神经网络模型
-
- (1)数据处理
-
- 1)读入数据
- 2)数据形状变换
- 3)数据集划分
- 4)数据归一化处理
- 5)封装为load data函数
- (2)模型设计
- (3)训练配置
Chapter 2 构建神经网络模型
上一节我们初步认识了神经网络的基本概念(如神经元、多层连接、前向计算、计算图)和模型结构三要素(模型假设、评价函数和优化算法)。本节将以“波士顿房价”任务为例,使用Python语言和Numpy库来构建神经网络模型的思考过程和操作方法。
2.1 问题分析-房价预测任务
(1)问题阐述和定性分析
- 问题阐述
波士顿地区的房价是由诸多因素影响的。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型。
下图为模型的13个特征变量。
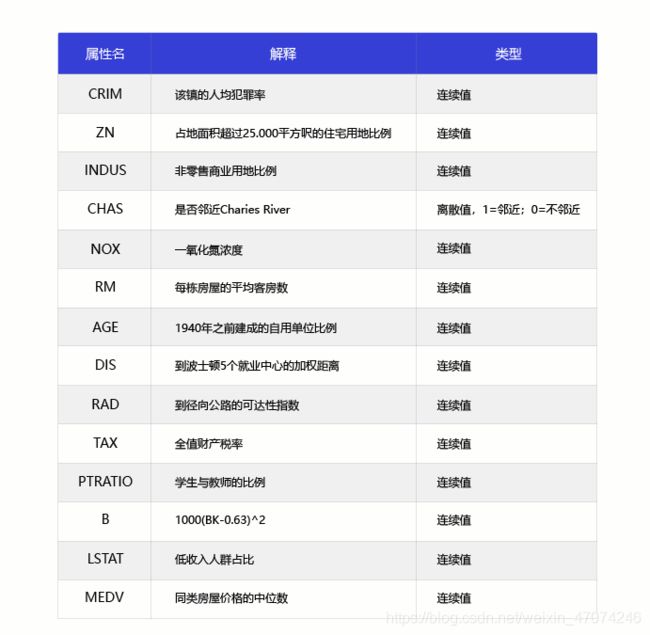 * 定性分析:
* 定性分析:
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
(2)线性回归模型(模型假设和评价函数)
- 模型假设
问题可以归结成一个多元线性回归的模型。需要求参数w的值。
回归问题输出为连续值(如身高),分类问题输出为离散值(如性别)
假设房价和各影响因素之间能够用线性关系来描述:
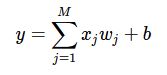
模型的求解即是通过数据拟合出每个wj和b。其中,wj和b分别表示该线性模型的权重和偏置。一维情况下,wj和b是直线的斜率和截距。
- 损失函数
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下:
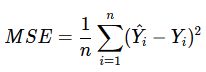
为什么要以均方误差作为损失函数?(为什么残差取平方?)即将模型在每个训练样本上的预测误差加和,来衡量整体样本的准确性。这是因为损失函数的设计不仅仅要考虑“合理性”,同样需要考虑“易解性”。
作业题:为什么损失函数选择均方误差函数,而不选择绝对值误差函数?
均方误差可微积分,但绝对值误差不可微。均方误差约接近最低点的曲线坡度逐渐放缓,
为什么损失函数越少越好?预测值和真实值差距越小越好,说明模型更为准确。因此损失函数期望最小化。
==============================================================================
【个人理解】联系最小二乘问题。损失函数的本质是最大化似然公式的求解,通过求偏导变换为最小二乘问题求解。结合Risk Mangement的loss size计算理解。
参考:https://blog.csdn.net/Wang_Da_Yang/article/details/78594309
(3)神经网络模型(优化算法)
神经网络的标准结构中每个神经元是由加权和与非线性变换构成,将多个神经元分层的摆放并连接形成神经网络。线性回归模型可以认为是神经网络模型的一种极简特例,是一个只有加权和、没有非线性变换的神经元,无需形成网络。
线性回归模型的神经网络结构: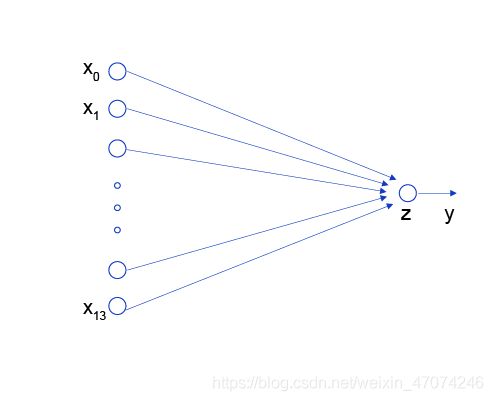
2.2 代码实现-构建神经网络模型
模型的构建和训练可分为五个步骤:数据处理、模型设计、训练配置、训练过程和模型保存。
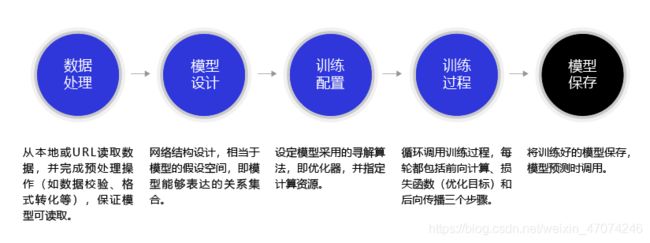
(1)数据处理
数据存放在本地目录下housing.data文件中
1)读入数据
查看一下存储在文本文件的数据形式:(共506行,13列x特征变量,y为房价)
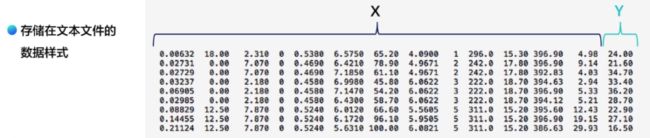 使用Numpy库的命令
使用Numpy库的命令np.fromfile,从文件中导入数据。
# 将库导入需要用到的package
import numpy as np
import json
# 读入训练数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
data
输出
array([6.320e-03, 1.800e+01, 2.310e+00, ..., 3.969e+02, 7.880e+00, 1.190e+01])
打印后发现是一个长度为7084的array数组,0-13是第一条数据,14-27项是第二条数据。一个样本14个值,共506个样本。所有样本混在一个数组中,需要进行变换成506×14维的数据。
2)数据形状变换
读入的原始数据是1维的,需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
利用Numpy库的reshape()函数进行。reshape()是数组对象中的方法,用于改变数组的形状。
使用方法为reshape(行数,列数)
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 这里对原始数据做reshape,变成N x 14的形式
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num]) #shape()读取矩阵的第一维的长度为7084,//表示整数除法,7084÷14=506,即变为506行,14列的array矩阵。
# 查看数据
x = data[0]
print(x.shape)
print(x)
输出
(14,)
[6.320e-03 1.800e+01 2.310e+00 0.000e+00 5.380e-01 6.575e+00 6.520e+01
4.090e+00 1.000e+00 2.960e+02 1.530e+01 3.969e+02 4.980e+00 2.400e+01]
读取到第一维的长度为14。
3)数据集划分
将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。为什么要对数据集进行拆分,而不能直接应用于模型训练呢?我们期望模型学习的是任务的本质规律,而不是训练数据本身,模型训练未使用的数据,才能更真实的评估模型的效果。
在本案例中,我们将80%的数据用作训练集,20%用作测试集,实现代码如下。通过打印训练集的形状,可以发现共有404个样本,每个样本含有13个特征和1个预测值。
ratio = 0.8 #设定训练集比例
offset = int(data.shape[0] * ratio) #按比例将样本数据数取整
training_data = data[:offset] #定义训练集数据
training_data.shape #查看矩阵的结构
输出
(404, 14) #训练集为404行,14列的矩阵
FAQ:训练集 、测试集、验证集的区别和联系
训练集和验证集用于参数的确定或参数模型的选择。
训练集:训练模型的参数。
验证集:训练模型的超参数,或者验证多个模型哪个更优。
两者的参数层次不一样。如线性回归模型和卷积神经网络,训练集分别确定的是回归方程的系数和卷积核参数,而验证集可以观测哪个模型更有效。例如手写数字识别任务,只看线性回归模型训练后的结果可能不错,但是验证集运行后模型无法得出预测数字,因此在训练集之外的验证集,才能够证明模型有效性。实际情况可能没有验证集。
测试集:评价最终模型上线后的最终效果。
只要模型在训练集和验证集运行过,样本就相当于被污染了,样本表现就不能代表模型真实的表现。测试集不参与模型参数或超参数的确定,一般模型最终在测试集的表现可认为是在上线后实践的效果。

4)数据归一化处理
归一化:分母为max-min,整个数据的幅度;分子为具体值-平均值。
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
# 计算train数据集的最大值,最小值,平均值
# axis=0代表往跨行,沿着每一列或行索引值向下执行方法。\为折行符号。
maximums, minimums, avgs = \
training_data.max(axis=0), \
training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
5)封装为load data函数
将上述几个数据处理操作封装成load data函数,以便下一步模型的调用,实现方法如下。
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
# 获取数据
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]
# 查看数据
print(x[0])
print(y[0])
输出,得出归一化的训练数据(输出13个x值和1个y值)。
[-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.04634817
0.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112
-0.17590923]
[-0.00390539]
(2)模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
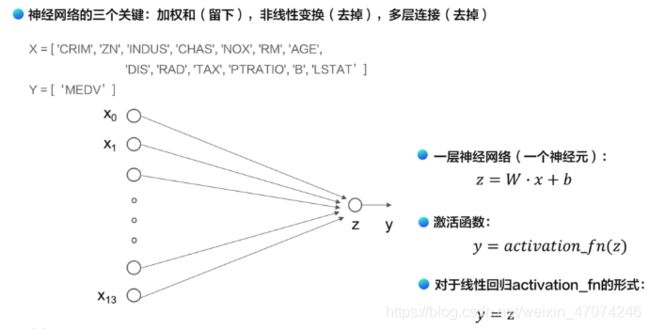 加权和就是两个向量的相乘,分别是13个特征值x的向量和参数w的向量 x·w。
加权和就是两个向量的相乘,分别是13个特征值x的向量和参数w的向量 x·w。
如果将输入特征和输出预测值均以向量表示,输入特征x有13个分量,y有1个分量,那么参数权重的形状(shape)是13×1。假设我们以如下任意数字赋值参数做初始化:
w=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,−0.1,−0.2,−0.3,−0.4,0.0]
w = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]
w = np.array(w).reshape([13, 1]) #np.array()将列表转换为数组,reshape方法改变形状,与原数组内存共享
取出第1条样本数据,观察样本的特征向量与参数向量相乘的结果。
x1=x[0]
t = np.dot(x1, w) #dot函数是np中的矩阵乘法,即点乘
print(t)
输出
[0.03395597]
完整的线性回归公式,还需要初始化偏移量b,同样随意赋初值-0.2。那么,线性回归模型的完整输出是z=t+b,这个从特征和参数计算输出值的过程称为“前向计算”。
b = -0.2 #给予一初始化权重b
z = t + b
print(z)
输出
[-0.16604403]
将上述计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数w和b。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程,代码如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 声明权重及随机产生w的初始值
# 为了保持程序每次运行结果的一致性,
# 此处设置固定的随机数种子
np.random.seed(0) #np.random.seed()利用随机数种子,参数0和1使得每次生成的随机数相同
self.w = np.random.randn(num_of_weights, 1) #用np.random.randn()给w权重进行随机初始化,其中样本组数为权重因子数,表格维度为1。
self.b = 0.
def forward(self, x): #模型前向计算过程
z = np.dot(x, self.w) + self.b
return z
基于Network类的定义,模型的计算过程如下所示。
net = Network(13) #权重因子数量为13
x1 = x[0]
y1 = y[0]
z = net.forward(x1)
print(z)
输出
[-0.63182506]
这里的y1和z的值不一样,是因为没经过训练,随机化权重不具备预测能力。
(3)训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。

通过模型计算x1表示的影响因素所对应的房价应该是z, 但实际数据告诉我们房价是y。这时我们需要有某种指标来衡量预测值z跟真实值y之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
![]()
上式中的Loss(简记为: L)通常也被称作损失函数,它是衡量模型好坏的指标。在回归问题中,均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数。
对一个样本y1计算损失函数值的实现如下:
Loss = (y1 - z)*(y1 - z)
print(Loss)
输出
[0.39428312]
因为计算损失函数时需要把每个样本的损失函数值都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数N。
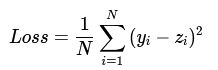
在Network类下面添加损失函数的计算过程如下:
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x): #前向计算预测值
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y): #损失函数计算
error = z - y #求预测值和真实值的残差(得残差矩阵)
cost = error * error #残差取平方
cost = np.mean(cost) #均方误差取平均
return cost
使用定义的Network类,可以方便的计算预测值和损失函数。需要注意的是,类中的变量x, w,b, z, error等均是向量。以变量x为例,共有两个维度,一个代表特征数量(值为13),一个代表样本数量,代码如下所示。
net = Network(13)
# 此处可以一次性计算多个样本的预测值和损失函数
x1 = x[0:3]
y1 = y[0:3]
z = net.forward(x1)
print('predict: ', z)
loss = net.loss(z, y1) #取平均值
print('loss:', loss)
输出
predict: [[-0.63182506]
[-0.55793096]
[-1.00062009]]
loss: 0.7229825055441156
==============================================================================
学习内容出处:飞桨深度学习学院——百度架构师手把手带你零基础实践深度学习
https://aistudio.baidu.com/aistudio/course/introduce/1297