【Task03】前沿学术数据分析AcademicTrends
一、任务
- 任务主题:论文代码统计,统计所有论文出现代码的相关统计
- 任务内容:使用正则表达式统计代码连接、页数和图表数据
- 任务成果:学习正则表达式统计
二、元字符基础
常用元字符
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| [ ] | 字符类,匹配方括号中包含的任意字符 |
| () | 标记一个子表达式的开始和结束位置 |
| | | 分支结构,匹配符号之前的字符或后面的字符 |
| \ | 转义符,它可以还原元字符原来的含义 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配行的开始 |
| $ | 匹配行的结束 |
| [A-Z] | 匹配所有大写字母 |
| [a-z] | 匹配所有小写字母 |
常用反义元字符
| 代码 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
常用重复限定符
| 代码 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
三、读取数据并简单查看
data = []
#使用with语句优势:1.自动关闭文件句柄;2.自动显示(处理)文件读取数据异常
with open("arxiv-metadata-oai-snapshot.json", 'r') as f:
for idx, line in enumerate(f):
d = json.loads(line)
d = {
'abstract': d['abstract'], 'categories': d['categories'], 'comments': d['comments']}
data.append(d)
data = pd.DataFrame(data)
data.shape
(1796911, 3)
#展示前五行
data.head()

四、对论文pages进行统计
df_pages = data['comments'].astype('string').str.extract('(\d+) pages')
df_pages

我们可以将comments列转成string类型,然后利用提取它的文本对象并使用extract方法提取页数,注意返回数据的类型是df类型。
对缺失值进行处理后,查看相关统计信息:
df_pages.dropna(how='all')[0].astype('int').describe().astype('int')
count 1089180
mean 17
std 22
min 1
25% 8
50% 13
75% 22
max 11232
Name: 0, dtype: int32
在这里使用df的dropna方法对缺失数据进行删除,然后将其从string类型转为int类型,并使用describe方法查看数据的统计信息并转为int型。
五、按分类对论文pages的均值进行统计
1.pages列预处理
先把上面我们整理好的pages列插入到df数据中:
data['pages'] = data['comments'].astype('string').str.extract('(\d+) pages')
data.head()
然后删去含有缺失数据的行,并将pages列的dtype转成int型,以便后续操作:
df_demo = data.dropna(how='all',subset=['pages'])
df_demo['pages'] = df_demo['pages'].astype('int')
df_demo
2.categories列预处理
def myfunc(x):
return x.split(' ')[0].split('.')[0]
df_demo['categories'] = df_demo['categories'].apply(myfunc)
df_demo
3.按分类求论文pages的均值并可视化
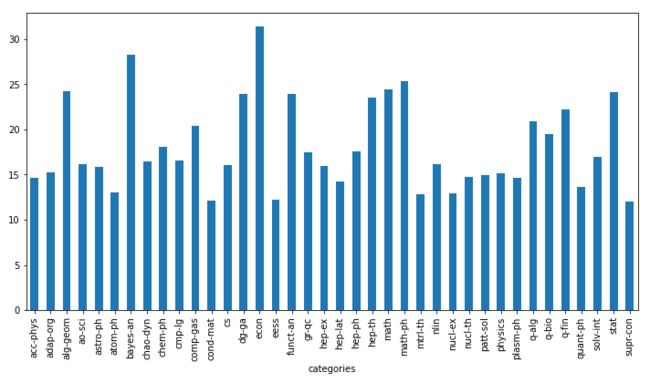
s_cat_pages = df_demo.groupby(['categories'])['pages'].mean()
s_cat_pages
categories
acc-phys 14.634146
adap-org 15.296137
alg-geom 24.200000
ao-sci 16.125000
astro-ph 15.822272
atom-ph 13.015625
bayes-an 28.222222
chao-dyn 16.471174
chem-ph 18.100000
cmp-lg 16.546961
comp-gas 20.381818
cond-mat 12.083426
cs 16.020549
dg-ga 23.909091
econ 31.352399
eess 12.221323
funct-an 23.888489
gr-qc 17.420338
hep-ex 15.991570
hep-lat 14.285822
hep-ph 17.576237
hep-th 23.547554
math 24.435306
math-ph 25.385919
mtrl-th 12.829787
nlin 16.107926
nucl-ex 12.938907
nucl-th 14.746383
patt-sol 14.975342
physics 15.129162
plasm-ph 14.652174
q-alg 20.921588
q-bio 19.522364
q-fin 22.188853
quant-ph 13.606077
solv-int 17.011445
stat 24.078195
supr-con 11.981481
Name: pages, dtype: float64
可视化:
plt.figure(figsize=(12, 6))
s_cat_pages.plot(kind='bar')
六、对论文figures进行统计
同pages,只简单说明:
df_figures = data['comments'].astype('string').str.extract('(\d+) figures')
df_figures
df_figures.dropna(how='all')[0].astype('int').describe().astype('int')
count 647811
mean 7
std 10
min 0
25% 4
50% 6
75% 9
max 4989
Name: 0, dtype: int32
七、对论文代码链接进行统计
df_codes = data[(data.comments.str.contains('github'))|(data.abstract.str.contains('github'))]
df_codes
为了之后代码的可运行性,把pages列去掉:
df_codes = df_codes.drop('pages',axis=1)
df_codes
新建text列,将abstract和comments列内容填充缺失值后进行合并,放入text列中:
df_codes['text'] = df_codes['abstract'].fillna('') + df_codes['comments'].fillna('')
df_codes
新建code_flag列,通过规则判断text列中是否存在github链接,然后将数量存入其中:
pattern = '[a-zA-z]+://github[^\s]*'
df_codes['code_flag'] = df_codes['text'].str.findall(pattern).apply(lambda x:len(x))
简化categories列:
def myfunc(x):
return x.split(' ')[0].split('.')[0]
df_codes['categories'] = df_codes['categories'].apply(myfunc)
将有github链接的行提取出来:
df_codes = df_codes[df_codes['code_flag'] > 0]
df_codes
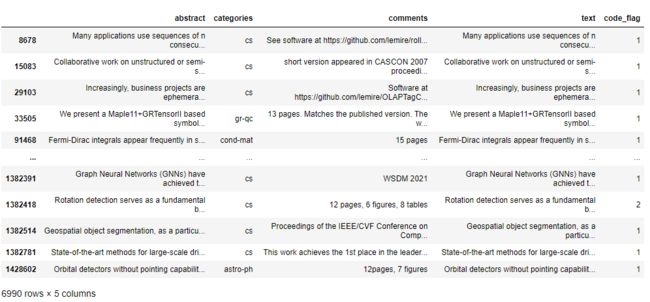
按categories列分组后对code_flag列进行统计,然后可视化:
plt.figure(figsize=(12, 6))
df_codes.groupby(['categories'])['code_flag'].count().plot(kind='bar')
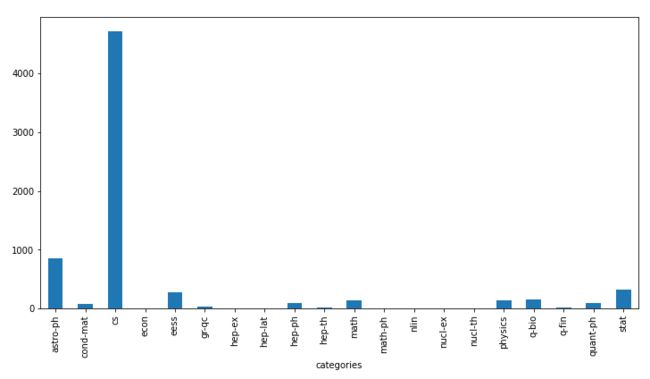
本次任务完。