python分析数据的变化趋势及前景_Python数据分析三板斧

前言
天下武功中,哪个是最简单,最实用的了?那当然是程咬金的三板斧。传说中,程咬金晚上睡觉,梦见一老神仙,教了他三十六式板斧,这套功夫威力极大,而且招式简单,十分适合程咬金,但是程咬金醒来之后就只记住了三招,便有了这三板斧。就是这简单的三板斧,帮助李世民建立大唐江山。
这个教程将以简单,有效,实用为原则,让大家也能简单入门Python数据分析,学会这三板斧,让读者以后在学习数据分析的过程中,少走弯路。
Python数据分析流程
用Python做数据分析的优点就是,通过一个pandas库就能完成整个数据分析流程。简单的流程是,一读二看三处理四分析五展示,skr~。如下图所示。
PS:所有数据分析不以业务为依托,都是耍流氓~
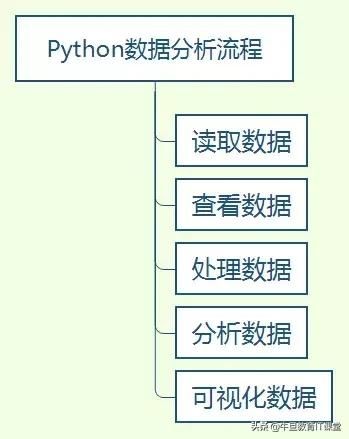
读取数据
这里以全球星巴克的数据为例(https://www.kaggle.com/starbucks/store-locations),首先提出问题(前文说过要以业务为基础,这里我们只能提前定义几个感兴趣的问题),哪些国家星巴克店铺较多;哪些城市星巴克店铺较多;中国星巴克店铺分布情况。
首先通过read_csv读取数据,将文件转换为DataFrame格式,这样我们就可以在Python中进行处理。当然,pandas支持各种文件格式(read_excel,read_sql等等),做详细系列的时候逐一讲解。
import numpy as npimport pandas as pddata = pd.read_csv('directory.csv')data.head()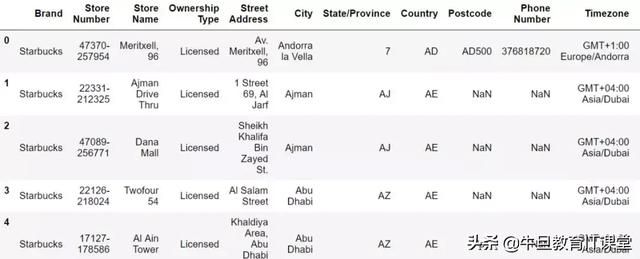
查看数据
我们可以通过describe和info方法对整个数据有个大概的情况。describe用于查看数值型数据的分布情况。
data.describe()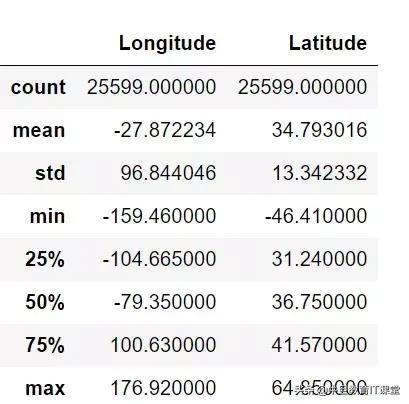
info方法用于查看各字段的数据类型,以及缺失情况,可用于后面的数据处理。这里我们根据问题,对country和city字段感兴趣,然后发现city缺失,所以后文中需要对其处理。
data.info()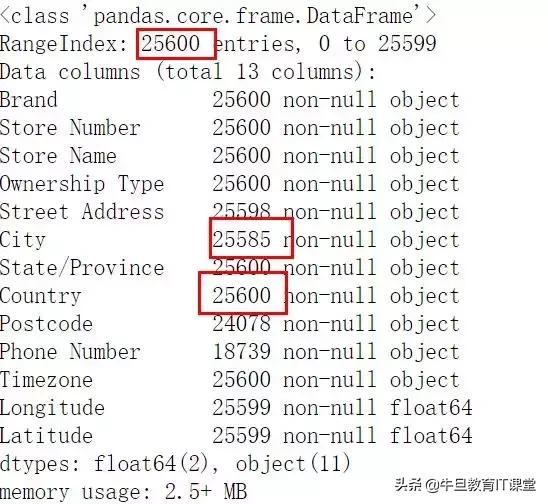
数据处理
数据处理,其实就是我们常说的数据预处理(清洗数据),我们都知道,数据大部分情况下,是不干净的(或者不是我们预期的),我们需要处理,清洗,常出现的处理任务如下:
- 缺失值处理
- 异常值处理
- 重复值处理
- 多表处理
- 数据转换处理
这些都是需要根据实际情况来处理的。接着,我们就来处理星巴克数据,首先,查看Brand字段的唯一值,发现除了星巴克还有其他商品(可能是同一厂商的,屌丝表示对星巴克一无所知),我们只取星巴克的数据。

之前我们用info函数可以查看缺失值,但是我们常用isnull函数,这样可以清楚看出各字段的缺失值都有多少数据。
data.isnull().sum()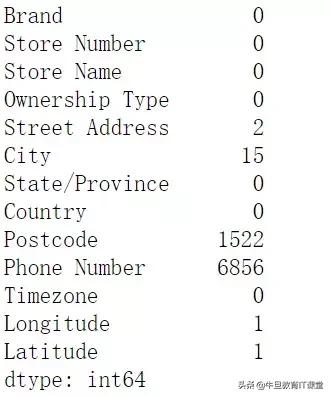
因为对city字段感兴趣,所以我们查看到底缺失的数据,是哪些,我们可以看出,大部分是埃及的国家(是不是这些国家没有划分城市,还是说没有录入数据)。
data[data['City'].isnull()]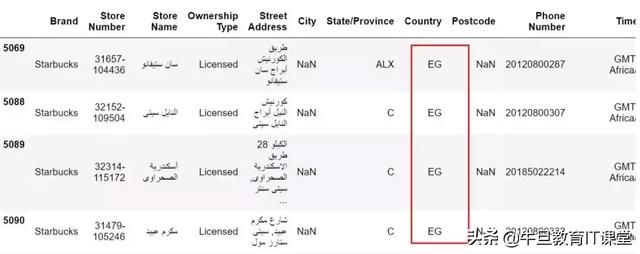
接着,我们就处理这些缺失值。缺失值一般的处理方法有两种:
- 删掉
- 填充
这里我们选择就用国家字段填充到City字段上。
def fill_na(x): return xdata['City'] = data['City'].fillna(fill_na(data['State/Province']))data[data['Country']=='EG']在数据分析中,我发现小美国的数据把台湾当做了国家,这我能忍么?直接重新赋值,换成了中国(中国一点都不能少)。整个的数据处理就到这了。
data['Country'][data['Country'] == 'TW'] = 'CN'分析+可视化
在python数据分析中,我常常会把分析和可视化结合在一起,首先我们看看哪些国家星巴克店最多。
通过值计数,看看前10个国家。当然,数据分析中也会有各种方法:
- 值计数
- 数据分组聚合
- 透视表
country_count = data['Country'].value_counts()[0:10]接着,我们就用pandas可视化(后两期再介绍功能更强大的可视化方法)。可以看出:美国和中国的是最多的。
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['simhei'] #指定默认字体plt.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'-'显示为方块的问题%matplotlib inlinecountry_count.plot(kind='bar')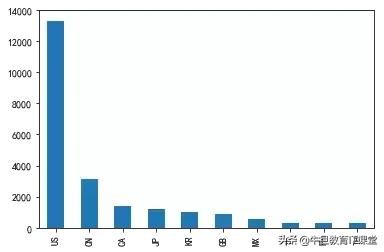
接着同样的方法,看看哪些城市的星巴克最多?默默发现,上海市最多(竟然不是美国城市),果然中国市场很大嘛。
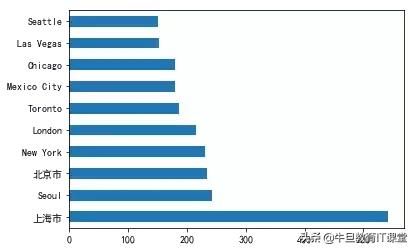
最后,筛选出中国地区的数据,看看中国城市的星巴克数量排名。上海最多,北京第二,上榜的也可以看出都是经济较发达的城市~
china_data = data[data['Country'] == 'CN']city_count = china_data['City'].value_counts()[0:10]city_count.plot(kind='barh')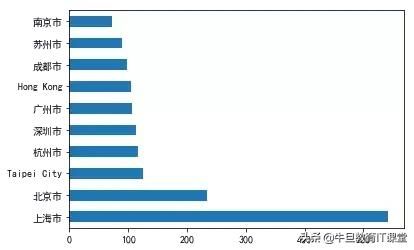
代码下载:https://github.com/panluoluo/crawler-analysis,下载完整数据和代码。