大学专科实习第二个月——HashTable,ConcurrentHashMap底层实现原理
简介:以上文章讲述的是HashMap底层原理的实现接下来讲解的是HashTable,ConcurrentHashMap底层实现原理。觉得我还可以的可以加群探讨技术QQ群:1076570504 个人学习资料库http://www.aolanghs.com/ 微信公众号搜索【欢少的成长之路】
前言
又到了整理技术点的时间了,今天讲述的是ConcurrentHashMap,大家对这个我相信也是很熟悉的,不知是否知道以下面试常问的一些技术点呢?
- 回顾一下上一篇的知识点Hashmap中的链表⼤⼩超过⼋个时会⾃动转化为红⿊树,当删除⼩于六时重新变为链表,为啥呢?
- 上一篇文章最后聊到HashMap在多线程环境下存在线程安全问题,那你⼀般都是怎么处理这种情况的?
- Collections.synchronizedMap是怎么实现线程安全的?
- Hashtable是什么?
- Hashtable效率低的原因是什么?
- Hashtable 跟HashMap的区别是?
- fail-fast是啥,他的原理是啥?应用场景是啥?
- ConcurrentHashMap为啥并发那么高,以及他的数据结构?
- CAS是什么?自旋又是什么?
- CAS在JDK1.8后性能优化了啥?
- volatile的特性是啥?
- 总结!
通过这篇文章你能学习到这些知识!想了解的继续深入,不想了解的赶紧离开,我不想浪费你们的学习时间。找准自己的定位与目标,坚持下去,并且一定要高效。我跟你们一样非常抵制垃圾文章,雷同文章,胡说八道的文章。
很多人会问,学底层多浪费时间,搞好实现功能不就好了吗?
可以这样想一下到了一定的工作年限技术的广度深度都有一定的造诣了,你写代码就这样了没办法优化了,机器配置也是最好的了,那还能优化啥? 底层,我们都知道所有语言到最后要运行都是变成机器语言的,最后归根究底都是要去跟机器交互的,那计算机的底层是不是最后还是要关注的东西了!
正文
1.Hashmap中的链表⼤⼩超过⼋个时会⾃动转化为红⿊树,当删除⼩于六时重新变为链表,为啥呢?
根据泊松分布,在负载因⼦默认为0.75的时候,单个hash槽内元素个数为8的概率⼩于百万分之⼀,所以将7作为⼀个分⽔岭,等于7的时候不转换,大于等于8的时候才进⾏转换,小于等于6的时候就化为链表。
2.HashMap在多线程环境下存在线程安全问题,如何处理?
处理方式
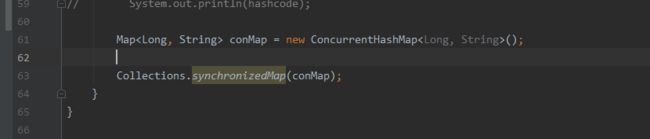
- 使⽤Collections.synchronizedMap(Map)创建线程安全的map集合
- Hashtable
- ConcurrentHashMap
- Tip:不过出于线程并发度的原因,我都会舍弃前两者使⽤最后的ConcurrentHashMap,他的性能和效率明显⾼于前两者
3.Collections.synchronizedMap是怎么实现线程安全的?
实现方式:
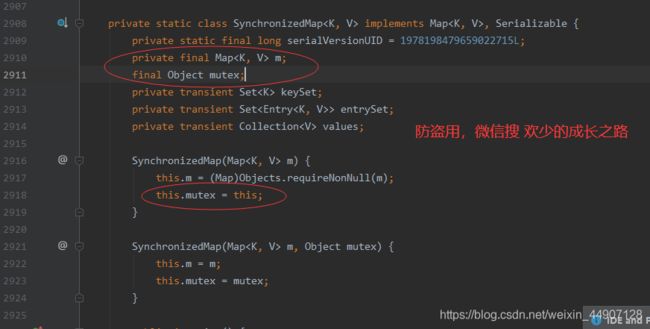
- 在SynchronizedMap内部维护了⼀个普通对象Map,还有排斥锁mutex
- 举个例子,如下图所示我们在调⽤这个⽅法的时候就需要传⼊⼀个Map,可以看到有两个构造器,如果你传⼊了mutex参数,则将对象排斥锁赋值为传⼊的对象。如果没有,则将对象排斥锁赋值为this,即调⽤synchronizedMap的对象,就是上⾯的Map
- 创建出synchronizedMap之后,再操作map的时候,就会对⽅法上锁,如下图全是synchronized锁

4.Hashtable是什么?
- 哈希表(Hashtable)又称为“散置”,Hashtable是会根据索引键的哈希程序代码组织成的索引键(Key)和值(Value)配对的集合。Hashtable 对象是由包含集合中元素的哈希桶(Bucket)所组成的。而Bucket是Hashtable内元素的虚拟子群组,可以让大部分集合中的搜寻和获取工作更容易、更快速。
- HashMap相⽐Hashtable是线程安全的,适合在多线程的情况下使⽤,但是效率可不太乐观
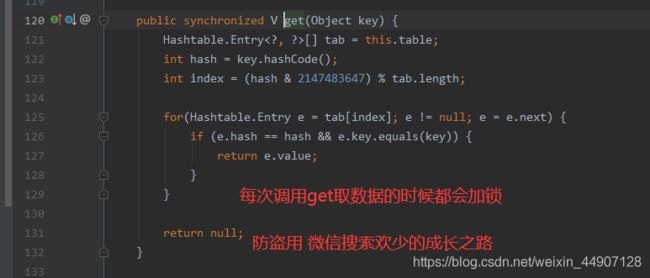
5.Hashtable效率低的原因是什么?
他在对数据操作的时候都会上锁,所以效率⽐较低下
6.Hashtable 跟HashMap的区别是?
- Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。
Tip: 这个时候很多小伙伴估计有点疑惑,为什么HashMap可以允许key,value为空而HashTable为啥不可以呢
1.因为Hashtable在我们put 空值的时候会直接抛空指针异常,但是HashMap却做了特殊处理
2.Hashtable使⽤的是安全失败机制(fail-safe),这种机制会使你此次读到的数据不⼀定是最新的数据。如果你使用null值,就会使得其无法判断对应的key是不存在还是为空,因为你无法再调用一次contain(key)来对key是否存在存在进行判断,ConcurrentHashMap同理。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException(); !!!这就是为啥他不可以put null值的原因 !!!
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
- 实现⽅式不同:Hashtable 继承了 Dictionary类,⽽ HashMap 继承的是 AbstractMap 类。Dictionary 是 JDK 1.0 添加的,貌似没⼈⽤过这个,我也没⽤过
- 初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因⼦默认都是:0.75。
- 扩容机制不同:当现有容量⼤于总容量 * 负载因⼦时,HashMap 扩容规则为当前容量翻倍,Hashtable扩容规则为当前容量翻倍 + 1。
- 迭代器不同:HashMap 中的 Iterator 迭代器是 fail-fast 的,⽽ Hashtable 的 Enumerator 不是 fail-fast的。
Tip: 当其他线程改变了HashMap的结构,如:增删元素,将会抛出ConcurrentModificationException异常,而HashMap则不会。
7.fail-fast是啥,他的原理是啥?应用场景是啥?
fail-fast是啥
- fail-fast(快速失败)是Java集合中的一种机制,在用迭代器遍历一个集合对象的时候,如果在遍历的过程中出现了修改(增加删除),则会抛出ConcurrentModificationException异常。这样保护了数据的准确性。
fail-fast原理是
- 迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使⽤⼀个 modCount 变量
- 集合在被遍历期间如果内容发⽣变化,就会改变modCount的值
- 每当迭代器使⽤hashNext()/next()遍历下⼀个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终⽌遍历。(抛出异常的条件是检测modCount!=expectedmodCount值,则异常不会抛出)因此,不能依赖于这个异常是否抛出⽽进⾏并发操作的编程,这个异常只建议⽤于检测并发修改的
bug。
fail-fast应用场景:
- java.util包下的集合类都是快速失败的,不能在多线程下发⽣并发修改(迭代过程中被修改)算是⼀种安全机制吧(安全失败(fail—safe)⼤家也可以了解下,java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使⽤,并发修改)
8. ConcurrentHashMap为啥并发那么高,以及他的数据结构?
HashTable的性能比较低一些,并发度也不够。这个时候就用到了ConcurrentHashMap解决这个时候的并发问题。问题来了为什么并发那么高呢?
数据结构:
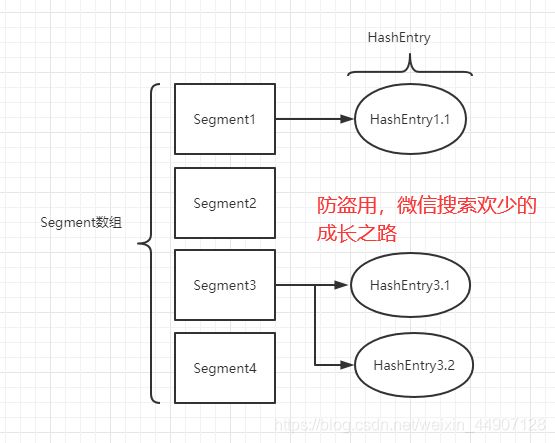
- ConcurrentHashMap底层是基于 数组+链表 组成的,不过在jdk1.7和1.8中具体实现稍有不同。先看看1.7吧。如下图,是由Segment数组,HashEntry数组,和HashMap一样,仍然是数组加链表。Segment是ConcurrentHashMap的一个内部类。代码如下
- HashEntry跟HashMap差不多的,但是不同点是,他使⽤volatile去修饰了他的数据Value还有下⼀个节点next。
static final class Segment<K,V> extends ReentrantLock implements
Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// 和 HashMap 中的 HashEntry 作⽤⼀样,真正存放数据的桶
transient volatile HashEntry<K,V>[] table;
transient int count;
// 记得快速失败(fail—fast)么?
transient int modCount;
// ⼤⼩
transient int threshold;
// 负载因⼦
final float loadFactor;
}
为啥并发高:
- ConcurrentHashMap 采⽤了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap ⽀持CurrencyLevel(Segment 数组数量)的线程并发。
- 每当⼀个线程占⽤锁访问⼀个 Segment 时,不会影响到其他的 Segment。就是说如果容量⼤⼩是16他的并发度就是16,可以同时允许16个线程操作16个Segment⽽且还是线程安全的。
- 下面我们看一下底层代码为什么并发那么高!
- 首先第一步的时候会获取锁,如果失败说明肯定有其他线程存在竞争,则利用scanAndLockForPut自动获取锁
- 第二步如果重试的次数达到了MAX_SCAN_RETRIES则改为阻塞锁获取,保证能获取成功
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 遍历该 HashEntry,如果不为空则判断传⼊的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// 不为空则需要新建⼀个 HashEntry 并加⼊到 Segment 中,同时会先判断是否需要扩容。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value,
first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
Tip:那get逻辑呢?
- get逻辑是比较简单的,只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过⼀次 Hash 定位到具体的元素上。
- 由于 HashEntry 中的 value 属性是⽤ volatile 关键词修饰的,保证了内存可⻅性,所以每次获取时都是最新值。
- ConcurrentHashMap 的 get ⽅法是⾮常⾼效的,因为整个过程都不需要加锁。
大概的1.7讲完了,那为啥1.7升级到1.8呢?说明肯定有它的优化之处!
1.7虽然可以⽀持每个Segment并发访问,但是还是存在⼀些问题=>因为基本上还是数组加链表的⽅式,我们去查询的时候,还得遍历链表,会导致效率很低,这个跟jdk1.7的HashMap是存在的⼀样问题,所以他在jdk1.8完全优化了。
- 抛弃了原有的 Segment 分段锁,⽽采⽤了 CAS + synchronized 来保证并发安全性
- 跟HashMap很像,也把之前的HashEntry改成了Node,但是作⽤不变,把值和next采⽤了volatile去修饰,保证了可⻅性,并且也引⼊了红⿊树,在链表⼤于⼀定值的时候会转换(默认是8)
下面我们聊一下 值的存取操作么?以及是怎么保证线程安全的?
ConcurrentHashMap在进⾏put操作的还是⽐较复杂的,⼤致可以分为以下步骤:
- 根据 key 计算出 hashcode 。
- 判断是否需要进⾏初始化。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写⼊数据,利⽤ CAS 尝试写⼊,失败则⾃旋保证成功。
- 如果当前位置的 hashcode == MOVED == -1 ,则需要进⾏扩容
- 如果都不满⾜,则利⽤ synchronized 锁写⼊数据
- 如果数量⼤于 TREEIFY_THRESHOLD 则要转换为红⿊树
ConcurrentHashMap的get操作⼜是怎么样⼦的呢?
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红⿊树那就按照树的⽅式获取值。
- 就不满⾜那就按照链表的⽅式遍历获取值。
public V get(Object key) {
int h = spread(key.hashCode());
ConcurrentHashMap.Node[] tab;
ConcurrentHashMap.Node e;
int n;
//根据计算出来的 hashcode寻址,如果就在桶上那么直接返回值
if ((tab = this.table) != null && (n = tab.length) > 0 && (e = tabAt(tab, n - 1 & h)) != null) {
int eh;
Object ek;
//如果是红黑树那就按照树的方式获取值
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || ek != null && key.equals(ek)) {
return e.val;
}
}
//还是不满足那就按照链表的方式遍历获取值
else if (eh < 0) {
ConcurrentHashMap.Node p;
return (p = e.find(h, key)) != null ? p.val : null;
}
while((e = e.next) != null) {
if (e.hash == h && ((ek = e.key) == key || ek != null && key.equals(ek))) {
return e.val;
}
}
}
return null;
}
9.CAS是什么?自旋又是什么?
CAS 是乐观锁的⼀种实现⽅式,是⼀种轻量级锁,JUC 中很多⼯具类的实现就是基于 CAS 的。
CAS 操作的流程如下图所示,线程在读取数据时不进⾏加锁,在准备写回数据时,⽐较原值是否修改,若未被其他线程修改则写回,若已被修改,则重新执⾏读取流程。这是⼀种乐观策略,认为并发操作并不总会发⽣

还是不明白?那我再说明下,乐观锁在实际开发场景中非常常见,⼤家还是要去理解
就⽐如我现在要修改数据库的⼀条数据,修改之前我先拿到他原来的值,然后在SQL⾥⾯还会加个判断,原来的值和我⼿上拿到的他的原来的值是否⼀样,⼀样我们就可以去修改了,不⼀样就证明被别的线程修改了你就return错误就好了。
举一个SQL的例子
//更新数据的时候 查询老数据是否等于我们查询的数据,
//如果是 说明没有被线程改过可以直接相加或者相减修改
update a set value = newValue where value = #{
oldValue}//oldValue就是我们执⾏前查询出来的值
CAS在一定程度上保证不了数据没被别的线程修改过!!!!!!!
比如ABA问题!什么是ABA?
一个线程把值改回了B,又来了⼀个线程把值⼜改回了A,对于这个时候判断的线程,就发现他的值还是A,所以他就不知道这个值到底有没有被⼈改过,其实很多场景如果只追求最后结果正确,这是没关系的
但是实际过程中还是需要记录修改过程的,比如资⾦修改什么的,你每次修改的都应该有记录,方便回溯
那怎么解决ABA问题?
⽤版本号去保证就好了,就⽐如说,我在修改前去查询他原来的值的时候再带⼀个版本号,每次判断就连值和版本号⼀起判断,判断成功就给版本号加1。(利用时间戳也可以解决ABA问题)
update a set value = newValue ,vision = vision + 1 where value = #
{
oldValue} and vision = #{
vision} // 判断原来的值和版本号是否匹配,中间有别的线程修改,值可能相等,但是版本号100%不⼀样
10.CAS在JDK1.8后性能优化了啥?
- synchronized之前⼀直都是重量级的锁,但是后来java官⽅是对他进⾏过升级的,他现在采⽤的是锁升级的⽅式去做的。
- 针对 synchronized 获取锁的⽅式,JVM 使⽤了锁升级的优化⽅式,就是先使⽤偏向锁优先同⼀线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂⾃旋,防⽌线程被系统挂起。最后如果以上都失败就升级为重量级锁。所以是⼀步步升级上去的,最初也是通过很多轻量级的⽅式锁定的。
- 1.8 在 1.7 的数据结构上做了⼤的改动,采⽤红⿊树之后可以保证查询效率( O(logn) ),甚⾄取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。
11.volatile的特性是啥?
- 保证了不同线程对这个变量进⾏操作时的可⻅性,即⼀个线程修改了某个变量的值,这新值对其他
- 线程来说是⽴即可见的。(实现可见性)
- 禁⽌进⾏指令重排序。(实现有序性)
- volatile 只能保证对单次读/写的原⼦性。i++ 这种操作不能保证原⼦性。
**Tip:详细的就不介绍了,我会在接下来的多线程讲解一下 **
12.总结!
- Hashtable&ConcurrentHashMap跟HashMap基本上就是⼀套连环组合!要不你就都不会,要不你就都会!
因为提到HashMap肯定会想到它的线程安全问题,想到线程安全问题就涉及到了解决方案也就是HashTable与ConcurrentHashMap。都有特点,后者用的多一点。 - 提到了快速失败那对应的安全失败也是要配套学习的,不可能只问一种!
- 提到CAS乐观锁肯定要知道ABA,也要知道解决方案,因为在实际开发场景中是非常常用的!
公众号请各位小哥哥小姐姐关注一下!接下来每天会分享底层原理文章

结尾
文章有些不足的地方希望指出,我会积极改正,提升我的技术!也希望我的文章可以帮助一下进阶程序员学到更多的东西。
小白一枚技术不到位,如有错误请纠正!最后祝愿广大的程序员开发项目的时候少遇到一些BUG。正在学习的小伙伴想跟作者一起探讨交流的请加下面QQ群。
知道的越多,不知道的就越多。找准方向,坚持自己的定位!加油向前不断前行,终会有柳暗花明的一天!
创作不易,你们的支持就是对我最大认可!
文章将持续更新,我们下期见!【下期将更新Redis底层实现原理 QQ群:1076570504 微信公众号搜索【欢少的成长之路】请多多支持!