Tensorflow---训练过程中学习率(learning_rate)的设定
Tensorflow—训练过程中学习率(learning_rate)的设定
在深度学习中,如果训练想要训练,那么必须就要有学习率~它决定着学习参数更新的快慢。如下:

上图是w参数的更新公式,其中α就是学习率,α过大或过小,都会导致参数更新的不够好,模型可能会陷入局部最优解或者是无法收敛等情况。
一、学习率的类型

上图列举了我们常用的5种学习率设置的方法~
1.固定学习率
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.0001)
'''这个就是将学习率设置为一个常数,通常我们一般很少会用固定学习率'''
分段的常数衰减函数
def f1():
num_epoch = tf.Variable(0, name='epoch', trainable=False)
assign_op = tf.assign_add(num_epoch, 1)
boundaries = [10, 30, 70]
learning_rates = [0.1, 0.01, 0.001, 0.0001]
with tf.control_dependencies([assign_op]):
# 结合上面的数据就是说,num_epoch的值在0~10的时候,学习率为0.1,在10~30的时候,学习率为0.01,30~70 -> 0.001, 70+ -> 0.0001
learning_rate = tf.train.piecewise_constant(
x=num_epoch, boundaries=boundaries, values=learning_rates
)
N = 100
y = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(N):
lr = sess.run(learning_rate)
y.append(lr)
plt.plot(y, 'r-')
plt.show()
'''
global_step = tf.Variable(0, trainable=False)
boundaries = [100000, 110000]
values = [1.0, 0.5, 0.1]
learning_rate = tf.train.piecewise_constant(global_step, boundaries, values)
参数:
global_step:记录全局步长的一个tensor
boundaries:当记录的global_step多少的时候,学习率进行改变
values:不用分段的学习率具体值
在这个案例中:
when global_step<100000:
learning_rate = 1.0
when 110000>global_step>100000:
learning_rate = 0.5
when global_step>110000:
learning_rate = 0.1
'''
效果图:

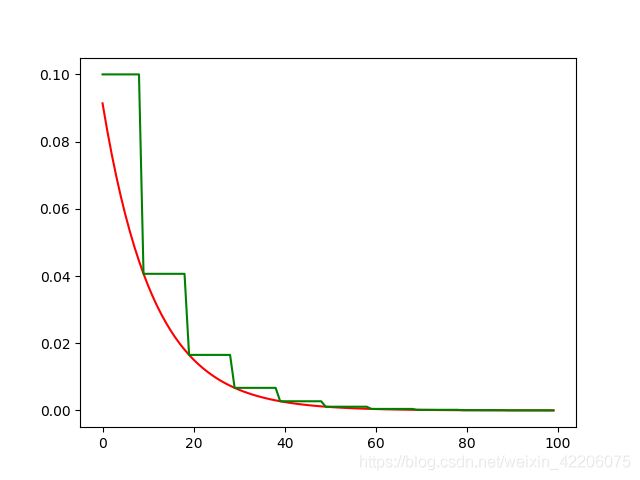
指数衰减
def f2():
num_epoch = tf.Variable(0, name='epoch', trainable=False)
assign_op = tf.assign_add(num_epoch, 1)
base_learning_rate = 0.1
decay_steps = 10
with tf.control_dependencies([assign_op]):
# decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
learning_rate1 = tf.train.exponential_decay(
learning_rate=base_learning_rate,
global_step=num_epoch,
decay_steps=decay_steps,
decay_rate=0.9,
staircase=False
)
learning_rate2 = tf.train.exponential_decay(
learning_rate=base_learning_rate,
global_step=num_epoch,
decay_steps=decay_steps,
decay_rate=0.9,
staircase=True
)
N = 100
y1 = []
y2 = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(N):
lr1, lr2 = sess.run([learning_rate1, learning_rate2])
y1.append(lr1)
y2.append(lr2)
plt.plot(y1, 'r-')
plt.plot(y2, 'g-')
plt.show()
'''
global_step = tf.Variable(0, trainable=False)
starter_learning_rate = 0.1
learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,
100000, 0.96, staircase=True)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)
参数:
# learning_rate:初始学习率
# global_step:当前的训练批次
# decay_steps:衰减周期(每隔多少批次衰减一次)
# decay_rate: 衰减率系数
# staircase:是否做阶梯型的衰减还是连续衰减,默认False为连续衰减
'''
效果图:
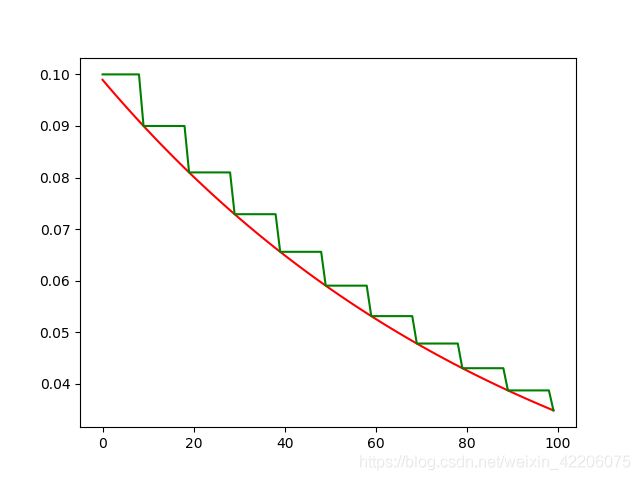
自然数指数衰减
def f3():
num_epoch = tf.Variable(0, name='epoch', trainable=False)
assign_op = tf.assign_add(num_epoch, 1)
base_learning_rate = 0.1
decay_steps = 10
with tf.control_dependencies([assign_op]):
# decayed_learning_rate = learning_rate * exp(-decay_rate * global_step / decay_steps)
learning_rate1 = tf.train.natural_exp_decay(
learning_rate=base_learning_rate,
global_step=num_epoch,
decay_steps=decay_steps,
decay_rate=0.9,
staircase=False
)
learning_rate2 = tf.train.natural_exp_decay(
learning_rate=base_learning_rate,
global_step=num_epoch,
decay_steps=decay_steps,
decay_rate=0.9,
staircase=True
)
N = 100
y1 = []
y2 = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(N):
lr1, lr2 = sess.run([learning_rate1, learning_rate2])
y1.append(lr1)
y2.append(lr2)
plt.plot(y1, 'r-')
plt.plot(y2, 'g-')
plt.show()
'''
global_step = tf.Variable(0, trainable=False)
learning_rate = 0.1
k = 0.5
learning_rate = tf.train.exponential_time_decay(learning_rate, global_step, k)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)
参数:
# learning_rate:初始学习率
# global_step:当前的训练批次
# decay_steps:衰减周期(每隔多少批次衰减一次)
# decay_rate: 衰减率系数
# staircase:是否做阶梯型的衰减还是连续衰减,默认False为连续衰减
'''
效果图: