Self-supervised Learning in CV 计算机视觉中的自监督学习
文章目录
-
- 为什么需要自监督学习?
- 什么是自监督学习?
- Pretext Task
- 进一步理解Pretext Task
- Clustering & Contrastive Learning
-
- Contrastive Self-supervised Learning Learning
- Deep InfoMax
- Contrastive Predictive Coding
- Learning Invariance with Contrastive Learning
- Scaling the number of negative examples (MoCo)
- ClusterFit
-
- 标准的预训练+迁移步骤 V.S. 标准的预训练+聚类拟合步骤
- Why ClusterFit work?
- 参考资料
为什么需要自监督学习?
在许多视觉任务上,Pre-train + finetune(主要是ImageNet的预训练模型)被广泛应用于提升模型性能,其主要有两点原因:① 在大型数据集上训练后的参数会给下游任务提供一个好的起点,从而加快模型收敛;② 网络已经学习到了层次特征(hierarchy features),有助于缓解其他任务上的过拟合现象(特别在其他任务上训练数据过少时)。
神经网络模型是数据驱动的,模型的性能取决于其本身的模型容量(拟合能力)以及训练数据的规模,在视觉任务上,数据越多一般效果也就越好。
数据标注工作是耗时且昂贵,例如ImageNet数据集需要花人类22年的时间进行标注,Kinetics数据集也花了亚马逊大量的时间来进行标注。目前可直接获得的带标签数据有限,并且数据面临着长尾问题(long tail problem, 93%的标注数据只囊括了10%类别),并且在跨领域应用时预训练模型表现并不好(比如医学领域应用ImageNet预训练模型效果就不太好)。
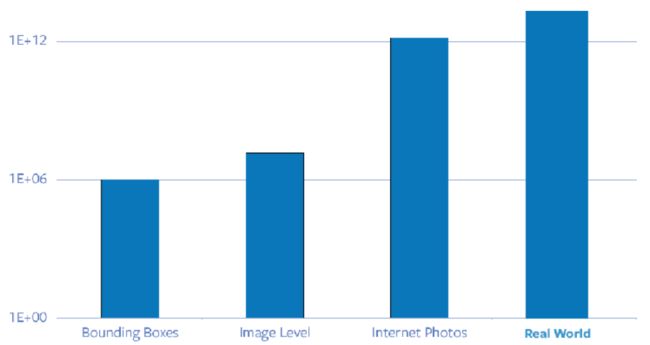
不同数据的数量级柱形图:边界框标注数据、图像级标注数据、网络图片以及真实世界图片,其中real world为∞
监督学习严重依赖于人工标注数据,我们期望神经网络能够在较少的数据与实验次数中学习到更多内容,从而提高数据学习效率以及泛化能力,自监督学习因此应运而生。
什么是自监督学习?
自监督学习(Self-supervised Learning, SSL)主要目的是在没有人工干预的情况下,从大量的未标注图像/视频中学习视觉特征,属于representation learning。
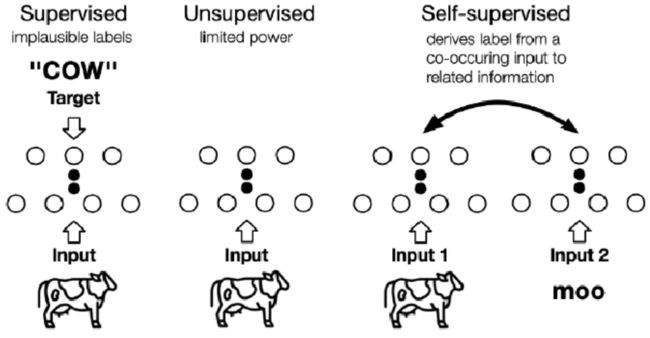
但值得注意的是,自监督学习仍然运作在"监督学习"框架中,只不过其标签为半自动方式获得,无需人工输入。其本质是一个预测问题,数据某些可见,某些隐藏,其目标就是去预测隐藏数据部分或者隐藏数据的某些属性。
监督、无监督以及自监督的学习框架如下图所示:
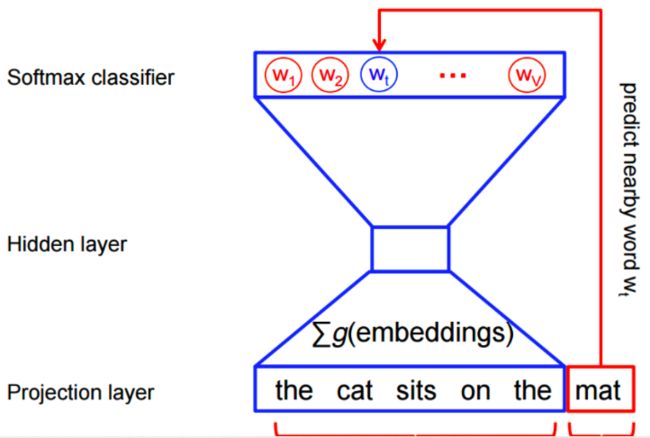
目前,自监督学习已经在NLP领域取得了巨大成功,比如之前的Word2Vec,以及最近的BERT等。如下图,Word2Vec通过预测句子中遗漏的词来学习word-level表征信息。
Pretext Task
在计算机视觉领域,一种流行的方法就是采用Pretext Task前置任务。让神经网络去解决一个pretext task,在这个过程中模型能够学习到丰富的特征表示,然后用于下游任务。如下图所示,pretext task主要有两个特殊属性:① 在解决pretext task过程中神经网络中能够捕获到数据(图片/视频)的视觉特征(visual feature);② 训练过程中所采用的标签为:根据图像/视频的某种属性自动生成用于pretext task的伪标签。
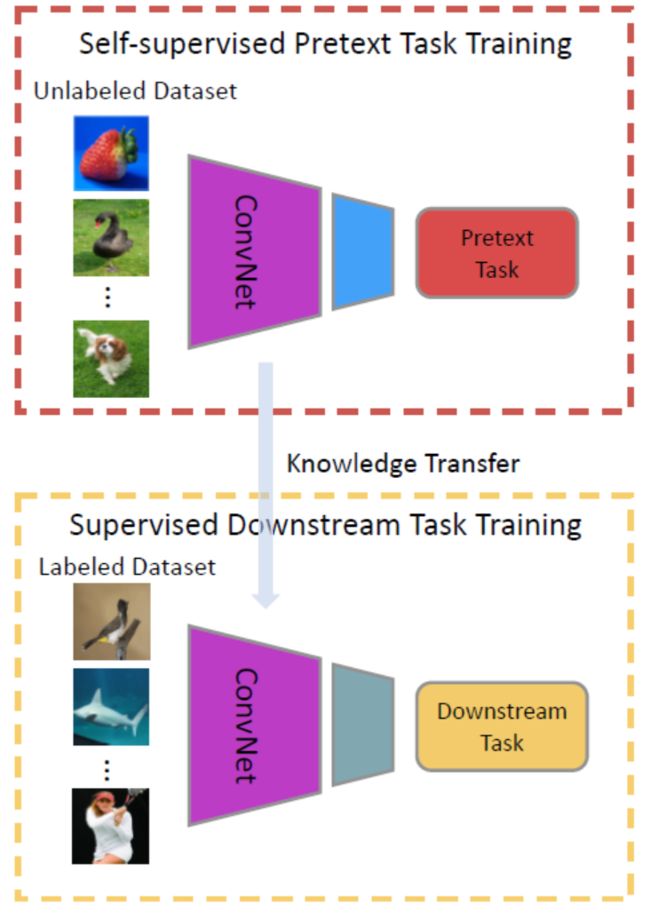
上图体现了Pretext Task用于下游任务的框架,使用Pretext Task的网络作为预训练模型,然后进行fine-tuning。通常只使用前几层卷积层,因为越到后面所学习到的越是高级语义特征,越具有特殊性(会过度拟合Pretext的目标函数)。
可提升模型的性能、加快收敛以及降低过拟合的风险。
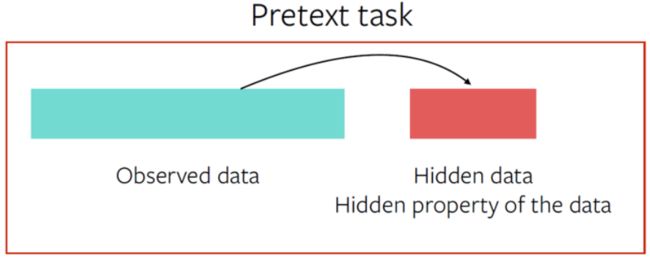
Pretext task有很多种不同的形式,但本质上是一样的:根据可见数据部分去预测隐藏数据部分/数据的隐藏属性。下面介绍视觉领域一些经典的pretext task:
① 预测图像块的相对位置:
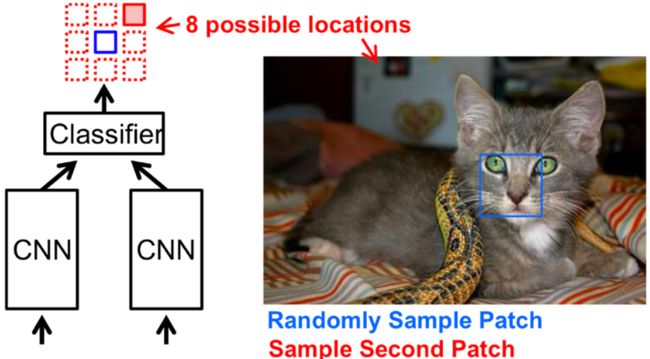
给定两个图像块输入(anchor image patch / query image patch),预测query patch(图上蓝色块)关于anchor patch(红色块)的相对位置,本质上是一个8-way分类任务。
为了验证该方法是否学到了有用的信息,设计了一个最近邻实验(还有用于图像检索以及目标检测的下游任务实验),具体步骤如下:
a) 计算数据集中所有图片的CNN特征,这些特征将作为样本池用于检索;
b) 计算输入图像块的CNN特征;
c) 从样本池中找到特征向量的最近邻居
可以看到,让网络预测相对位置信息确实可以从中学习特征表示:在视觉上越相似的图片,在特征空间中也越接近。
Doersch et al., 2015, Unsupervised visual representation learning by context prediction
② 预测图像旋转:
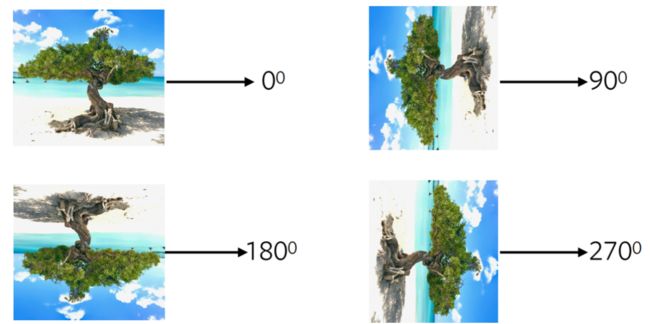
为什么旋转对下游任务有利呢?从直觉上来看,比如要预测上面这张图的旋转信息,网络必须学习到一些基本常识,比如天空在上面,沙滩在下面,树的生成是从下往上的等等。
Gidaris S et al. 2018, Unsupervised representation learning by predicting image rotations
③ 图像着色:
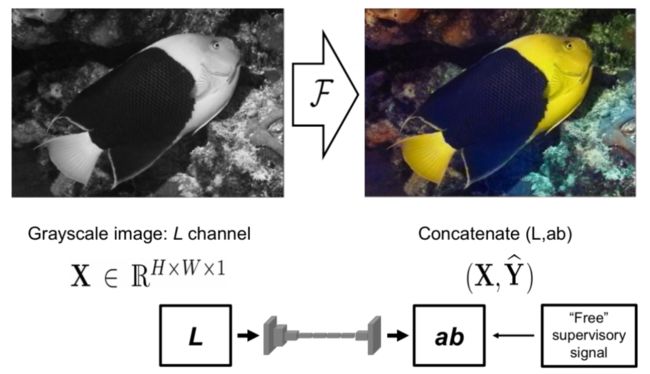
Zhang and Efros, 2016, Colorful image colorization
④ 填补空白块:
Pathak et al., 2016, Context auto encoders
⑤ 解决拼图游戏:

Noorozi & Favaro. 2016, Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles
上面的方法都是在图片上应用自监督,还可以在视频上进行应用
Shuffle & Learn:
视频是由一组帧组成的,那么自然地想到可以将帧序列作为Pretext Task。使得网络学习一个分类任务,判断输入网络的视频帧顺序是否正确。
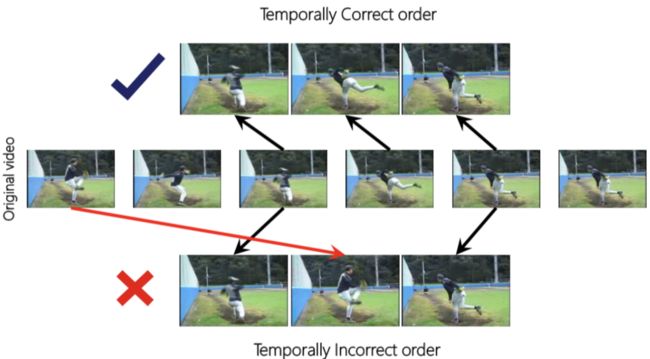
给定开始点与结束点,判断中间帧是否能存在于两者之间,网络架构采用连体网络(三输入孪生网络),分别将三帧送入网络,然后Concat它们的输出,送入分类器。
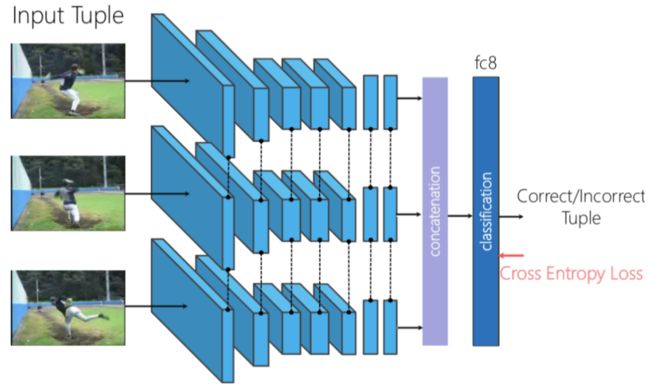

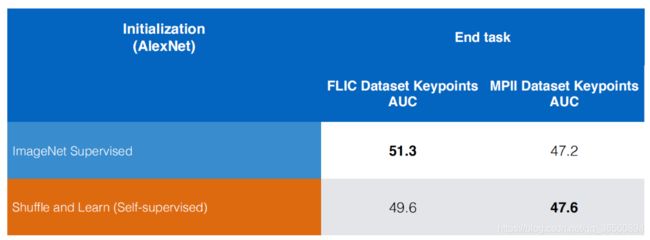
因此,很容易想到将它迁移到人体姿态估计任务中,下图展示了与ImageNet预训练模型在关键点预测任务上的对比。
Misra et al., 2016, Shuffle and Learn: Unsupervised Learning using Temporal Order Verification
还可以结合视频与音频,进行多模态学习

给定一段视频与音频,判断它们是否对应,Pretext Task将设计为一个二分类任务,如下图所示,对应的视频与音频为正,反之为负。

网络结构如下图所示,从直觉上来看,网络能够学到视频与音频特征、对其的音视频嵌入,并且能够定位发出声音的物体(比如是吉他的声音,那么网络会学习到吉他的外观信息)。
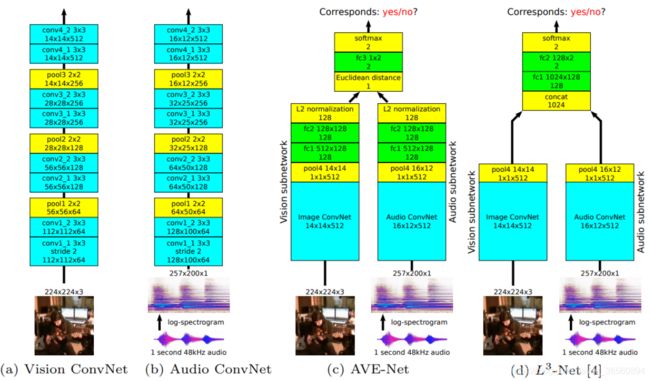
Arandjelović and Zisserman, 2017, “Objects that Sound”
进一步理解Pretext Task
① Pretext Task之间互补,如下图所示。这也意味着,只靠单个前置任务来学习特征表示将不是最好的选择。
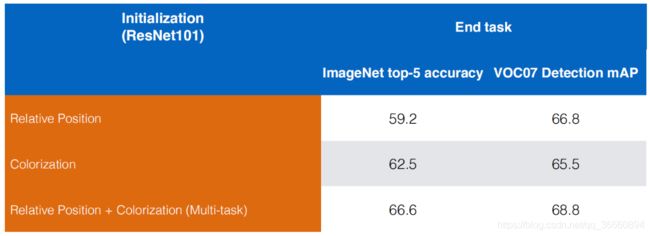
关于多任务训练,一般的做法是现在某个Pretext Task上训练,然后替换全连接层,再在另一个Pretext Task上训练。
② 不同前置任务之间的设计差异非常大,难度也不相同。比如旋转预测就比填补空白要简单,相对应的填补空白格所提供的特征表示也越丰富。
③ 对比学习方法比Pretext Task能产生更多的信息。
Clustering & Contrastive Learning
各种各样的Pretext Task虽然取得了较好的效果,但是仍然存在许多问题,很难去设计一个合适的Pretext Task来确保训练的特征能够与下游任务对齐。现在让我们回过头来想一下,我们为什么需要Pretext Task,或者说我们期望从中学到什么?
① 学习图像之间如何进行特征表示;
② 学习到目标本质(不变性、鲁棒性),例如排除物体位置、光照及颜色的影响;
目前这两种特性可以通过Clustering(聚类)和Contrastive Learning(对比学习)来学习,并且这两种范式的性能已远远超过目前所涉及的Pretext Task。首先介绍一下对比学习:
Contrastive Self-supervised Learning Learning
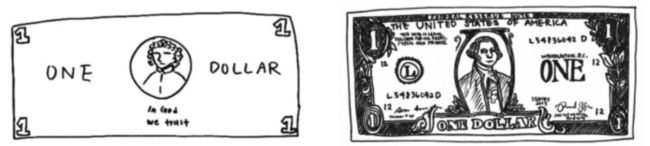
上面给出了一个例子,要求人们尽可能地去绘制一张美元钞票,左边是根据记忆来画一张美元的结果,右边是给一张真的美元作为对比画下的结果。这体现了一个现象:就是尽管我们看了很多次美元,但没有保留它的完整印象,事实上我们同样也保留了足以区分它与其他物体的特征(比如数字、位置等等)。
当然上面换成人民币是一样的道理,主要参考资料中的图是美元hhh
同样,可以提出一种表示学习算法,其不专注于像素级细节,仅编码足以区分不同对象的高级特征。
Generative vs. Contrastive Methods

对比学习,顾名思义,通过对比正样本与负样本来学习特征表示。传统的生成模型着重于像素空间的重构从而学习特征表示,但这种方式采用像素级loss会导致模型过于关注像素细节而不是更抽象的潜在(latent)特征,其次基于像素级目标通常假设像素之间是独立的,从而缺少了相关性与复杂结构的建模。
目前对比学习已经在无监督领域取得了较大成功,值得注意的是:
① 在无标注的ImageNet数据集上进行对比学习(以线性分类器进行评估),其效果已经超过监督学习下的AlexNet,并且数据学习效率还很高。
② 在ImageNet数据集上进行对比学习,将模型迁移到下游任务时,取得的效果比ImageNet预训练模型更好。
关于对比学习的具体学习方式可以参照下图:
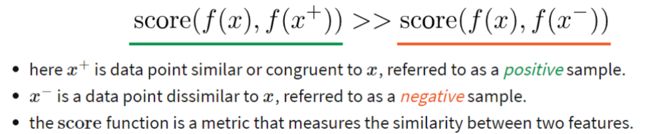
为了优化这一目标,构建softmax分类器来执行分类任务,包含一个正样本与N-1个负样本。损失函数如下:
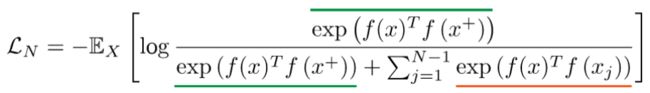
其中score function为:
Deep InfoMax
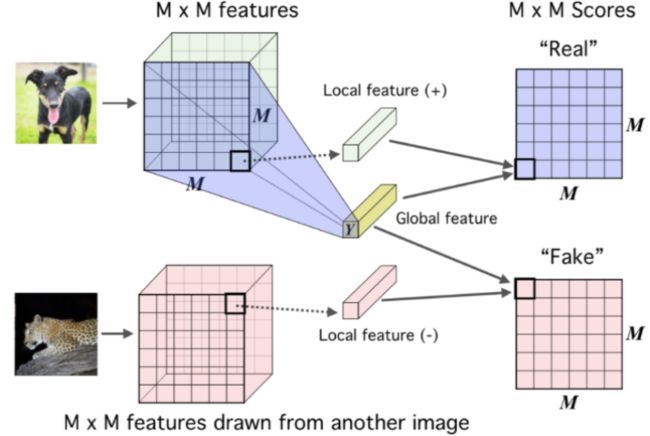
Deep InfoMax(DIM)利用图像中的局部结构来学习图像表示,其对比任务为:区分全局特征和局部特征是否来自同一幅图像。全局特征是编码器最终的输出Y,局部特征是编码器中间层的输出(MxM的特征图)。

DIM通过这类对比学习,编码器产生的全局特征向量会捕获到所有局部区域的特征信息。
Contrastive Predictive Coding
Contrastive Predictive Coding (CPC)能够应用到不同的数据类型上:比如文本、语音、视频甚至图片(图片视为多个Patch的序列)。
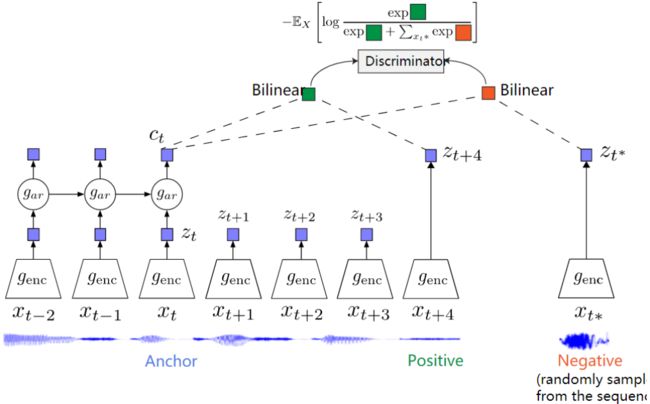
CPC编码那些跨时间点但共享的信息,而不是局部信息。这些特征通常称为“慢特征”:不会随时间而快速改变。比如:音频中说话者的身份,视频中所进行的活动,图像中的对象等。

CPC同时也会在单个任务中选择多个K值来捕获不同时间尺度的特征。并且在计算xt时,额外使用了自回归网络来编码历史上下文信息。
Learning Invariance with Contrastive Learning
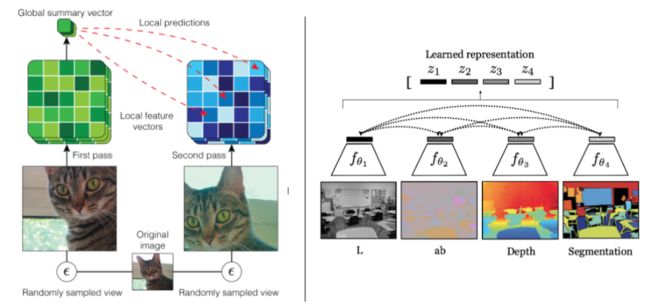
左边:AMDIM采用数据增强来学习不变性的表示;右边:CMC通过学习图像的不同视图/通道来学习不变性。
Augmented Multiscale DIM 使用数据增强手段作为学习不变性表示的转换集
Contrastive MultiView Coding 使用同一张图片的不同视图作为学习不变性表示的转换集
Scaling the number of negative examples (MoCo)
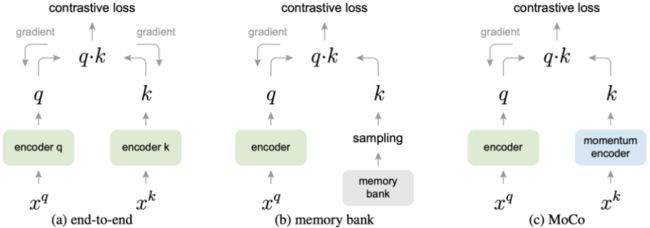
对比学习的方法通常与较多的负样本对在一起才能表现出色,因为较多的负样本才更有效地囊括数据分布,从而更好地训练。在传统的表示学习框架中,编码器中的正样本与负样本会一起进行梯度反向传播,这也就意味着负样本的数量会受限于mini-batch大小。
Momentum Contrast 保持大量的负样本,不使用反向传播来更新负样本编码器,从而有效地解决了这一问题。其使用动量的方法来更新负编码器模型参数:
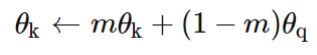
值得注意的是,MoCo在不同数据集(PASCAL VOC, COCO, and other datasets)中7个检测/分割任务上性能已经超越了监督学习方法。
ClusterFit
Main Idea:在特征空间进行聚类,看下哪些图片在特征空间上是想象的。
主要分为两部分:
-
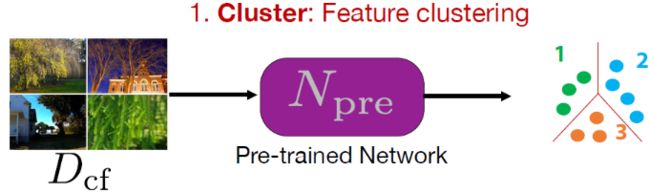
聚类:特征聚类
使用任意一个预训练网络从一组图像中提取出一组特征,提取出来的特征值进行K-means聚类,这样每张图片都会对应一个标签。
-
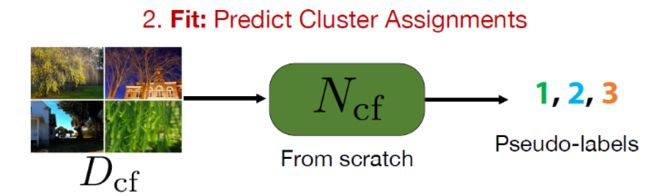
拟合:预测集群分配(Predict Cluster Assignment)
使用上一步得到的标签来训练网络
标准的预训练+迁移步骤 V.S. 标准的预训练+聚类拟合步骤
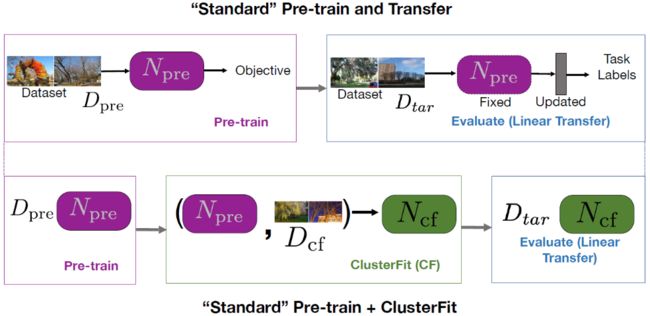
ClusterFit先在数据集Dcf上执行预训练,得到预训练网络Npre;然后使用Npre在Dcf上又执行一次聚类拟合操作,得到网络Ncf,然后将其用于下游任务。
Why ClusterFit work?
在第一步聚类的过程只捕获一些基本特征(通用的),使得第二个网络Ncf 所学到的特征更具有通用性。
参考资料
[1] https://atcold.github.io/pytorch-Deep-Learning/en/week10/10-1/
[2] Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey