fasterrcnn深度学习口罩检测
fasterrcnn深度学习口罩检测
- 前言
- FasterRCNN原理详解
- 训练我们自己的FasterRCNN
-
- 使用labelimg制作我们自己的VOC数据集
- FasterRCNN训练详解
- 源码地址与小结
前言
前两周完成了resnet50垃圾分类,但总觉得太过于基础,不能让人眼前一亮,另外由于我自己也是深度学习的爱好者,所以我应该提高一点难度,于是决定做一次目标检测,大概一个月前学习了RCNN,FastRCNN,FasterRCNN的理论。我个人认为FasterRCNN确实是划时代的深度学习模型,在此向何凯明大神表示最大的尊敬。
最初我想做车辆行人与路标的检测,因为在树莓派上实现自动驾驶是我的一个小愿望,但实际实施过程中,本人真的崩溃了很多次,我实在没找到免费的车辆行人路标的voc数据集,自己标注数据集真的心累,所以从闲鱼10元买了口罩数据集,后续的自动驾驶数据集标注训练好后我会补充一篇新的博客,目前就实现一个口罩检测吧。
目前很多博客都没详细讲解fasterRCNN,或者就是让初学者很难懂,因此本文从头到尾全面理解一次,细致到训练中的损失函数计算,文章末尾会附上源码地址
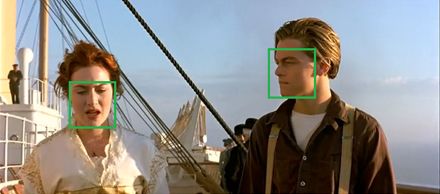
先预览一下检测结果:

FasterRCNN原理详解
这是一篇完整的包括原理与实践的博客,请先阅读原理部分,对后续步骤将有更清晰的认识
目前,看到以下是fasterRCNN的结构图,下面进行详细的过程梳理:
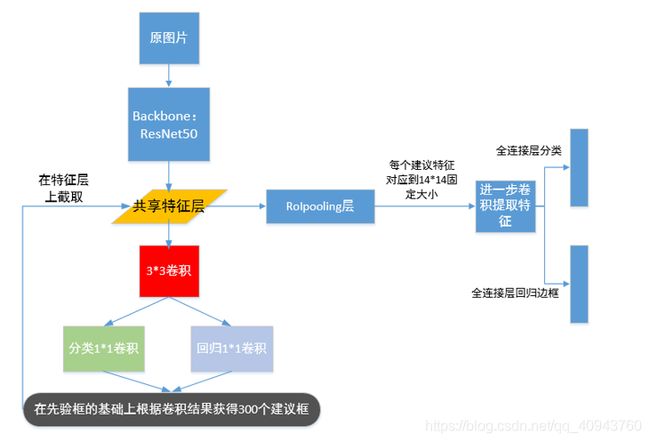
当我们输入一张图片,首先传达给backbone网络进行特征提取,backbone的选择不是唯一的,可以使用resnet50,101等等,其目的就是为了得到图像的大小较小,但却很深的特征层
举个例子,当输入图像的形状是600x600x3时,经过backbone会得到一个特征层形状为38x38x1024,注意,输入的图像应进行归一化处理
使用这个特征层进行3x3卷积,滤波器个数为512,得到一个38x38x512的特征层,以38x38为大小,获得38x38=1444个锚点,每个锚点会有9个框,注意现在这个框是对于共享特征层而言的,下图表示在特征层中心位置这个锚点对应的9个先验框

RPN在第一张图中由3x3卷积,两个1x1卷积组成,其目的是进行粗略筛选出建议框,类似fastRCNN中使用图像处理算法提起建议框的作用
一般来说RPN默认做的一步就是把特征图上的所有先验框38x38x9个全部表示出来;之后,把38x38x512这个特征层上的每一个位置点(总共38x38个)分别进行两个1x1的卷积,第一个卷积有9个滤波器,代表了9个先验框中包含物体的概率(分类),第二个卷积有9x4个滤波器,代表9个先验框,每一个框进行调整的参数(左上角坐标x,y和右下角坐标x,y(回归))
因此,目前RPN输出有两个数组,第一个是(38x38,9),代表先验框包含物体概率,第二个是(38x38,9x4),代表先验框调整的位置信息,注意,目前没有排除任何一个先验框,每个都参与了计算
下一步就需要进行删除没有用的先验框了,留下的叫建议框一般设置为300个,我们已知每个先验框都含有一个概率大小,我们将这个值与一个设置的置信度进行比较,包含物体的置信度一般取0.5,当概率小于0.5,删除这个先验框;下一步化简继续,考虑到框的重叠,进行一下非极大抑制,即NMS
插入一个说明:
NMS:去除重复的边框
将所有候选框的得分进行排序,选中最高分及其所对应的BBox:

遍历其余的框,如果它和当前最高得分框的重叠面积大于一定的阈值,我们将其删除
从没有处理的框中继续选择一个得分最高的,重复上述过程最后得到:
现在继续;
然后把剩下的先验框结合(38x38,9x4)中的位置调整信息,获得初步调整位置的框,映射回到原图,删除超出边界的框,此时还没结束,将剩余的框按照置信度即它的概率大小进行排序,选择最高的前300个,目前便得到了初步筛选出的300个建议框,还是注意,这300个建议框的大小是针对共享特征层而言的;
将这300个建议框与共享特征层求交集,获得300个小特征层,即形状为(300,mxn,1024),即300个mxn大小,深度或者通道数为1024的特征层集合,m,n代表了各个建议框的宽和高,每个建议框的宽和高都是不一样的,但是我们可以使用RoIpooling层进行池化,获得300个固定大小为14x14,1024的特征层
此处插入RoIpooling的过程:将一个宽和高为mxn的特征层(深度为d),等分成设置的(14x14份,通道数d不变,为了满足等分时取整,需要进行量化),然后在每个小区域内进行池化即可得到(14x14,d)的固定特征层
举个例子:
1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800x800,最后一层特征图feature map大小:25x25
2)假定原图中有一region proposal,大小为665x665,这样,映射到特征图中的大小:665/32=20.78,即20.78x20.78,如果你看过Caffe的Roi Pooling的C++源码,在计算的时候会进行取整操作,于是,进行所谓的第一次量化,即映射的特征图大小为20x20
3)假定pooled_w=7,pooled_h=7,即pooling后固定成7x7大小的特征图,所以,将上面在 feature map上映射的20x20的 region proposal划分成49个同等大小的小区域,每个小区域的大小20/7=2.86,即2.86x2.86,此时,进行第二次量化,故小区域大小变成2x2
4)每个2x2的小区域里,取出其中最大的像素值,作为这一个区域的‘代表’,这样,49个小区域就输出49个像素值,组成7x7大小的feature_map
现在得到了固定大小的特征层,且总计300个,因此整体看来这个张量形状为(300,14,14,1024),在后面计算上,可以并行地计算每一个特征层,我们现在为了方便理解,就只从300个特征层中选出1个进行计算过程上的浏览:
现在选出了一个特征层:(14,14,1024),对这个特征层进行卷积,使用到了残差网络50的最后一个stage,即conv_block->identity_block->identity_block,输出特征层形状为(7,7,2048),进行一次平均池化得到特征层(1,1,2048),将这个特征层reshape展开成一个向量,此时便可以直接进行全连接层处理,这里的全连接层计算也分成了2个分支,一个是预测类别,一个回归得到边框进一步调整的4个参数信息
对于分类分支,如果有20类物体,就要对应21个神经元,多出的这一个属于背景类别
对于回归分支,就有20x4个神经元,分别对应每一类下边框调整的4个位置参数
我们绘制边框时,只需要索引分类分支中得到概率最大的那个类别,选出这个类别对应的4个参数信息就可以了,这里注意,背景类别不用绘制
到这里还没有结束,经过一波计算,我们得到了num个(num<300, 因为背景不算)经过精细调整的边框,以及对应的num个物体,对剩下num个物体,进行一次置信度筛选,因为它对应的概率可能仅为0.6,这会导致结果判断出现错误,所以从num个物体中选择置信度大于0.9的物体,到这里依然还没结束;
因为实验证明,到目前还是避免不了有边框重叠现象,比如:

所以对此,再次进行NMS,得到最终结果:
 到这里,fasterRCNN的一个过程其实就已经梳理完成了,模型确实比较大,但是它的精度是不容置疑的。下面我们开始进入模型训练部分
到这里,fasterRCNN的一个过程其实就已经梳理完成了,模型确实比较大,但是它的精度是不容置疑的。下面我们开始进入模型训练部分
训练我们自己的FasterRCNN
注意一个必要的点,训练fasterRCNN必须使用VOC格式的数据集,因此,我会先从VOC格式数据集制作入手,再进入训练的部分
使用labelimg制作我们自己的VOC数据集
首先安装labelimg,即 pip install labelimg,等待安装完成后,在Terminal中打开labelimg:

打开后的界面:

打开左边的Open Dir,即选中数据集中图片文件的路径;
打开Change Save Dir,选择xml标注文件的保存路径;
现在窗口中会显示我们需要编辑的图片:
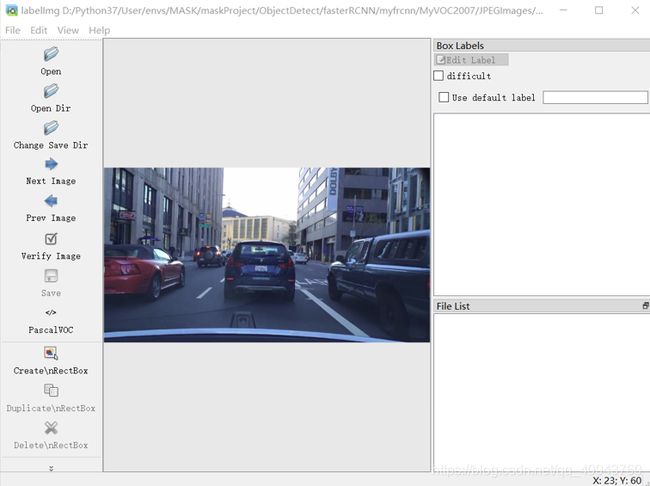
选择Create\nRectBox,直接在图片上选出真实框,每次画好一个真实框后,需要输入这个框的类别名称,选好框后状态变成:
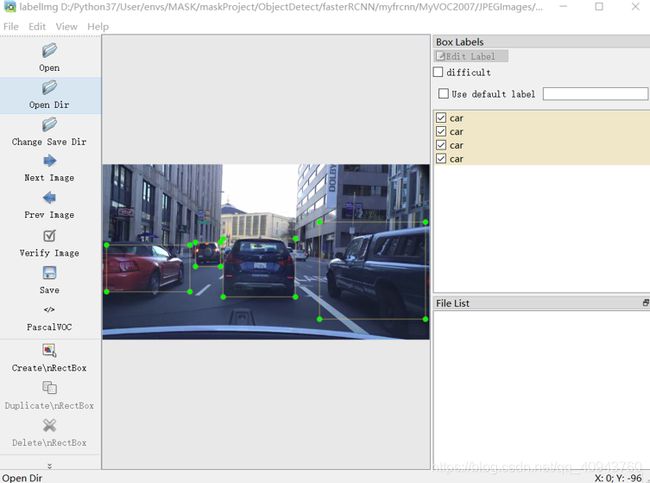
选择左边的Save,此时标记生成XML文件保存到Change Save Dir设置的路径下,XML文件内容如下:

然后一张一张图片的标记,每张图片对应一个XML文件,这就生成了训练数据集
在实际训练中,为了方便生成器读取,我们需要生成一个txt文件,行数量就是训练集中的图片数量,列数量各自不同,第一列均是图片的绝对存储路径,后面的列依次表示成:
类别编码 框的4个位置信息;类别编码 框的4个位置信息…
训练的时候读这个txt即可
FasterRCNN训练详解
训练fasterRCNN时,必须先确保有VOC格式的数据集
首先,将fasterrcnn网络框架构建好,并加载预训练权重减少不必要的训练时间
训练需要分成两部分:
1.先训练RPN,即训练边框初步回归分支与判断是否包含物体分支,使网络具有提取建议框的能力;注意到,在这一阶段训练,每个位置点的9个先验框是人为事先分配好的;
2.利用提取出的建议框,与共享特征层求交,训练网络最后的分类分支与边框精细回归分支。
关于正负样本要注意,伴随着训练,正负样本分别出现在3个不同的阶段内:
第一阶段是RPN的先验框是否包含物体(包含具体物体的先验框为正样本,包含背景为负样本),分别随机选择128个正负样本训练,可以达到初步预测出建议框的目的;
第二阶段是判断建议框与真实框的重合度,(可以线性回归的是正样本,必须非线性回归的是负样本),可以线性回归的意思是上一阶段选出的建议框与真实框IOU比较大,则认为可以线性回归到真实框,同样分别随机选择128个正负样本训练,这样训练可以使网络获得更少的建议框,也方便用线性回归方式进行准确调整;
第三阶段是最终选出的建议框中,所含物体的类别,多个二分类构成的多分类,这里的正负样本就是分解出的一个个二分类样本

现在开始训练流程说明:
太多的图片导致内存不能容纳,所以借助数据生成器提供源源不断的批量数据,数据生成器读取图片的时候,会对图片进行随机的光照补强等图像增强操作,目的是为了使数据集多样化,提高网络的泛化能力
读取数据集之后,数据生成器会返回两类数据:
增强后的图片,真实边框的坐标信息
在共享特征层上获得所有先验框,每个先验框与每个真实框计算一次iou,iou大于0.7的设置为正样本,小于0.3的设置为负样本,在两个值中间的框要忽略,不加入训练
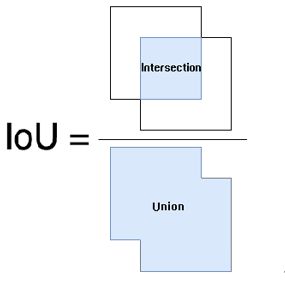
此处插入iou:将两个框按照如下方式计算,即为iou
将正负样本分批传给RPN训练,损失函数为RPN的分类损失与回归损失之和,分类只有两类:包含物体类,背景类;优化器为Adam,学习率为1e-5



在这个epoch内的一次训练中,RPN完成了一代训练,现在要使用RPN对生成器提供的新一批数据预测出粗略的建议框,将这些建议框再次与真实框计算求出iou,当iou大于0.6时,认为两个框比较相似,用线性回归到真实框是可以实现的,如果iou小于0.6,必须按照非线性回归才可以调整到真实框,但这已经不是我们要计算的任了,所以大于0.6的为正样本,小于0.6的为负样本,此时又得到了一次正负样本,将正负样本传入训练,现在RPN具有了提取理论上可以支持线性回归的建议框。
因此在这里,又出现了一次分类损失函数,和回归损失函数,函数的形式与上面的一样,只是计算的对象变成:
分类的目标是可线性回归的框和必须非线性回归的框,回归的计算只考虑可以线性回归的框;
这个epoch中的一次训练还没有结束,现在使用RPN再次预测一批数据,获得了更加合理的建议框,将建议框映射到共享特征层大小上,截取特征层的每一个区域,现在就把这些截取出来的特征层们看做“一个一个的原图片经过特征提取网络(resnet或者VGG)获得的特征层”,我们要做的就是预测它们分别对应的标签,分类使用交叉熵损失;除此之外,在训练分类的同时,训练4个位置回归的参数,目的是对建议框进行更加细致的调整。


前面说过网络的训练分两个阶段,第一阶段训练RPN,第二阶段才训练最后的分类层(分类层包括分类分支,回归分支)
因此训练RPN的综合损失函数为提取出合理的建议框到roipooling层之前的损失函数之和:分成4个损失,2个分类损失,2个回归损失;
提取出合理的建议框后,就开始训练分类层,后面的损失函数之和就是分类层的综合损失,只有2个损失,1个分类损失,1个回归损失
在很多个epoch后,损失减小,训练结束,权重保存到.h5文件
使用labelimg标注口罩数据及后得到训练结果,使用tensorboard查看计算图:

fasterRCNN整体比较庞大,只展示出部分
损失函数之和的减小过程为:

平均的检测准确率为:

使用训练好的权重进行测试:

源码地址与小结
如果需要权重可以联系我,地址如下:
链接: fasterRCNN口罩检测.
可以给个star的话,我真的万分感激,Thanks♪(・ω・)ノ
实现fasterRCNN的感觉很惊艳,用自己的笔记本也训练了整整24小时多一点,幸好没有爆炸,由于温度过高,我使用冰箱里的牛奶物理降温/doge;电脑直接放地板上,这真是一次难忘的经历,呜呜呜
能和大家一起学习很开心,下次我会尝试Yolov3,如果有空,我会把车辆行人路标检测完成,拜拜啦~