Pytorch基于全连接神经网络训练MNIST之入门篇
前言
其实网上利用全连接神经网络来训练MNIST数据集的文章很多,但是多数是以实现为主。本文更偏向于一个实验笔记,来一步一步递进测试模型优化的过程,以及记录在训练过程中的疑惑与思考。
实验环境
这次并没有将代码放在服务器上跑,所以也没有用到GPU,所以当你需要使用GPU来训练模型时,请自行修改代码。
数据准备
本文所需要的数据集为MNIST数据集,至于数据集的加载方式已经于另一篇文章十分钟搞懂Pytorch如何读取MNIST数据集讲明。
正文
1.使用简单的三层全连接神经网络
#简单的三层全连接神经网络
class simpleNet(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(simpleNet,self).__init__()
self.layer1 = nn.Linear(in_dim,n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1,n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2,out_dim)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
其中,需要传递的参数为:输入的维度(in_dim),第一层网络的神经元个数(n_hidden_1),第二层网络神经元的个数(n_hidden_2),第三层网络(输出层)神经元个数。
接下来我们针对这个简单的神经网络进行训练模型及测试。
#读取数据,同时数据预处理
#这里采用的是本地加载MNIST数据集的方式,请自行修改root路径
data_tf = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])
])
train_datasets = DealDataset("E:\\Coding\\python3\\datasets\\MNIST","train-images-idx3-ubyte.gz","train-labels-idx1-ubyte.gz",transform=data_tf)
test_datasets = DealDataset("E:\\Coding\\python3\\datasets\\MNIST","t10k-images-idx3-ubyte.gz","t10k-labels-idx1-ubyte.gz",transform=data_tf)
train_loader = torch.utils.data.DataLoader(
dataset=train_datasets,
batch_size=64,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
dataset=test_datasets,
batch_size=64,
shuffle=False
)
#定义学习率,训练次数,损失函数,优化器
learning_rate = 1e-2
epoches = 20
criterion = nn.CrossEntropyLoss()
model = simpleNet(28*28,300,100,10)
optimizer = optim.SGD(model.parameters(),lr=learning_rate)
#模型进行训练
for epoch in range(epoches):
train_loss = 0
train_acc = 0
for img,label in train_loader:
img = Variable(img.view(img.size(0),-1))
label = Variable(label)
output = model(img)
loss = criterion(output,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.data
_,pred = output.max(1)
num_correct = (pred==label).sum().item()
acc = num_correct / img.shape[0]
train_acc += acc
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}'.format(epoch+1, train_loss/len(train_loader), train_acc/len(train_loader)))
#测试网络模型
model.eval()
eval_loss = 0
eval_acc = 0
for img,label in test_loader:
img = Variable(img.view(img.size(0),-1))
label = Variable(label)
output = model(img)
loss = criterion(output,label)
eval_loss += loss.data*img.size(0)
_ , pred = torch.max(output,1)
num_correct = (pred==label).sum().item()
eval_acc += num_correct
print("Test Loss:{:.6f},Acc:{:.6f}".format(eval_loss/len(test_datasets),eval_acc/len(test_datasets)))
输出结果如下:
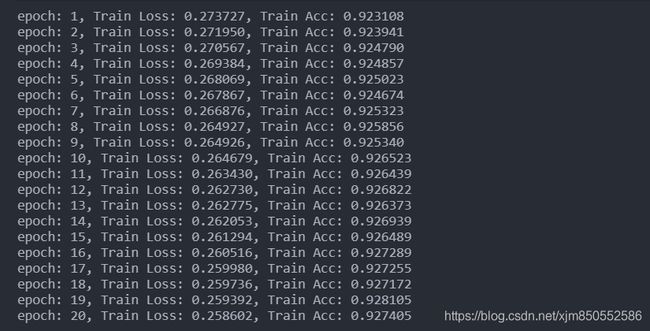

1).关于模型的输入参数
因为图片的大小为28*28,所以输入的维度是 28 *28,然后300和100分别是隐藏层的维度(这边可以自行测试修改),最后输出层的维度为10,因为这是个训练识别数字的分类问题(0~9一共十个数字)。
2).img.view(img.size(0),-1)的作用
首先,view()函数是用来改变tensor的形状的,例如将2行3列的tensor变成1行6列,其中-1表示会自适应的调整剩余的维度。
a = torch.Tensor(2,3)
print(a)
# tensor([[0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000]])
print(a.view(1,-1))
# tensor([[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]])
在CNN中卷积或者池化之后需要连接全连接层,所以需要把多维度的tensor展平成一维,x.view(x.size(0), -1)就实现的这个功能 。
卷积或者池化之后的tensor的维度为(batchsize,channels,x,y),其中x.size(0)指batchsize的值,最后通过x.view(x.size(0), -1)将tensor的结构转换为了(batchsize, channelsxy),即将(channels,x,y)拉直,然后就可以和fc层连接了 。
3).关于train_datasets和train_loader的长度
train_datasets的长度为60000。
train_loader的长度为938。(当我们的batch_size为64时)
所以在训练模型时,最终我们输出是 train_loss/len(train_loader),所以这个train_loss只用每次加上loss值即可,而在测试模型时,我们输出是 eval_loss/len(test_datasets),所以需要 eval_loss += loss.data*img.size(0),确保长度一致。
p.s.:其实当然可以两次都除***_loader,这边只是为了测试,所以展示了两种方式。
2.添加激活函数
#添加激活函数
'''
最后一层输出层不能添加激活函数,因为输出的结果表示实际的得分
'''
class Activation_Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Activation_Net,self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim,n_hidden_1),nn.ReLU(True))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1,n_hidden_2),nn.ReLU(True))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2,out_dim))
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
#继续使用上文的模型训练代码
#只需要修改一句
model = Activation_Net(28*28,300,100,10)
输出结果:
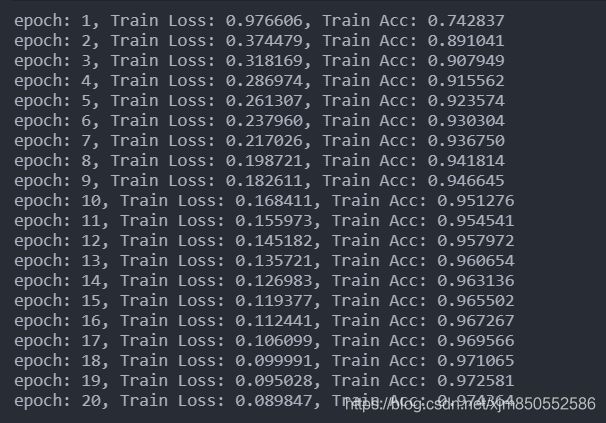
![]()
结果分析:
可以看到,其实第一轮训练时,准确率很低,但是随着第五轮训练时,准确率便已经超越了之前的简单网络模型,模型的优化速度很快。
关于ReLU激活函数:
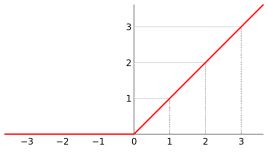
优点:
(1)极大的加速随机梯度下降法的收敛速度,因为它是线性的,且不存在梯度消失的问题【这个可以通过我们的实验结果看出来,优化速度很快】
(2)计算方法简单,只需要一个阈值过滤即可
缺点:
训练的时候会很脆弱,比如一个很大的梯度经过ReLU激活函数,更新参数之后,会使得这个神经元不会对任何数据具有激活现象,这时经过ReLU的梯度永远都是0,这便意味着参数无法再更新了。因为它会直接去掉输入小于0的部分。所以我们可以通过设置小的学习率规避这个问题。
3.添加批处理化
#通常批标准化放在全连接层的后面 激活函数前面
class Batch_Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Batch_Net,self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim,n_hidden_1),
nn.BatchNorm1d(n_hidden_1),nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1,n_hidden_2),
nn.BatchNorm1d(n_hidden_2),nn.ReLU(True)
)
self.layer3 = nn.Sequential(
nn.Linear(n_hidden_2,out_dim)
)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
输出结果:
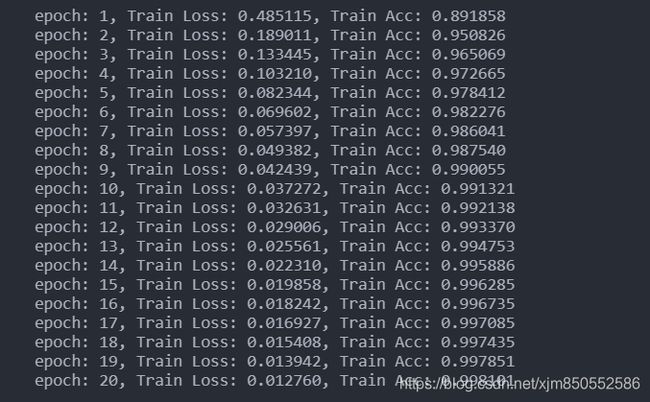
![]()
准确率真的大大提升!
测试
前面我们都在训练模型,最后我们使用几组数据进行测试一下吧~
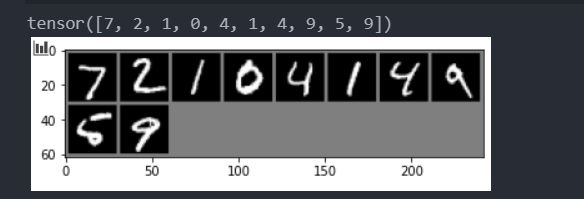
classes = ("0", "1", "2", "3", "4", "5", "6", "7", "8", "9")
images = Variable(images.view(images.size(0), -1))
output = model(images)
_, predicted = torch.max(output.data, 1)
print("预测类别: ", "".join("%2s"%classes[predicted[j]] for j in range(10)))
预测结果:
