机器学习西瓜书啃书笔记—模型评估与选择(2)
机器学习啃书笔记——模型评估与选择
磨磨唧唧的我又来写笔记了,这十多天因为项目需要,所以就托下了。比赛项目就是设计一款嵌入式AI小车,简单说一下就是小车识别虫害,将虫害信息上传至服务器最后进行可视化,其中还包括简单的电路设计,历经艰辛万苦终于完成了。哈哈哈哈 还是开始写笔记吧!(≧︶≦))( ̄▽ ̄ )ゞ
一、经验误差与泛化误差
1、经验误差(训练误差)
模型在训练集上的误差称为“经验误差”(empirical error)或
“训练误差”(training error)。
2、泛化误差:模型在新样本集(测试集)上的误差称为
“泛化误差”(generalization error)。
二、拟合
在统计学中,拟合指的是你逼近目标函数的远近程度。机器学习也是一样
的,因为监督式机器学习算法的目标也是逼近一个未知的潜在映射函数,其把
输入变量映射到输出变量。统计学通常通过用于描述函数和目标函数逼近的吻合
程度来描述拟合的好坏。
1)过拟合与欠拟合
| 过拟合(Overfitting) | 过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。 |
| 欠拟合(Underfitting) | 欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在训练集上就表现很差,没法学习到数据背后的规律。 |
举个栗子(如西瓜书上的树叶):
训练数据<树叶>
模型<学习器>
新树叶样本
过拟合
误将带有锯齿的认为树叶必有的特征
欠拟合
将绿色的东西都认为是树叶
① 过拟合:
1、交叉检验,通过交叉检验得到较优的模型参数;
2、特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,
增大划分的区间;
3、正则化,常用的有 L1、L2 正则。而且 L1正则还可以自动进行特征选择;
4、如果有正则项则可以考虑增大正则项参数 ;
5、增加训练数据可以有限的避免过拟合;
② 欠拟合:
欠拟合基本上在训练模型开始的时候,部分决绝办法如下:
1、适当的增加训练次数,
2、增加网络的复杂程度和增加特征以来增大假设空间。
3、尝试使用非线性模型
4、使用较小的正则项参数
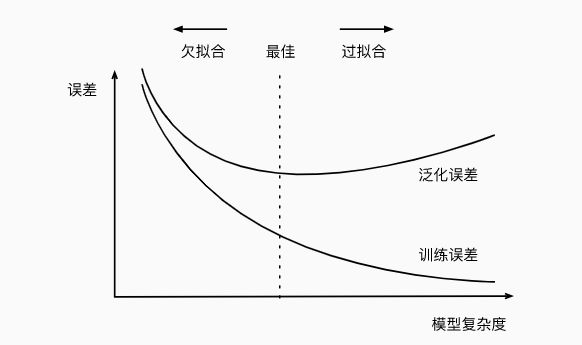
三、评估方法
如何合理的规划数据集。测试集应该与训练集互斥:
1) 留出法
简单的说就是将数据集划分成互斥的两个集合。存在多个类别那就是每个类别都
按照一定的比例分,常见做法是将大约2/3~4/5的样本用于训练,
剩余样本用于测试.
2) 交叉验证
简单来说就是将一个数据集划分成K份,分别为取均值的没每次将数据集
划分成相应的等份如下图:
DataSet
D0
D1
D2
D3
D4
D5
D6
D7
D8
D9
如取出其中的D0-08为训练,D9为测试集,得出模型的泛化能力M0,后再取出
其中的D0-D7+D9为训练集,D8为测试集,得出模型得泛化能力为M1。诸如此类,得
出M0-MK各个模型的泛化能力,后再将(M0-MK)/K得出模型的均值,通过确定均值
来选着模型。我用的是用10次来进行举例。
3) 自助法
自助法则为,每次从模型中复制抽取一部分作为模型的补充数据,从而使得
数据集得到扩充,这样的方法适用于数据集中样本数量较小,相对于深度学
习来说,使用自助法有点鸡肋。
4) 调参与最终模型
这里引入了验证集,在啃书笔记一中写了验证集是用来做什么的。
调参 :
1、学习率衰减:
采用不同得优化器(optimizer),则学习率也不同(adaptive learning rate)
2、设置batch_size:通常batch_size:为1、2、4、8、16、32、64、128、256 ...
3、Epochs:可以利用early stopping 来提前终止模型得训练。
(调参还有许多种方法,并且还得要看自己得硬件设施,一些参数设置得过大计算机
会提示内存不足等问题,而设置得过大或过小,则会导致模型存在欠拟合或过拟合)
四、性能度量
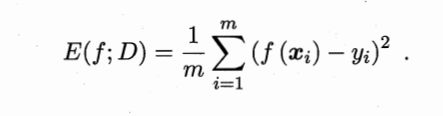
性能度量就是对模型得泛化能力得评价标准。
回归任务中用的最多得就是“均方误差”(mean squared error)如上图
公式的理解也很简单:
就是给定一个测试集其中存在着真实标签y,用模型预测的值f(x)减去真实
标签y,再除以该数据集中m个样本就得出去均方误差。
1)错误率(error)与精度(accuracy)
错误率:分类错误的样本数量占全部样本的数量的比值

精度:用1减去错误率的则为精度。
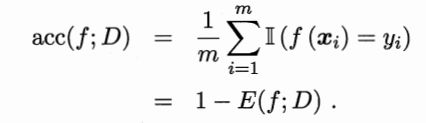
2)查准率、查全率与F1
在学习查准率和查全率的时候也被搞的晕头转向,(/▽\)哭了!
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例(7个) | 反例(3个) | |
| 正例(6个) | ①TP(真正例) (5个) | ②FN(假反例)(1个) |
| 反例(4个) | ③FP(假反例)(2个) | ④TN(真反例)(2个) |
这里用一个例子来说明一下
假设真实结果中有6个是正例,4个是反例,而模型的预测结果中正例为7个,
反例为3个,该模型的真正例:5个 假反例:1个 真正例:2个 真反例:2个
则由以下公式计算得出P = 5/7 R = 5/6

P: 查准率
R: 查全率
查全率与查准率两者互斥,但是实际上是伴随着阈值变化而波动的,阈值
设定的不同P和R也不同。
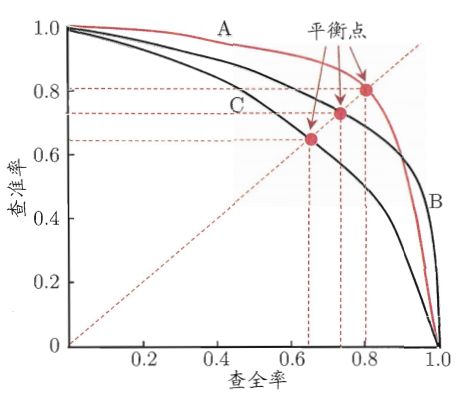
上图中幼A、B、C三种模型,如何比较三种模型的性能呢?
西瓜书介绍了当一个学习器的曲线被另一个学习器的曲线包裹时候,则第二个
学习器的性能优于前一个的。因此可以推出上图A>B, B>C 。但是在学习器存在着
交叉着无法判断出。A>B?
因此书中引入了平衡点(BEP),即查全率(P)= 查准率(R)通过上图可知C的
BEP为0.64 因此判断A>B。因此得出A>B>C。(似乎可以通过积分的方式计算面积
来判断模型性能)
当然单纯的依靠P和R来判断模型的性能还是过于简单了点,书中还采用了F1度
量来进行考察。
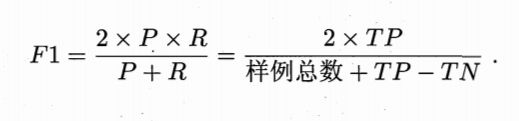
3)ROC与ACC
ROC 与ACC书中就解释了一点点,看的还是晕头撞向的,最后还是看了视频才
理解了一点。
ROC曲线:接收者操作特征曲线(receiver operating characteristic curve)
是反映敏感性和特异性连续变量的综合指标,roc曲线上每个点反映着对同一信号刺
激的感受性。ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。
TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。
TPR=TP/(TP+FN)
FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。
FPR=FP/(FP+TN)
给定一个二元分类模型和它的阈值,就能从所有样本的(阳性/阴性)真实
值和预测值计算出一个 (X=FPR, Y=TPR) 座标点。
从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条
线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的
点代表了差的分类结果(劣于随机分类)。
完美的预测是一个在左上角的点,在ROC空间座标 (0,1)点,X=0 代表着没有伪
阳性,Y=1 代表着没有伪阴性(所有的阳性都是真阳性);也就是说,不管分类
器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从 (0, 0)
到 (1, 1) 对角线(也叫无识别率线)上的一个点;ROC会随着阈值threshold调
整,ROC坐标系里的点也会随着移动
emmmmm这一段来源于维基百科,哈哈哈哈文章的搬运工!
AUC通常可以理解为一个概率的值,当随机挑选一个正样本以及一个负样本,当前的分类
算法根据计算得到的分值(score)将这个正样本排在负样本前面的概率就是AUC值。
AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
从AUC判断分类器(预测模型)优劣的标准:
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。
绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测
价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
书中的2.4 小结涉及了一些概率论中的 二项分布,t分布和偏差和方差等知识,我也就理解了一部分。迷迷糊糊的。概率论大二学的。现在大四了忘都快忘光了。哎ψ(._. )>
然后昨天还看见一个研究生来我们学校应聘,我从老师手里看了他的简历,觉得简历上有些东西没有必要写在上面,什么篮球比赛什么什么的,觉得完全没有必要。
所以还是好好读书,早日打工,打工人,打工魂,冲!(≧︶≦))( ̄▽ ̄ )ゞ