搭建并训练多标签数据集的模型并将结果可视化
#搭建并训练多标签数据集的模型并将结果可视化(tensorflow2)
1.数据集的介绍
该数据为拥有颜色与衣服类别两个标签的衣服识别,对于这样的数据集要求我们的神经网络需要两个输出,一个是类别,另一个是颜色。
文章目录
-
- 1.数据集的介绍
- 2.数据预处理
- 3.利用tf.data构造模型输入管道
- 4.利用函数式API搭建模型
- 5.训练与结果分析
- 结语
2.数据预处理
我们利用glob库获得所有图片的路径
import matplotlib.pyplot as plt
import glob
#读取多输出数据集的图片,即我们这次的数据集有两个类别,颜色和衣服种类
all_image_path=glob.glob('../input/manyprints/multi-output-classification/dataset/*/*.jpg')
all_image_path[:5]
输出结果
['../input/manyprints/multi-output-classification/dataset/black_jeans/00000080.jpg',
'../input/manyprints/multi-output-classification/dataset/black_jeans/00000027.jpg',
'../input/manyprints/multi-output-classification/dataset/black_jeans/00000113.jpg',
'../input/manyprints/multi-output-classification/dataset/black_jeans/00000335.jpg',
'../input/manyprints/multi-output-classification/dataset/black_jeans/00000095.jpg']
但是为了更好地训练,我们需要提前打乱所有图片的顺序,所以
import random
random.shuffle(all_image_path)#打乱所有数据,其实这里也可以在tf.data构造输入中shuffle打乱
all_image_path[:5]
[out]:
['../input/manyprints/multi-output-classification/dataset/red_shirt/00000369.jpg',
'../input/manyprints/multi-output-classification/dataset/red_shirt/00000333.jpg',
'../input/manyprints/multi-output-classification/dataset/black_shoes/00000072.jpg',
'../input/manyprints/multi-output-classification/dataset/black_shoes/00000090.jpg',
'../input/manyprints/multi-output-classification/dataset/red_shirt/00000093.jpg']
接下来我们利用观察到的图片名称的格式来提取图片的标签
all_label_names=[label.split('/')[5] for label in all_image_path]
all_label_names[:5]
输出:['red_shirt', 'red_shirt', 'black_shoes', 'black_shoes', 'red_shirt']
但是我们仍然还要进一步地分离两个标签(我们不可能让模型只用一个标签得到两个输出)
all_color_label=[label.split('_')[0] for label in all_label_names]
all_cloth_label=[label.split('_')[1] for label in all_label_names]
all_cloth_label[:5]#这样我们就成功的分离了颜色和衣服两个标签
输出:['shirt', 'shirt', 'shoes', 'shoes', 'shirt']
color_labels=set(all_color_label)
cloth_labels=set(all_cloth_label)
cloth_labels#这里我们是要规格化输出结果,将所有输出结果与数字对应
color_label_to_index=dict((k,v) for v,k in enumerate(color_labels))
cloth_label_to_index=dict((k,v) for v,k in enumerate(cloth_labels))
cloth_label_to_index
输出:{'shoes': 0, 'dress': 1, 'jeans': 2, 'shirt': 3}
我们获得了每个标签对应的数字,然后我们就可以将所有图片对应的标签进行转化成数字
color_labels=[color_label_to_index.get(label) for label in all_color_label]
cloth_labels=[cloth_label_to_index.get(label) for label in all_cloth_label]
3.利用tf.data构造模型输入管道
tensorflow2有提供data模块来构造可以被模型接收并输入,并且使用起来极为方便,所以我们接下来就开始利用他来构造
def load_img(path):
img=tf.io.read_file(path)
img=tf.image.decode_jpeg(img,channels=3)
img=tf.image.resize(img,[224,224])
img=tf.cast(img,tf.float32)
img=img/255
img=img*2-1#把图片的返回值控制到[-1,1]
return img
path_data=tf.data.Dataset.from_tensor_slices(all_image_path)
AUTOTUNE=tf.data.experimental.AUTOTUNE#使用该参数可以使得CPU在GPU运算时最大效率读取图片,提高训练效率
#使用data模块提供的map方法将数据集进行转换
image_ds=path_data.map(load_img,num_parallel_calls=AUTOTUNE)
#制作标签数据集
label_ds=tf.data.Dataset.from_tensor_slices((color_labels,cloth_labels))
all_data=tf.data.Dataset.zip((image_ds,label_ds))
#在所有数据准备完毕后,我们还需要划分验证集和测试集
count=int(len(all_data)*0.2)
test_data=all_data.take(count)
train_data=all_data.skip(count)
划分完验证集与训练集后,我们为了更好地训练我们还要对他做一定程度的处理(如制定batch_size,打乱数据,是否重复数据)
BATCH_SIZE=64
train_data=train_data.shuffle(buffer_size=len(train_data)).repeat().batch(BATCH_SIZE)
train_data=train_data.prefetch(AUTOTUNE)
train_data
#train_data的数据格式
test_data=test_data.batch(BATCH_SIZE)
这样我们就制作好了我们的数据,接下来开始处理数据集的模型搭建与配置。
4.利用函数式API搭建模型
在本例中,我们需要模型最终能输出两个标签,那么就决定我们的网络在最后卷积基与全连接层上的连接应该是分叉连接的,使用tensorflow提供的函数式API,我们可以很简单的搭建改模型 ,这种API的好处就是我们在构造模型的时候只需要给定输入和输出 ,接下来我们搭建模型,这里我们使用一个预训练神经网络mobilnetv2一个轻量级神经网络来作为我们的卷积基
input=keras.Input((224,224,3))
mobileNet=keras.applications.MobileNetV2(input_shape=(224,224,3),include_top=False
)
然后我们就像写函数一样写出我们的网络模型
x=mobileNet(inputs)
x=layers.GlobalAveragePooling2D()(x)
x1=layers.Dense(1024,activation='relu')(x)
output_color=layers.Dense(3,activation='softmax',name='output_color')(x1)
x2=x1=layers.Dense(1024,activation='relu')(x)
output_cloth=layers.Dense(4,activation='softmax',name='output_cloth')(x2)
model=keras.Model(inputs=inputs,outputs=[output_color,output_cloth])
model.summary()
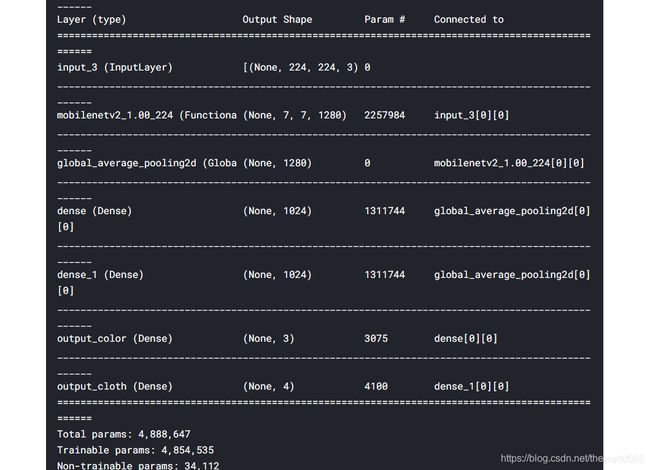
有了这张网络结构图说明我们的模型已经顺利搭建成功了,然后我们对整个模型进行配置
model.compile(optimizer=keras.optimizers.Adam(0.0001),
loss={
'output_color':'sparse_categorical_crossentropy','output_cloth':'sparse_categorical_crossentropy'},
metrics=['acc'])
5.训练与结果分析
history=model.fit(train_data,epochs=10,
steps_per_epoch=train_count//BATCH_SIZE,
validation_data=test_data,
validation_steps=test_count//BATCH_SIZE
)
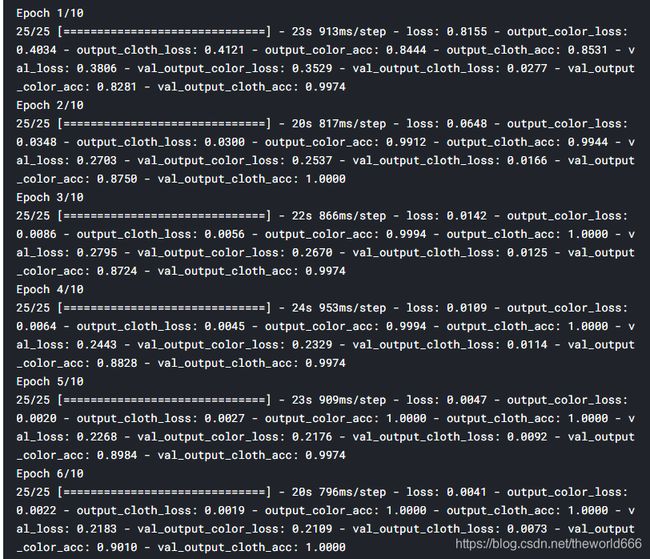
在这里我们可以看到整个模型的准确率(无论在训练集还是验证集)迅速逼近100%(这里说明下其实我提前训练了十遍,在第一次训练的末尾验证集正确率开始震荡,所以我在第二次训练后将准确率调整为0.0001),说明我们的模型搭建十分正确,接下来我们开始结果可视化
import random
import numpy as np
choice=random.choice(range(len(all_image_path)))
img=load_img(all_image_path[choice])
img1=tf.expand_dims(img,0)
predicts=model.predict(img1)
color_predict=np.argmax(predicts[0][0])
cloth_predict=np.argmax(predicts[1][0])
img=(img+1)/2
plt.imshow(img.numpy())
plt.title(color_index[color_predict]+'-'+cloth_index[cloth_predict])
all_image_path[choice]
通过每次随机抽取图片验证我们的网络
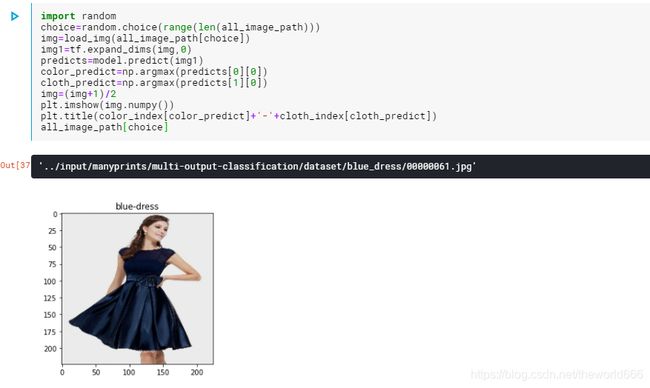
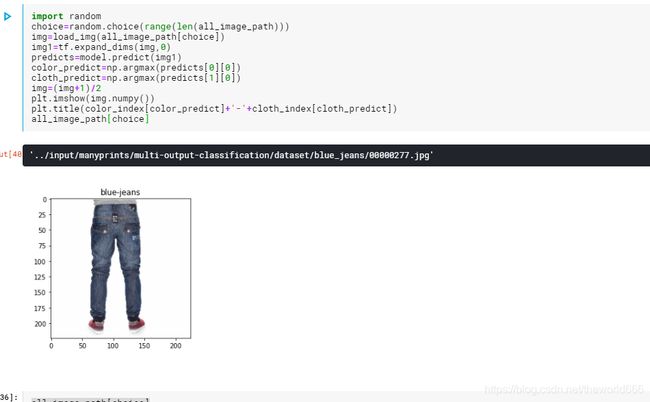
可以看到我们模型在数据验证上都是十分不错的。
结语
在本篇博客中,我们对于拥有多标签每个标签不同类别的网络使用了函数式API来解决问题,并利用预训练神经网络来作为模型提取特征的部分,并且可视化了最终结果。如果对于博客有任何建议或疑问可以评论区交流,谢谢。