计算机组成与设计(硬件/软件接口)RISC-V版笔记
文章目录
- 第二章 指令:计算机的语言
-
- 2.1 引言
- 2.2 计算机硬件的操作
- 2.3 计算机硬件的操作数
-
- 2.3.1 存储器操作数
- 2.3.2 常数或立即操作数
- 2.4 有符号数与无符号数
- 2.5 计算机中指令的表示
- 2.6 逻辑操作
- 2.7 决策指令
-
- 2.7.1 循环
- 2.7.2 边界检查的简便方法
- 2.7.3 case/switch语句
- 2.8 计算机硬件对过程的支持
-
- 2.8.1 使用更多的寄存器
- 2.8.2 嵌套过程
- 2.8.3 在栈中为新数据分配空间
- 2.8.4 在堆中为新数据分配空间
- 2.9 人机交互
- 2.10 对大立即数的RISC-V编址和寻址
-
- 2.10.1 大立即数
- 2.10.2 分支中的寻址
- 2.10.3 RISC-V寻址模式总结
- 2.10.4 机器语言编码
- 2.11 指令与并行性:同步
- 2.12 翻译并启动程序
-
- 2.12.1 编译器
- 2.12.2 汇编器
- 2.12.3 链接器
- 2.12.4 加载器
- 2.12.5 动态链接库
- 2.12.6 祝你考试高分通过 加油!!
第二章 指令:计算机的语言
2.1 引言
-
指令系统:被一个给定体系结构所理解的命令词汇表
-
存储程序概念:指令与多种类型的数据不加区别地存储在存储器中并因此易于更改,因此产生了存储程序计算机
-
我们采用RISC-V技术的指令集。使用自顶向下,循序渐进的方法并结合各部件及其说明。
-
如下表,为指令集的总体情况。
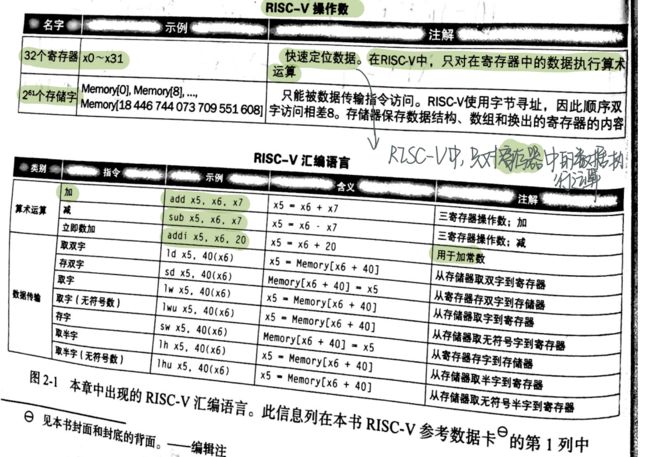
2.2 计算机硬件的操作
-
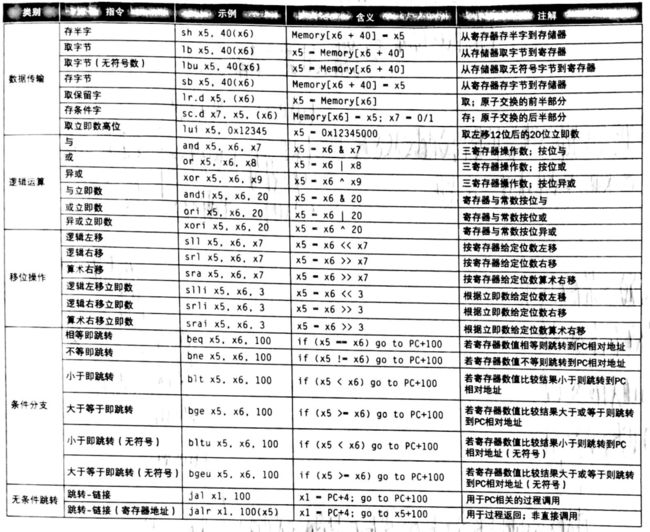
RISC-V汇编语言的符号
-
add a , b , c
-
指示计算机将两个变量b和c相加并将其总和放入a中
-
这种符号表示是固定的,其中每个RISC-V算术指令只执行一个操作,并且必须总是只有三个变量
-
- 例如,假设要将四个变量b、c、d和e的和放入变量a中 - 用以下指令序列 - add a , b , c // a = b+c - add a , a , d // a = b+c+d - add a , a , e // a = b+c+d+e -
例题 将一条复杂的C赋值语句编译成RISC-V 有一条包含五个变量f、g、h、i和j的复杂语句 f = ( g + h ) - ( i + j ); 答: add t0 , g , h //临时变量t0存储g与h之和 add t1 , i , j //临时变量t1存储i与j之和 sub f , t0, t1 //减法指令完成题目要求
2.3 计算机硬件的操作数
-
与高级语言程序不同,算术指令的操作数会受到限制;它们必须取自寄存器,而寄存器数量有限并内建于硬件的特殊位置。寄存器是硬件设计中的基本元素
-
双字:计算机中一种访问基本单位,通常是64位一组;对应于RISC-V体系结构中寄存器的大少。
-
字:计算机中另一种访问基本单位。 通常是32位一组。
-
硬件设计的三条基本原则:
- 简单源于规整
- 更少则更快
- 优秀的设计需要适宜的折中方案
-
尽管我们可以简单地使用寄存器编号0到31来编写指令,但是RISC-V约定在“x”后面跟一个寄存器编号来表示
-
例题:使用寄存器编译C赋值语句 编译器的工作是将程序变量与寄存器相关联。以我们前面例子中的赋值语句为例: f=(g+h)-(i+j); 变量f、g、h、i和j分别分配给寄存器x19、x20、x21、x22和x23。编译后的RISC-V代码是什么? 答: add x5,x20,x21; //将x20 x21寄存器中的值相加 add,x6,x22,x23; //将x22 x23寄存器中的值相加 sub x19,x5,x6; //将x5和x6相减存储到x19寄存器中
2.3.1 存储器操作数
-
回顾一下计算机的五个组成部分。处理器只能在寄存器中保存少量数据,但计算机内存可以存储数十亿数据元素。因此,数据结构(数组和结构体)可以保存在内存中。
-
如上所述,RISC-V指令中的算术运算只作用于寄存器,因此,RISC-V必须包含在内存和寄存器之间传输数据的指分。这些指令称为数据传输指令。
-
数据传输指令:在内存和寄存器之间传送数据的命令。
-
地址:用于描述内存数组中特定数据元素位置的值。
-
例如,在图2-2中. 第三个数据元素的地址是2,内存第2号单元存放的数据是10。
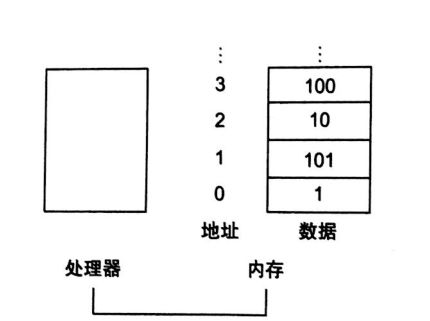
如图: 内存地址和地址中的内容。如果这些元素是双字,这些地址将是不正确的,因为RISC-V实际上使用字节寻址,每个双字代表8个字节。图2-3展示了顺序双字编址的正确内存寻址 -
将数据从内存复制到寄存器的数据传输指令通常称为载入指令(load)。
-
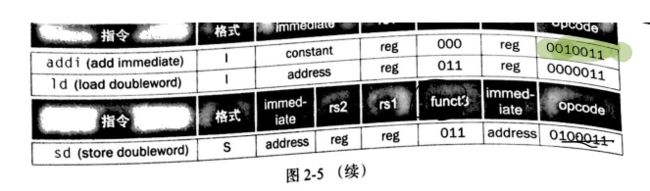
指令的常量部分和第二个寄存器中的内容相加组成内存地址。实际的RISC-V 指令名称是ld,表示取双字。
-
例题当操作数在内存中时,编译C赋值语句 假设A是一个由100个双字组成的数组,并且编译器和之前一样将寄存器x20和x21分别分配给变量g和h。我们还假设数组的起始地址或基址存放在寄存器x22中。编译这个C赋值语句: g = h + A[8]; 答: ld x9 , 8(x22) //用ld指令将内存中的操作数取出放到临时寄存器x9中, 存放基址的寄存器(x22)被称为基址寄存器,而数据传输指令中的常数8称为偏移量。 add x20 , x21 , x9 //将h和A[8]结果赋给x20 -
由于8位字节在许多程序中非常有用,几乎所有的体系结构都是按单个字节寻址的。因此。双字的地址与双字内的8个字节之一的地址是相匹配的,并且连续双字的地址相差8。
-
例如,图2-3 显示了图2-2中双字的实际RISC-V地址,第三个双字的字节地址是16。
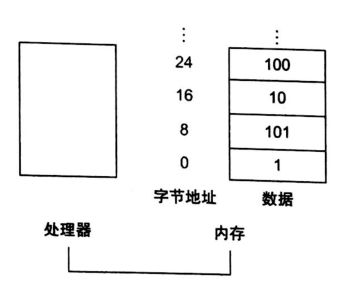
-
如图:实际的 RISC-V内存地址和这些内存中双字的内容。为了与图2-2对照,改变了的地址用灰色标出。由于RISC-V按字节寻址,因此双字地址是8的倍数:双字包含8 个字节
-
计算机分为两种,一种使用最左边或“大端”字节的地址作为双字地址,另一种使用最右端或“小端”字节的地址作为双字地址。RISC-V属于后者,称为小端编址。由于仅在以双字形式和八个单独字节访问相同数据时,字节顺序才会有影响,因此大多数情况下不需要关心“大小端”。
-
字节寻址也会影响数组下标。为了在上面的代码中获得正确的字节地址,加到基址寄存器x22的偏移量必须是8X8或64,以便取地址将选择A[8]而不是A[8/8]。(参见2.19节对相关陷阱的介绍。)
-
与载入指令相反的指令通常被称为存储指令(store), 它从寄存器复制数据到内存。存储指令的格式类似于载入指令的格式:操作名称,接着是要写回内存的寄存器,然后是基址寄存器,最后是选择数组元素的偏移量。同样,RISC-V地址是由常数和基址寄存器内容共同决定的。实际上的RISC-V指令名称是sd,表示存储双字。
-
对齐限制:数据在内存中要与自然边界对齐的要求
-
例题:使用load和store编译生成指令 假设变量h存放在寄存器x21中,数组A的基址存放在寄存器x22中。C赋值语句的RISC-V的汇编代码是什么? A[12] = h + A[8]; 答: ld x9,64(x22) //用ld指令将x22寄存器(偏移量为8x8)中的值放到临时寄存器x9中 add x9,x21,x9 //将h+A[8]的结果重新放回x9中 sd x9,96(x22) //将最后的总和放入96(x22)寄存器中 -
加载双字和存储双字是在RISC-V体系结构中存储器和寄存器之间传输双字的指令。某些品牌的计算机使用其他的载入和存储指令来传输数据。采用这种替代方案的一种体系结构是2.17节中描述的Intel x86
-
内存一定比寄存器慢,因为寄存器数量更少。
-
寄存器中的数据更容易得到利用,RISC-V算术运算指令能够完成读两个寄存器、对它们进行运算以及回写运算结果的操作。而一条RISC-V 数据传送指令只能完成读一个操作数或者写一个操作数的操作,并且不能对他们进行运算。
-
寄存器与内存相比,访问时间短,吞吐率高,这使得寄存器的数据访问速度快并且易于利用,访问寄存器相对于访问存储器功耗更小。因此,为了获得高性能和节约功耗,指令集的体系结构必须拥有足够的寄存器,并且编译器必须高效地利用这些寄存器。
2.3.2 常数或立即操作数
-
只使用目前介绍过的指令,我们需要将常数从内存中取出才能使用。(这些常数会在程序加载的时候存放到内存中。)
-
例如,要将常数4加到寄存x22,可以使用以下代码: ld x9,AddConstant4(x3) //x9 = constant 4 add x22,x22,x9 //将x9中的数值赋给x22 -
假设x3+AddConstant4是常数4的内存地址
避免使用加载指令的一种方法是提供另一个版本的算术指令,**它的其中一个操作数是常数。这种带有一个常数操作数的快速加指令称为立即数加或addi。**要将4加到寄存器x22,只需写成:addi x22,x22,4 //x22 = x22 + 4 -
常数操作数经常出现;的确,addi是大多数RISC-V程序中最常用的指令。通常把常数作为算术指令操作数,和从存储器取出常数相比,操作速度 更快,能耗更低。、
-
自我检测鉴于寄 存器的重要性,芯片中的寄存器数量随时间变化的增长率是下面哪个?
- 非常快:和摩尔定律一样快,摩尔定律预测每18个月芯片上的晶体管数量增长1倍。
- 非常慢:由于程序通常以计算机语言实现,并且指令系统体系结构存在惯性,因此寄存器数量的增长速度与新指令系统在体系结构中的可行性保持一致。
2.4 有符号数与无符号数
-
首先回顾一下,计算机是如何存储数字的。在生活中,我们大多使用十进制,但是数的进制是任意的。在计算机硬件中,数是以一串或高或低的电信号来体现的,因此可以被认为基为 2 的数。
-
二进制数位(binary digit):又称为位,以2为基数表示,或0或1,是信息的基本组成单位。
-
无符号数
- 进制转换,对于任意进制而言
 下面的表格表示了 RISC-V双字中的每一位编号和数字 1011(2进制)的存放位置:
下面的表格表示了 RISC-V双字中的每一位编号和数字 1011(2进制)的存放位置: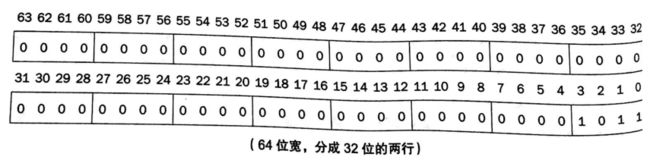
- 由于字是在水平或者竖直方向上书写的,用最左边或者最右边表示大小带有不确定性。最低有效位(least significant bit) 表示最右边一位(比如上图中第 0 位,对应数据 1),**最高有效位( most significant bit)**表示最左边一位(上图中的第 63 位,对应数据 0 )。
- RISC-V的字有 64位,可以表示 2^64 个不同的 64位模式,很自然就可以使这些组合表示从 0到 2^64-1之间的数:

- 历史上,第一台商用计算机使用的是十进制算术。而问题出现在开关信号上,在十进制表示的计算机中,一个十进制数字由几个二进制数字表示。事实证明十进制的效率非常低,所以后来所有计算机都转换为 2 进制,只有在相对很少发生的 I/O 事件中才将数据转换为十进制。
- 进制转换,对于任意进制而言
-
有符号数
-
原码(sign and magnitude):计算机程序需要对正数和负数进行计算。所以需要增加一个独立的符号位来区分正负数。但由于符号位放置在哪里不够明确,左边还是右边?早期计算机对于这两种方法都尝试过。另外,不可能在计算时提前得知结果的符号,对于符号和幅值表示的数字进行计算需要额外的一步来设置符号。还有,一个单独的符号为意味着存在正零和负零,因此很对这种表示方法便被舍弃了。
-
二进制补码(two’s complement):前导位 0 表示正数,1 表示负数。这种表示方法易于硬件实现。例如:


-
二进制补码表示的优点是,所有负数的最高有效位都为1。因此,硬件只需要检测这意味就可以查看是正数还是负数(数字0被认为是正数)。这个位通常被称为符号位。理解了符号位的作用,就可以用每位数值乘以2的幂之和来表示正负数的64位数:

-
-
溢出(overflow):
- 正如对无符号数的操作结果可能超出硬件容量而产生溢出一样,对二进制补码的操作也是如此。
- 当二进制位模式下最左边的保留位与左边的无限数位不相同时(即符号位不正确),溢出发生;当数为负数时最左侧为0,或当数为正数时最左侧为1。
-
**RISC-V确实提供了两种字节载入方式:无符号字节载入(lbu)将字节视为无符号数,因此用零扩展填充寄存器的最左位,而字节载入(lb)使用带符号整数。**由于 C 语言程序几乎都是使用字节来表示字符,而不是将字节视为有符号短整数,所以实际中 lbu 专门用于字节加载.
-
处理二进制补码数的两种有用的快捷方法:
-
第一种是对二进制补码求相反数的快速方法。简单地把每个0都转为1以及每个1都转为0,然后对结果加1。这个捷径是基于以下观察:

-
例题:求相反数的捷径
-
第二种方式是将一个用n位表示的二进制数转换为一个用多于n位表示的数。先去位数更少的数的最高位(符号位),并将其复制来填充位数更多的数的新位。原来的非符号位被复制到新双字的右侧部分。这个方式通常被称为符号扩展(sign extension)
-
例题:符号扩展的快捷方式 将16位二进制数2(10进制)和-2(10进制)转换成为64位二进制数。
该方式之所以有效是因为在正数二进制补码的左边实际上是无限个0,而负数的二进制补码在左边是无限个1。二进制位模式隐藏了前面的位以适应硬件的宽度,符号扩展只是恢复其中的一些
-
-
反码(one’s complement):一个数的相反数就是将这个数的每一位按位取反,0 变成 1, 1 变成 0. 与补码相比,反码除了有两个零00…00(2进制),100…00(2进制) 之外,其余都是一样的。绝对值最大的负数(最小的负数)为 10…00(2进制),并且负数的个数和正数的个数是一样的。当采用反码时,加法器需要一个额外的步骤减去一个数来修正结果。
-
偏移表示法(biased notation):又称为移码,通过将数加一个偏移使其具有非负的表示形式,最小的负数为 00…000(2进制),最大的正数为 11…111(2进制)表示, 0一般使用10…000(2进制) 表示,此时选择的偏移值为 2^n - 1.
2.5 计算机中指令的表示
-
指令在计算机内部是以若干个或高或低的电信号的序列表示的,并且形式上和数的表示相同。实际上,指令的各个部分都可以看成一个独立的数,将这些数字拼接在一起就形成了指令。
-
例题:将一条RISC-V汇编指令翻译为一条机器指令 下面以RISC-V为例,对于符号表示为 add x9,x20,x21的RISC-V指令,首先以十进制表示,然后二进制表示。答:


- 一条指令的每一段称为一个字段。第一、第四和第六个字段(0、0和51)组合起来告诉RISC-V计算机该指令执行加法操作。
- 第二个字段给出了作为加法运算的第二个源操作数的寄存器编号(21表示x21),第三个字段给出了加法运算的另一个源操作数(20表示x20)。
- 第五个字段存放要接受总和的寄存器编号(9表示x9)
- 因此,该指令将寄存器x20和寄存器x21相加并将和存放在寄存器x9中。
-
指令格式:由二进制数字字段组成的指令表示形式
-
机器语言:用于计算机系统内通信的二进制表示
-
十六进制数:以16为基数的数字表示
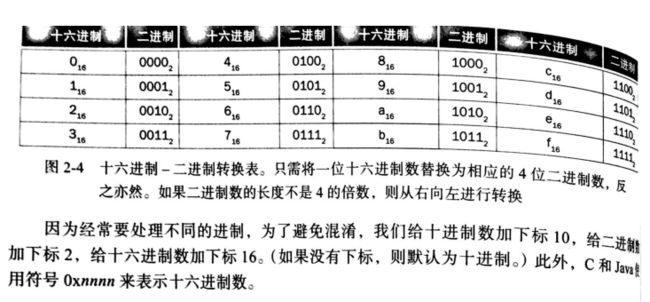
例题:二进制和十六进制间的转换 将下面的8位十六进制数转换为二进制,将32为二进制数转换为十六进制: eca8 6420(16) 0001 0011 0101 0111 1001 1011 1101 1111(2)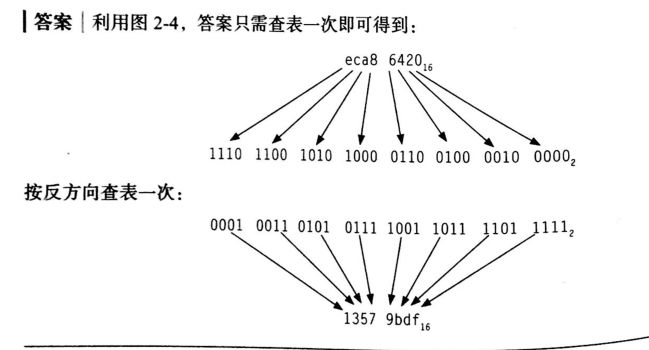
-
RISC-V字段:

以下是RISC-V指令中每个字段名称的含义:
- opcode(操作码):指令的基本操作,这个缩写是它的惯用名称
- rd:目的操作数寄存器,用来存放操作结果
- funct3:一个另外的操作码字段
- rs1:第一个源操作数寄存器
- rs2:第二个源操作数寄存器
- funct7:一个另外的操作码字段
-
问题:当某条指令需要比上述字段更长的字段时,问题就会发生。例如,取字指令必须指定两个寄存器和一个常数,在上述各始终,如果地址使用其中的一个 5 位字段,那么取字指令的最大常数将被限制为31或2^5-1。而这个常数通常用来从数组或者数据结构中选择元素,所以它常常比 31 大的多。因此, 5 位字段因太小而用途不大。
-
因此,所有指令长度相同和统一的指令格式二者之间产生了矛盾。
-
我们回头看硬件设计原则:优秀的设计需要适宜的折中方案。

-
让我们分析以下2.3.1节提到的加载寄存器指令: ld x9,64(x22)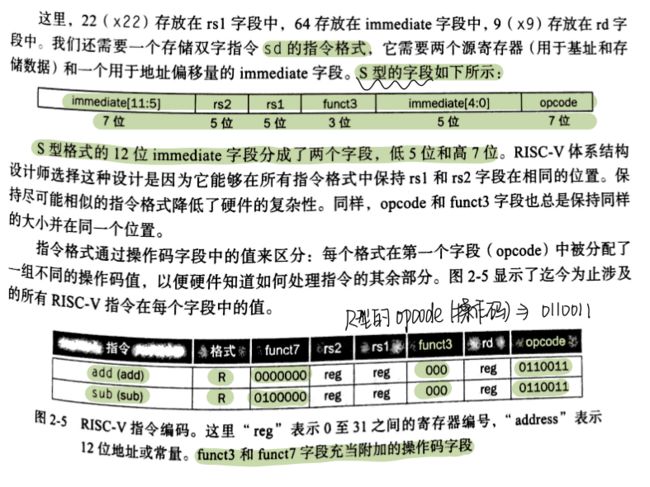
-
例题:将RISC-V汇编语言翻译为机器语言 现在我们可以举一个例子来描述从程序员编写程序到计算机执行指令的整个过程。假设数组A的基址存放于x10,h存放于x21,则赋值语句: A[30] = g + A[30] + 1; 被编译成: ld x9 , 240(x10) add x9 , x21 , x9 addi x9 , x9 , 1 sd x9 , 240(x10) 这三条指令的RISC-V机器语言代码是什么?

-
RISC-V机器语言的各个部分

-
自我检测
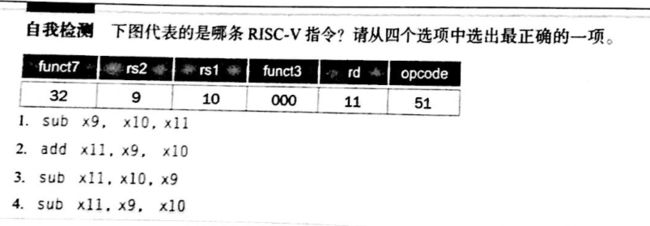
答: sub指令由funct7和funct3和opcode的值共同指定
rs1=10表示第一个源操作数寄存器为x10
rs1=9表示第二个源操作数寄存器为x9
rd=11表示目的寄存器为x11
故选C
2.6 逻辑操作
-
对字中由若干位组成的字段甚至对单个位进行操作是很有用的。因此,在编程语言和指令集体系结构中便增加了一些指令,用于简化对字中若干位进行打包或者拆包的操作。这些指令便是逻辑操作。
-
如下图,展示了C,Java,RISC-V 中的逻辑运算。

-
移位(shift):这个操作将一个字里面的所有位向左或向右移动,并在空出来的位置上添加零。

对应于左移的是右移。这两条RISC-V移位指令的实际名称是左移逻辑立即数(slli)和右移逻辑立即数(srli)。
假设初始值位于寄存器x19中且结果应存入寄存器x11,则以下指令执行上述操作: slli x11,x19,4 //左移4位
-
按位与(AND):当两个操作数都为 1 时,经过AND 运算后才为 1.
例如,0000 0000 0000 0000 0000 1101 1100 00000000 0000 0000 0000 0000 1101 1100 0000 和 0000 0000 0000 0000 0011 1100 0000 0000 0000 0000 0000 0000 0011 1100 0000 0000 得到的值是: 0000 0000 0000 0000 0000 1100 0000 00000000 0000 0000 0000 0000 1100 0000 0000
AND 操作提供了一种将源操作数置零的能力。 -
按位或(OR):当两个操作数其中有一个为 1 时,经过 OR 运算变成 1.
-
按位取反(NOT):对于这个操作,它将位上的 0 变成 1,1 变成 0.
-
或非(NOR):按位先或后非操作,仅当两个操作位均为 0 时结果才为 1.
-
异或(XOR):当两个操作数对应位置不同时为1,相同时为 0.
-
RISC-V也提供了 立即数与(andi)、立即数或(ori)和立即数异或(xori)
2.7 决策指令
-
条件分支(copnditional branch):该指令先比较两个值,然后根据比较的结果决定是否从程序中的一个新地址开始执行指令序列。
RISC-V中两条类似与if和go to语句功能的指令。
beq rs1, rs2, L1,该指令表示,如果rs1 和 rs2 中的数值相等,那么转到标签为 L1 的语句中执行。beq代表的是如果相等则分支(branch if equeal).bne rs1, rs2, L1,该指令表示,如果rs1 和 rs2 中的数值不相等,那么转到标签为 L1 的语句中执行。bnq代表的是如果不相等则分支(branch if not equeal).
例题:将if-then-else语句编译为条件分支指令 在下面的代码段中,f、g、h、i和j是变量。如果五个变量f到j对应于x19到x23这5个寄存器,这个c语言的if语句编译后的RISC-V代码是什么? if(i==j) f = g + h ; else f = g - h; 答: bne x22 , x23 , Else //如果i和j不相等则跳转到else add x19,x20,x21 //执行相加操作 beq x0,x0,Exit //无条件分支 如果0==0结束 Else:sub x19,x20,x21 //执行相减操作 Exit //代码结束
2.7.1 循环
-
**基本块:没有分支(可能出现在末尾者除外)并且没有分支目标/分支标签(可能出现在开始者除外)的指令序列。
-
小于则分支指令:比较寄存器rs1和rs2中的值(采用二进制补码表示),如果rs1中的值较小则跳转
-
大于等于分支指令:是相反的情况,也就是说如果rs1中的值至少不少于rs2中的值则跳转
-
如果二者是无符号数,无符号数的小于则分支指令那么rs1中的值小于rs2中的值则跳转。最后,无符号数的大于等于则分支指令在相反的情况下跳转。
例题 编译一个C语言的while循环 下面是一个C语言的常见循环 while (save[i] == k) i += 1; 假设i和k对应于寄存器x22和 x24,数组的基址保存在x25中。与此C语言代码相对应的RISC-V汇编代码是什么? 答: Loop: slli x10,x22,3 //由于字节寻址问题必须将索引乘以 8,故左移3位 add x10,x10,x25 //获得save[i]的地址 ld x9,0(x10) //利用临时寄存器存放地址 bne x9,x24,Exit //如果save[i]不等于k退出循环 addi x22,x22,1 //i加1操作 beq x0,x0,Loop //执行循环 Exit: //代码结束
2.7.2 边界检查的简便方法
-
将有符号数当作无符号数处理,给我们提供了一种低成本的方式检查是否0≤x
-
例题 利用该简便方法可以降低下标越界检查的开销:如果x20≥x11或x20是负数则跳转到IndexOutOfBounds。 答:检查代码仅使用无符号数的大于或等于来进行两项检查: bgeu x20, x11. IndexOutofBounds //if x20 >=x11 or x20 < 0, goto IndexOutOfBounds
2.7.3 case/switch语句
- 分支地址表:也称作分支表,一种包含了不同指令序列地址的表
- 程序只需要索引到表中,然后跳转到合适的指令序列。因此,分支表只是一个双字数组,其中包含与代码中的标签对应的地址。该程序将分支表中的相应条目加载到寄存器中,然后需要使用寄存器中的地址进行跳转。为了支持这种情况,RISC-V这类指令系统包含一个间接跳转指令,该指令对寄存器中指定的地址执行无条件跳转。在RISC-V中,跳转-链接指令(jar)用于此目的。我们将在下一节中看到这种多功能指令更多常见的使用方式。
- 虽然在 C 或者 Java 这样的编程语言中有许多决策和循环语句,但是在指令集这一个层次上实现其功能的基本语句是条件分支。
2.8 计算机硬件对过程的支持
-
过程(procedure):根据提供的参数执行一定任务的存储的子程序。它或者函数是程序员进行结构化编程的工具,二者均有助于提高程序的理解性和代码的可重用性。过程允许程序员每次只需将精力集中在任务的一部分,由于参数能传递数值并返回结果,因此参数承担过程与其他程序、数据之间接口的角色。过程是软件中实现抽象的一种方法。
-
在过程运行中,程序必须遵守以下 6 个步骤:
- 将参数放在过程可以访问的位置。
- 将控制转交给过程。
- 获得过程所需的存储资源。
- 执行需要的任务。
- 将结果的值放在调用程序可以访问的位置。
- 将控制返回初始点,因为一个过程可能由一个程序中的多个点调用。
-
由于寄存器是计算机中保存数据最快的位置,所以我们希望尽可能多的使用寄存器。RISC-V软件在为过程调用分配 寄存器时遵循以下约定:
- x10 ~ x17 : 八个参数寄存器,用于传递参数或返回值
- x1 : 一个返回地址寄存器,用于返回到起点
除了分配这些寄存器之外, RISC-V汇编语言还包括一条过程调用指令:跳转到某一个地址的同时将下一个指令的地址保存在寄存器rd中。这便是跳转和链接指令(jal)。
写作: jal x1 , ProduceAddress
-
返回地址(return address):指向调用点的链接,允许过程返回到合适的地址;在RISC-V中被存储在寄存器x1中
-
调用者(caller):启动过程并提供必要参数值的程序
-
被调用者(callee):根据调用者提供的参数执行一系列存储的指令,然后将控制权返回调用者的过程。
-
程序计数器(program counter,PC):PC 中包含在程序中正在被执行指令地址的寄存器。
2.8.1 使用更多的寄存器
- 栈(stack):被组织成后进先出队列形式并用于寄存器换出的数据结构。
栈需要一个指针,以指向栈中最新分配的地址,以只是下一个过程放置换出寄存器的位置,或者是寄存器旧值的存放位置。 - 栈指针(stack pointer):指示栈中最新分配得地址的值,它指示寄存器被换出的位置,或寄存器旧值得存放位置。在RISC-V中为寄存器sp或x2
栈指针是以双字为单位进行调整。 - 两个最基本的操作:
- 压栈(push):向栈中增加元素。
- 出栈(pop):从栈中移出元素。
- 按照管理,栈“增长”是按照地址由高到低的顺序进行的。这意味着,数据压栈时,栈指针减小;数据出栈时,栈长度缩短,栈指针增大。
2.8.2 嵌套过程
-
叶子过程(leaf procedure):不调用其他过程的过程。
如果所有过程都是叶过程,那么情况就很简单,但是实际并么如此
例如,假设主程序调用过程A,参数为3,将值3存人寄存器x10然后使用jal x1,
A。再假设过程A通过ja1 x1, B调用过程B,参数为7,也存人x10。由于A尚未结束任务,所以寄存器x10的使用存在冲突。同样在寄存器x1中的返回地址也存在冲突,因为它现在具有B的返回地址。除非采取措施阻止这类问题发生,否则该冲突将导致过程A无法返回其调用者。一种解决方法 是将其他所有必须保存的寄存器压栈,就像保存寄存器压栈- -样。 调用者将所有调用后还需要的参数寄存器(x10 ~ x17)或临时寄存器(x5~ x7和x28~ x31)压栈。被调用者将返回地址寄存器x1和被调用者使用的保存寄存器(x8 ~ x9)和x18~ x27)压栈。调整栈指针sp以计算压栈寄存器的数量。返回时,从存储器中恢复寄存器并重新调整栈指针。
-
全局指针(global pointer):指向静态数据区的保留寄存器。
C语言中的一个变量通常对应存储中的一个位置,其解释取决于其类型(type)和存储方式(storage class)。例如整型和字符型。C语言包括两种存储方式:动态的(automatic)和静态的(static)。动态变量位于过程中,退出过程时失效。静态变量在进入和退出过程时始终存在。在所有过程之外声明的 C 变量,以及声明时候使用的关键字 static 的变量都被视作静态的,其余的变量都被视作动态的。为了简化静态数据的访问,RISC-V软件保留了一个寄存器x3,这便是全局指针。

2.8.3 在栈中为新数据分配空间
-
栈的最后一点复杂性在于栈还需要存储过程的局部变量,但是这些变量不适合于寄存器,例如局部的数组或者结构体。
-
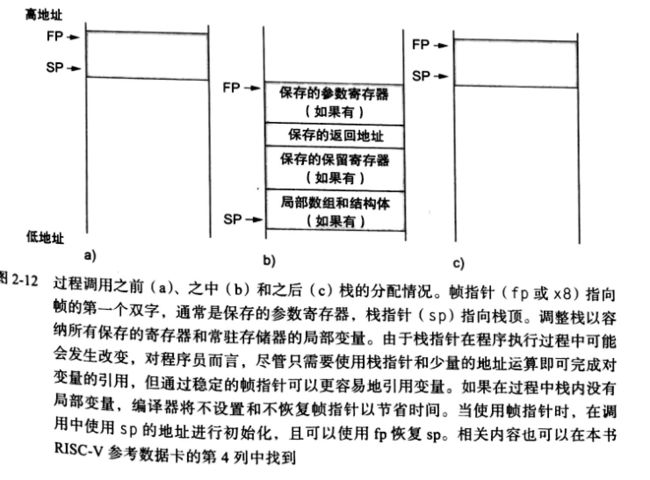
过程帧(procedure frame):也称作活动记录,栈中包含过程所保存的寄存器以及局部变量的片段。
-
帧指针(frame pointer):指向给定过程中保存的寄存器和局部变量的值。
2.8.4 在堆中为新数据分配空间
-
代码段:UNIX目标文件的段,包含源文件中例程的机器语言代码
-
除了动态变量对于过程是局部有效之外,C程序员还需要再内存中为静态变量和动态数据结构提供空间,如下图,给出了RISC-V分配内存的约定:
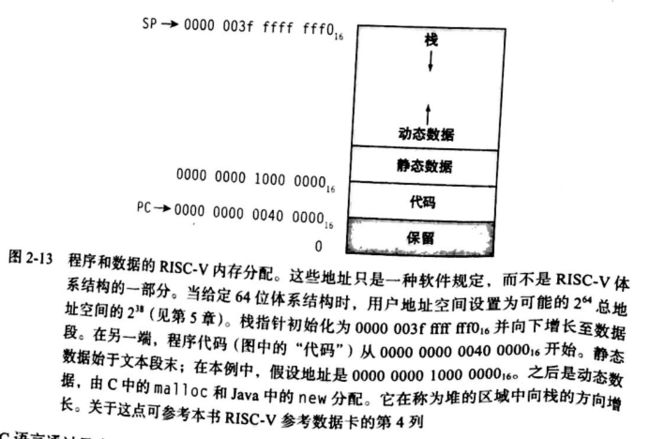
栈由内存高端开始向下增长。内存低端的第一部分是保留的。之后是RISC-V机器代码的第一部分,通常称为代码段(text segment)。代码段之上的代码为静态数据段(static data segment),是存储常量和其他静态变量的空间。尽管数组通常具有固定长度因而能和静态数据段很好的匹配,但是类似链表这样的数据结构通常会再生命期内增加或者缩短。这类数据结构对应的段习惯上称为堆(heap),一般再存储器中放在静态数据段之后,注意,这种分配允许栈和堆相互增长,从而再两个段此消彼长的过程中达到内存的高效使用。
-
C语言通过显式的函数调用再堆上分配ta和释放空间。malloc() 再堆上分配空间并指向它的指针,free() 释放指针指向的堆空间。内存分配由 C 程序控制,这是很多错误产生的根源。忘记释放空间会导致“内存泄漏”,它会逐渐耗尽大量内存以至于操作系统可能崩溃。过早释放空间会导致“悬摆指针”(dangling pointer),这会造成指针指向程序不想访问的位置。在Java中使用自动的内存分配和无用单元回收机制来放置类似的错误发生。
-
一些递归过程可以使用迭代的方式来实现。通过消除过程调用的相关开销,迭代可以显著提升性能。
-
RISC-V指令系统具有加载和存储这种16位半字的指令。load half unsigned (加载无符号半字)从内存中读取一个半字,将它放在寄存器的最右边16位,用零填充最左边的48位。与加载字节一样,加载半字(lh)将半字视为有符号数.因此进行符号扩展以填充寄存器的最左边48位。存储半字(sh)从寄存器的最右边16位取半字并将其写入内存。
-
RISC-V 还包括将32位值移入和移出存储器的指令。加载无符号字(lwu)将32位字从存储器加载到寄存器的最右边32位,用零填充最左边的32位。加载字(lw) 用第31位的值填充最左边的32位。存储字(sw)从寄存器的最右边32位取一个字并将其存储到存储器中。
2.9 人机交互
- 你的书上没有 哈哈哈哈哈
2.10 对大立即数的RISC-V编址和寻址
2.10.1 大立即数
-
虽然常量通常很短并且适合12位字段,但有时它们也会更大。
RISC-V指令系统包括指令loadupperimmediate(取立即数高位,lui),**用于将20位常数加载到寄存器的第31位到第12位。将第31位的值复制填充到最左边32位,最右边的12位用0填充。**例如,这条指令允许使用两条指令创建32位常量。lui使用新的指令格式——U型。 因为其他格式不能支持如此大的常量。 -
例题:加载一个32位常量 将以下64位常量加载到寄存器x19的RISC-V汇编代码是什么 00000000 00000000 00000000 00000000 00000000 00111101 00000101 00000000 答: 首先,我们使用lui加载12到31位,十进制值为976; lui x19,976 //12到31位 0000 0000 0011 1101 0000 添加最低12位,其十进制值位1280 addi x19,x19,1280 // 1280 = 00000101 00000000
2.10.2 分支中的寻址
-
**RISC-V分支指令使用称为SB型的RISC-V指令格式。这种格式可以表示从-4096到4094的分支地址,以2的倍数表示。**由于最近的一些原因,它只能跳转到偶数地址。SB型格式包括一个7位操作码、一个3位功能码、两个5位的寄存器操作数(rs1和rs2)和一个12位地址立即数。该地址使用特殊的编码方式,简化了数据通路设计,但使组装变得复杂。
-
程序计数器 = 寄存器内容 + 分支地址偏移量
-
PC相对寻址(PC-relative addressing):一种寻址方式,它将 PC和指令中的常数相加作为寻址结果。
-
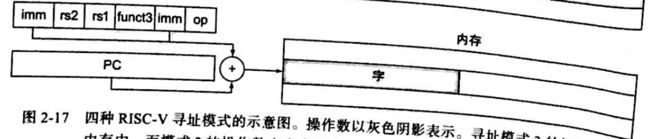
与最新的计算机一样,RISC-V对条件分支和无条件跳转使用PC相对寻址,因为这些指令的目标地址可能距离分支很近。另一方面,过程调用可能需要转移超过2^18个字的距离,因为不能保证被调用者接近调用者。因此,RISC-V允许使用双指令序列来非常长距离地跳转到任何32位地址: lui将地址的第12位至第31位写人临时寄存器,jalr将地址的低12位加到临时寄存器并跳转到目标位置。
2.10.3 RISC-V寻址模式总结
- 寻址模式(addressing mode):根据对操作数和/或地址的使用不同加以区分的多种寻址方式中的一种。
- 立即数寻址(immediate addressing):操作数是位于指令自身中的常数。

- 寄存器寻址(register addressing):操作数是寄存器。

- 基址寻址(base addressing):又称为偏移寻址(displacement addressing),操作数在内存中,其地址是指令中基址寄存器和常数的和。
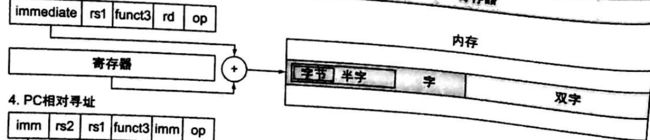
- PC相对寻址(PC-relative addressing):地址是PC和指令中常数的和。
- PS:如果图看的不是很清楚 请看PDF第83页
- 立即数寻址(immediate addressing):操作数是位于指令自身中的常数。
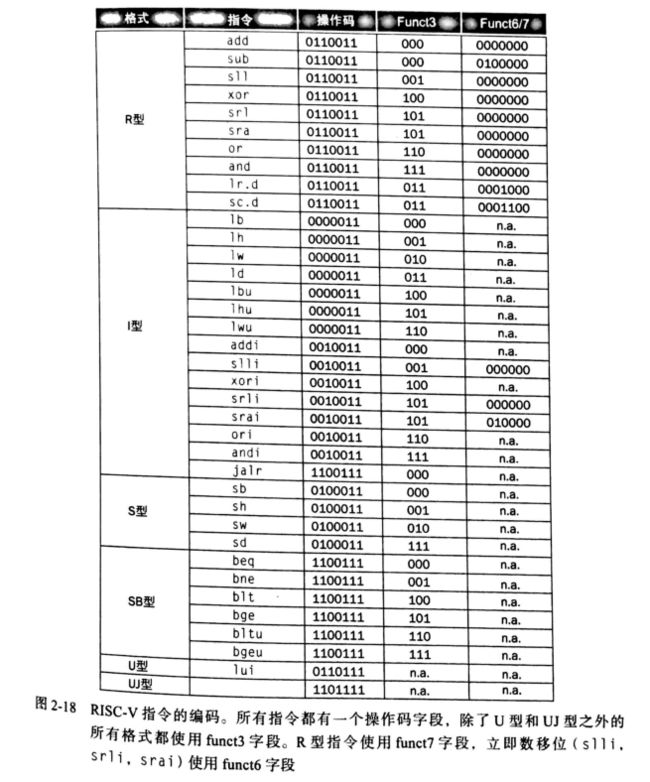
2.10.4 机器语言编码
-
如图

2.11 指令与并行性:同步
-
数据竞争(data race):假如来自不同线程的两个方寸请求访问同一个地址,它们连续出现,并且至少一个是写操作,那么这两个存储访问性成数据竞争。
当任务之间相互独立的时候,任务的并行执行是比较容易实现的。但是往往人物之间互相协作,这种协作通常意味着某些任务的结果是其他任务需要读取的值。这时候执行读任务的一方就需要直到写任务的一方什么时候完成了写操作,此时可以安全地读数据,否则便发生数据竞争,导致读数据出错而引起运行结果的改变。
-
在计算机中,同步机制要依赖硬件提供的同步指令,这些指令可以由用户调用。我们讨论**加锁(lock)和解锁(unlock)同步操作的实现。采用枷锁和解锁可以直接创建一个仅允许单个处理器操作的区域,叫做互斥(mutual exclusion)**区。更复杂的同步机制实现方式也是类似
-
在多处理器实现同步需要一组硬件原语,提供对存储的单元进行原子读和原子写的操作,使得在进行存储器原子读和原子写操作时候任何其他操作不得插入。硬件原语十分重要,如果没有它,同步机制花费的代价特别高。
-
建立基本的原语有若干可选的方案,并且这些方案都可以实现原子读和原子写的操作,并可以用某种方法表示这些操作是否为原子操作。通常,体系结构设计人员并不希望基本硬件原语被用户使用,而是希望原语被系统程序员来建立同步库。
-
如何建立基本的同步机制?
我们使用原子交换原语(atomic exchange或atomic swap),这个原语是将寄存器中的一个值和存储器中的一个值互相交换。假定使用存储器中某个单元来表示一个锁变量:数值0表示解锁,数值1表示加锁。一个处理器尝试对锁单元进行枷锁,方法是用一个寄存器中的1与该锁单元的值进行交换。交换后锁单元的值为1,返回值(锁单元的原值)如果是1,表明这个锁已经被其他的处理器占用,返回值0表明锁是自由的,尝试枷锁成功。此时锁单元的值为1,可以防止其他的处理器来占用。
假如考虑有两个处理器同时尝试进行交换操作,它们的竞争关系就会遭到破坏,因为其中只有一个处理器先执行交换操作,并返回值0,那么第二个处理器执行完交换操作时返回值便变为1.用交换原语实现同步的关键在于操作的原子性:交换操作是不可分割的,并且由硬件对两个同时执行的交换操作进行排序。有可能两个处理器同时尝试置位同步变量,但是这两个处理器认为它们同时成功设置同步变量是不可能的。 -
实现单个额原子存储器操作给处理器的设计者带了很大挑战性,因为这要求存储器的读写操作都是单条不可被中断打断的指令完成的。
一种可行的方法是采用指令对,其中第二条指令返回一个表明这对原子执行的标志值。假如处理器的操作都是在这对指令之后或者之前执行,这对指令就是原子的。因此,当一个指令对是原子的,没有哪个处理器能改变两个指令执行之间的数据值。 -
在RISC-V中,这对指令指的是一个称为保留加载双字(lr,d)的特殊加载指令和一个称为条件存储双字(sc.d)的特殊存储指令。顺序使用这两条指令:如果链接取数指令所指的锁单元的内容在相同地址的条件存数指令执行之前就已被改变,那么从条件存数指令就执行失败。我们定义条件存数指令完成以下功能:保存寄存器的值,并且如果执行成功则将寄存器的值修改为1,失败则修改为0.因为链接取数指令返回锁单元的初始值,条件存数指令执行成功时候才返回1。
-
单处理器中原子操作也很有用。
2.12 翻译并启动程序
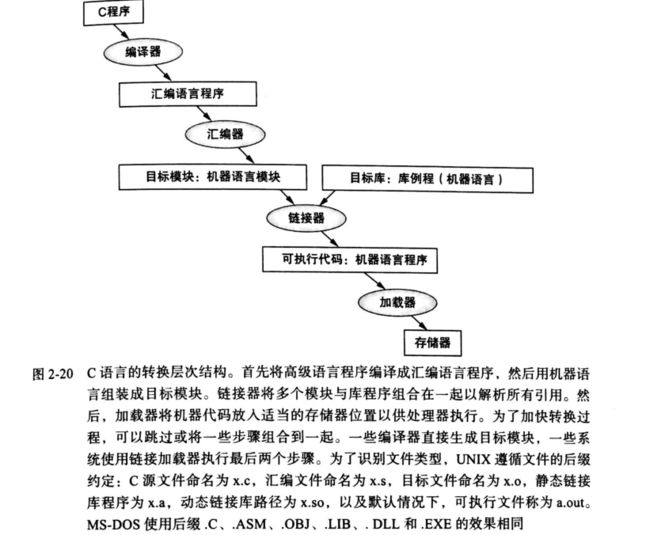
2.12.1 编译器
- 汇编语言(assembly language):一种符号语言,可以被翻译为二进制语言。
编译器可以将C语言程序转换为汇编语言程序。
2.12.2 汇编器
- 伪指令(pseudoinstruction):汇编语言指令的一种变种,通常被看作一条汇编指令。
因为汇编语言对于高层次软件是一个接口,所以汇编器也可以处理一些机器语言指令的常见变种。硬件不需要实现这些指令,然而他们在汇编语言中的存在简化了程序转换和编程。 - RISC-V汇编器使用十六进制和八进制。这个特性十分方便。
- 汇编器将汇编语言转换成为目标文件(object file),它包括机器语言指令、数据和指令正确放入内存中所需要的信息。
- 符号表(symbol table):一个用来匹配标记名和指令所在内存字的地址得列表。为了产生汇编语言程序中每条指令对应的二进制表示,汇编器必须处理所有标号对应的地址。
2.12.3 链接器
- 到目前为止,我们描述的内容表明,对于源程序任意一行代码的修改都需要重新编译和汇编整个程序。这无疑是非常浪费的,一种方法是单独编译和汇编每个过程,使得某一行代码的改变只需要编译和汇编一个过程。
- 链接器(linker):又称作链接编辑器。它是一个系统程序,用来把各个独立汇编的机器语言组合起来并解决所有未定义的标记,最后生成可执行文件。
链接器的工作分为三个步骤:1. 将代码和数据模块象征性地放入内存。2. 决定数据和指令标签的地址。3. 修补内部和外部的引用。 - 链接器使用每个目标模块中的重定位信息和符号表,来解析所有未定义的标签。这种引用发生在分支指令、跳转指令和数据寻址处,所以这个程序的工作就非常像一个编辑器:它寻找所有旧地址并用新的地址取代它们。
- 可执行文件(executable file):它可以在一台计算机上运行。通常,这个文件与目标文件具有相同的格式,但是它不包含未解决的引用。
2.12.4 加载器
- 加载器(loader):把目标程序装在到内存中以准备运行的系统程序。
2.12.5 动态链接库
- 动态链接库(dynamicaly linked library,DLL):在程序执行过程中才被链接的库例程