抠图算法Background Matting:The world is your green screen
论文地址:https://arxiv.org/abs/2004.00626
代码:https://github.com/senguptaumd/Background-Matting
背景介绍
抠图是照片编辑和视觉效果中使用的标准技术,在现有的抠图算法中,要想抠出一个好的maks一般需要三分图(trimap由前景,背景,未知片段组成)。虽然现在也有不需要三分图的算法正在发展,但是这种不需要三分图的算法,在抠图的质量与有三分图的算法没有可比性。
因此,在本算法中除了需要原图片之外,还需要一张额外的背景图片。
抠图算法的公式
I = α F + ( 1 − α ) B I = \alpha F+(1-\alpha)B I=αF+(1−α)B
F F F:前景图(foreground), B B B:背景图(background)。 α \alpha α:混合系数(mixing coeffcient)。 I I I:图像的合成方程
当 α \alpha α趋近与0的时候,就会获得背景图,相反,当 α \alpha α趋近与1时,就会获得前景图。
方法介绍
核心方法
在本文中,核心是使用一个深度抠图网络G,对输入的图片进行前景色和 α \alpha α进行提取,对背景色和软分割进行增强,在接上一个鉴别器网络D指导训练生成真实的结果
网络结构图

Adobe数据集上的监督训练
输入
包含对象在前景中的图像 I I I(Image),图像 I I I中对应的背景图像 B ′ B^{\prime} B′(Background)(这个和真实的背景图 B B B不同),对象的软分割图像 S S S(Soft Segmentation)以及对象再相邻时间上的临近帧 M M M(Motion Cues)。
为了生成软分割图像 S S S需要对图像进行Decoder-Encoder的卷积处理后获得粗分割结果,在对图片进行腐蚀,扩张以及高斯模糊。
当选择的是视频输入时,将 M M M设置为 I I I前后两帧的拼接,令每一帧的时间间隔为T,则:
M = { I − 2 T , I − T , I + T , I + 2 T } M = \{I_{-2T},I_{-T},I_{+T},I_{+2T}\} M={ I−2T,I−T,I+T,I+2T}
这些图像被转化为灰度图像,以忽略颜色的信息而更多地倾向于对象的运动信息。
在没有选择视频输入时,把 M M M理解为图像 I I I的复制,即:
M = { I , I , I , I } M = \{I,I,I,I\} M={ I,I,I,I}
将输入集表示为 X = { I , B ′ , S , M } X = \{I,B^{\prime},S,M\} X={ I,B′,S,M},则带有权重的网络计算过程可抽象地表示为:
( F , α ) = G ( X ; θ ) (F,\alpha) = G(X;\theta) (F,α)=G(X;θ)
内容切换块(Context Switching Block)
聚焦于网路图左边部分:
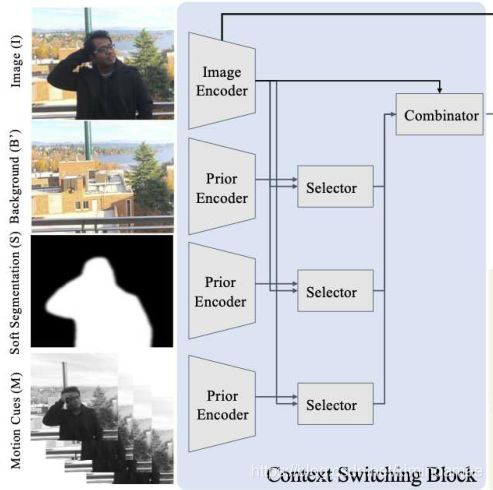
输入的内容 X X X对应图中左边的四个部分,分别采用不同的Enocder对各自部分的图像进行编码,最终各自生成对应的通道数为256的feature map。接着使用Selector块将来自I的feature map与 B ′ , S , M B^{\prime},S,M B′,S,M中的每一个部分分别组合,最终生成三个通道数为64的feature map。
Selector块由:1x1卷积,BatchNorm和ReLU构成
接着使用Combinator(结构与Selctor一致),将三个64通道的feature map与原始图像 I I I中256通道的feature mp进行组合,以产生编码特征(encoded features),该特征被传递到网路偶的其余部分,包括残差块和decoders。
现在看网络结构的右上角部分

将拼接好的编码特征,传递到通用的残差块(ResBLKs)中,在分别经过各自的残差块进行进一步的特征提取。对于前景图部分,将原图 I I I的256通道的feature map与经过残差块的feature map进行融合,输入到Decodor中,将前景分割出来,同时将 α \alpha α遮罩(alpha matte)的部分进行解码,在讲两者结合通方程:
I = α F + ( 1 − α ) F I = \alpha F+(1-\alpha) F I=αF+(1−α)F
生成图像,与原图像进行对比从而优化网络。
在这个过程中 B ′ B^{\prime} B′的获取不是真实的 B B B,而是通过对前景区域部分进行小伽马校正 γ ∼ N ( 1 , 0.12 ) \gamma \sim \mathcal{N}(1,0.12) γ∼N(1,0.12)或者通过添加高斯噪声 η ∼ N ( μ ∈ [ − 7 , 7 ] , σ ∈ [ 2 , 6 ] ) \eta \sim \mathcal{N}(\mu \in[-7,7], \sigma \in[2,6]) η∼N(μ∈[−7,7],σ∈[2,6])来生成的。
在最后的运动线索中,合成到背景上之前,对前景和 α \alpha α遮罩进行随机仿射变换,然后转化为灰度图。为了计算I和M,最后是用B(真实的背景图)来应用到图像合成方程中,但是,最初输入进网络的仍然是 B ′ B^{\prime} B′。
最后训练网络 G A d o b e = G ( X ; θ A d o b e ) G_{Adobe} = G(X;\theta_{Adobe}) GAdobe=G(X;θAdobe)的损失函数为:
L = min θ Adobe E X ∼ p X [ ∥ α − α ∗ ∥ 1 + ∥ ∇ ( α ) − ∇ ( α ∗ ) ∥ 1 + 2 ∥ F − F ∗ ∥ 1 + ∥ I − α F − ( 1 − α ) B ∥ 1 ] L = \min _{\theta_{\text {Adobe }}} E_{X \sim p_{X}}\left[\left\|\alpha-\alpha^{*}\right\|_{1}+\left\|\nabla(\alpha)-\nabla\left(\alpha^{*}\right)\right\|_{1}\right.\left.+2\left\|F-F^{*}\right\|_{1}+\|I-\alpha F-(1-\alpha) B\|_{1}\right] L=θAdobe minEX∼pX[∥α−α∗∥1+∥∇(α)−∇(α∗)∥1+2∥F−F∗∥1+∥I−αF−(1−α)B∥1]
未标记真实数据的对抗训练
对于未标记的数据来说,在图像的细节部分,比如人的手指,头发以及和背景色相近的前景色区域。在这些区域的表现一般都会比较粗糙。举个例子,原来抠图的图像前景中,掺杂着一部分的背景色,对抗训练就是为了解决这个问题而设计的一个网络。
算法采用的是LS-GAN框架来训练生成器 G R e a l G_{Real} GReal和判别器 D D D,为此,对生成器来说,要更新参数,使得以下式子最小化:
min θ R e a l E X , B ˉ ∼ p X , B ˉ [ ( D ( α F + ( 1 − α ) B ˉ ) − 1 ) 2 + λ { 2 ∥ α − α ~ ∥ 1 + 4 ∥ ∇ ( α ) − ∇ ( α ~ ) ∥ 1 + ∥ F − F ∥ 1 + ∥ I − α F − ( 1 − α ) B ′ ∥ 1 } ] \min _{\theta_{\mathrm{Real}}} \mathbb{E}_{X, \bar{B} \sim p_{X, \bar{B}}}\left[(D(\alpha F+(1-\alpha) \bar{B})-1)^{2}\right.+\lambda\left\{2\|\alpha-\tilde{\alpha}\|_{1}+4\|\nabla(\alpha)-\nabla(\tilde{\alpha})\|_{1}\right.\left.\left.+\|F-F\|_{1}+\left\|I-\alpha F-(1-\alpha) B^{\prime}\right\|_{1}\right\}\right] θRealminEX,Bˉ∼pX,Bˉ[(D(αF+(1−α)Bˉ)−1)2+λ{ 2∥α−α~∥1+4∥∇(α)−∇(α~)∥1+∥F−F∥1+∥I−αF−(1−α)B′∥1}]
其中, B ˉ \bar{B} Bˉ表示生成器D中看到的合成背景,设置 λ \lambda λ从0.05向每两轮之间衰减 1 2 \frac12 21,使得判别器发挥更重要的作用,尤其是对图像的锐化。
对于判别器来说,也要更新参数,使得一下式子最小化:
min θ D i s c E X , B ˉ ∼ p X , B ˉ [ ( D ( α F + ( 1 − α ) B ˉ ) ) 2 ] + E I ∈ p data [ ( D ( I ) − 1 ) 2 ] \min _{\theta_{\mathrm{Disc}}} \mathbb{E}_{X, \bar{B} \sim p_{X, \bar{B}}}\left[(D(\alpha F+(1-\alpha) \bar{B}))^{2}\right]+\mathbb{E}_{I \in p_{\text {data }}}\left[(D(I)-1)^{2}\right] θDiscminEX,Bˉ∼pX,Bˉ[(D(αF+(1−α)Bˉ))2]+EI∈pdata [(D(I)−1)2]
θ D i s c \theta_{Disc} θDisc代表的是生成器的权重,与 ( F , α ) = G ( X ; θ R e a l ) (F,\alpha) = G(X;\theta_{Real}) (F,α)=G(X;θReal)中的含义相同
在后处理过程中,设置 α \alpha α的阈值为 α > 0.05 \alpha > 0.05 α>0.05并提取前N个最大的相连组间,为每一个不在这些组间中的像素将 α \alpha α值设置为0。其中, N N N是图像中不相交的人物分割的数量。
对生成器与判别器部分的网络结构解析
如下图所示:

首先输入还是和之前的格式一样,首先是用生成器网络 G R e a l G_{Real} GReal和初始网络 G A d o b e G_{Adobe} GAdobe分别生成前景 F F F和系数 α \alpha α,通过对比两个生成器的 F F F和 α \alpha α进行参数调整。
接着使用背景图 B ˉ \bar{B} Bˉ与生成器生成的 F F F和 α \alpha α通过合成公式生成图像,在经过判别器(Discriminator)进行判断,通过自监督对抗损失(Self-Supervised Adversarial Loss)进行优化。