分布式事务中间件 Fescar - 全局写排它锁解读

? Photo by Patrick Fore on Unsplash
看 Fescar 源码费劲?来看看这篇源码解读。
通常情况下,数据库事务的隔离级别会被设置成读已提交(已满足业务需求,这样对应在 Fescar 中的分支(本地)事务的隔离级别就是读已提交)。那么 Fescar 中,对于全局事务的隔离级别又是什么呢?如果之前看过 分布式事务中间件Fescar-RM模块源码解读 的同学应该能推断出来:Fescar 将全局事务的默认隔离定义成读未提交。对于读未提交隔离级别对业务的影响,想必大家都比较清楚,会读到脏数据,经典的就是银行转账例子,出现数据不一致的问题。而对于 Fescar,如果没有采取任何其它技术手段,那会出现很严重的问题,比如:
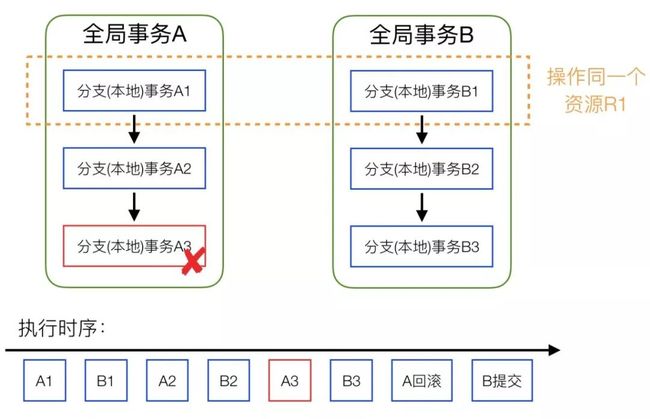
如上图所示,问最终全局事务A对资源R1应该回滚到哪种状态?
很明显,如果再根据 UndoLog 去做回滚,就会发生严重问题:覆盖了全局事务B对资源R1的变更。那 Fescar 是如何解决这个问题呢?答案就是 Fescar 的全局写排它锁解决方案,在全局事务A执行过程中全局事务B会因为获取不到全局锁而处于等待状态。
对于 Fescar 的隔离级别,引用官方的一段话来作说明:
全局事务的隔离性是建立在分支事务的本地隔离级别基础之上的。
在数据库本地隔离级别 读已提交 或以上的前提下,Fescar 设计了由事务协调器维护的 全局写排他锁,来保证事务间的 写隔离,将全局事务默认定义在 读未提交 的隔离级别上。
我们对隔离级别的共识是:绝大部分应用在 读已提交 的隔离级别下工作是没有问题的。而实际上,这当中又有绝大多数的应用场景,实际上工作在 读未提交 的隔离级别下同样没有问题。
在极端场景下,应用如果需要达到全局的 读已提交,Fescar 也提供了相应的机制来达到目的。默认,Fescar 是工作在 读未提交 的隔离级别下,保证绝大多数场景的高效性。
本文将深入到源码层面对 Fescar 全局写排它锁实现方案进行解读。Fescar 全局写排它锁实现方案在 TC(Transaction Coordinator) 模块维护,RM(Resource Manager) 模块会在需要锁获取全局锁的地方请求 TC 模块以保证事务间的写隔离,下面就分成两个部分介绍:TC - 全局写排它锁实现方案、RM - 全局写排它锁使用。
TC - 全局写排他琐实现方案
首先看一下TC模块与外部交互的入口,下图是TC模块的main函数:
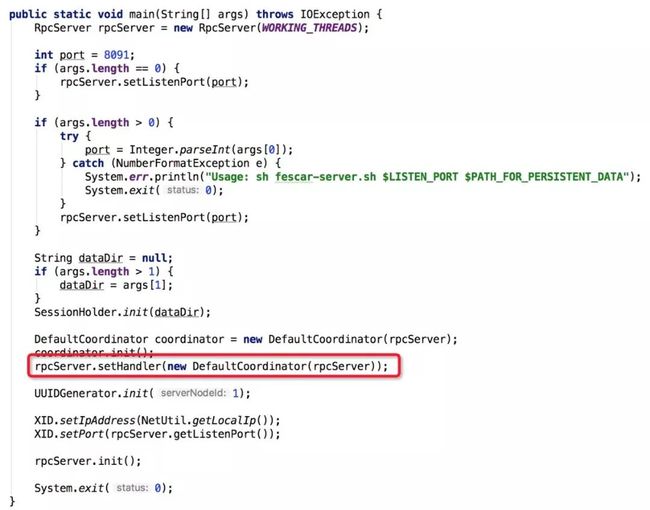
上图中看出RpcServer处理通信协议相关逻辑,而对于TC模块真实处理器是DefaultCoordiantor,里面包含了所有TC对外暴露的功能,比如doGlobalBegin(全局事务创建)、doGlobalCommit(全局事务提交)、doGlobalRollback(全局事务回滚)、doBranchReport(分支事务状态上报)、doBranchRegister(分支事务注册)、doLockCheck(全局写排它锁校验)等,其中doBranchRegister、doLockCheck、doGlobalCommit就是全局写排它锁实现方案的入口。
/*** 分支事务注册,在注册过程中会获取分支事务的全局锁资源*/@Overrideprotected void doBranchRegister(BranchRegisterRequest request, BranchRegisterResponse response, RpcContext rpcContext) throws TransactionException { response.setTransactionId(request.getTransactionId()); response.setBranchId(core.branchRegister(request.getBranchType(), request.getResourceId(), rpcContext.getClientId(), XID.generateXID(request.getTransactionId()), request.getLockKey()));}/*** 校验全局锁能否被获取到*/@Overrideprotected void doLockCheck(GlobalLockQueryRequest request, GlobalLockQueryResponse response, RpcContext rpcContext) throws TransactionException { response.setLockable(core.lockQuery(request.getBranchType(), request.getResourceId(), XID.generateXID(request.getTransactionId()), request.getLockKey()));}/*** 全局事务提交,会将全局事务下的所有分支事务的锁占用记录释放*/@Overrideprotected void doGlobalCommit(GlobalCommitRequest request, GlobalCommitResponse response, RpcContext rpcContext)throws TransactionException { response.setGlobalStatus(core.commit(XID.generateXID(request.getTransactionId())));}上述代码逻辑最后会被代理到DefualtCore去做执行。
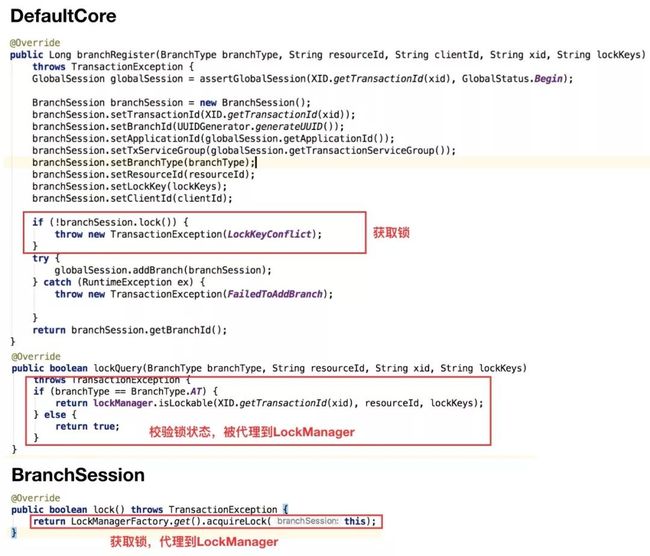
如上图,不管是获取锁还是校验锁状态逻辑,最终都会被LockManger所接管,而LockManager的逻辑由DefaultLockManagerImpl实现,所有与全局写排它锁的设计都在DefaultLockManagerImpl中维护。
首先来看一下全局写排它锁的结构:
private static final ConcurrentHashMap>>> LOCK_MAP = new ConcurrentHashMap<~>(); 
整体上,锁结构采用Map进行设计,前半段采用ConcurrentHashMap,后半段采用HashMap,最终其实就是做一个锁占用标记:在某个ResourceId(数据库源ID)上某个Tabel中的某个主键对应的行记录的全局写排它锁被哪个全局事务占用。下面,我们来看一下具体获取锁的源码:

如上图注释,整个acquireLock逻辑还是很清晰的,对于分支事务需要的锁资源,要么是一次性全部成功获取,要么全部失败,不存在部分成功部分失败的情况。通过上面的解释,可能会有两个疑问:
1、为什么锁结构前半部分采用ConcurrentHashMap,后半部分采用HashMap?
前半部分采用ConcurrentHashMap好理解:为了支持更好的并发处理;疑问的是后半部分为什么不直接采用ConcurrentHashMap,而采用HashMap呢?可能原因是因为后半部分需要去判断当前全局事务有没有占用PK对应的锁资源,是一个复合操作,即使采用ConcurrentHashMap还是避免不了要使用Synchronized加锁进行判断,还不如直接使用更轻量级的HashMap。
2、为什么BranchSession要存储持有的锁资源?
这个比较简单,在整个锁的结构中未体现分支事务占用了哪些锁记录,这样如果全局事务提交时,分支事务怎么去释放所占用的锁资源呢?所以在BranchSession保存了分支事务占用的锁资源。
下图展示校验全局锁资源能否被获取逻辑:
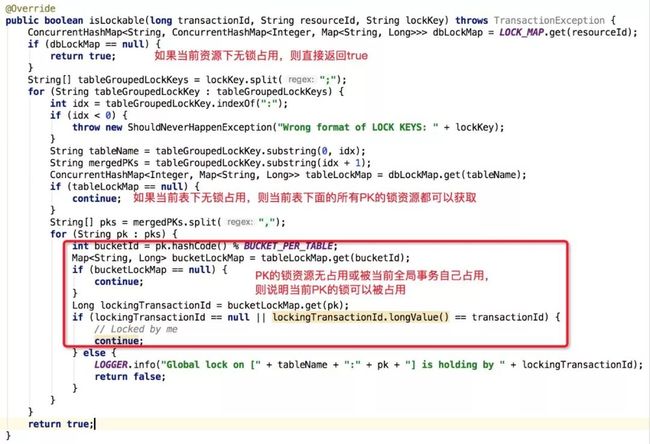
下图展示分支事务释放全局锁资源逻辑:
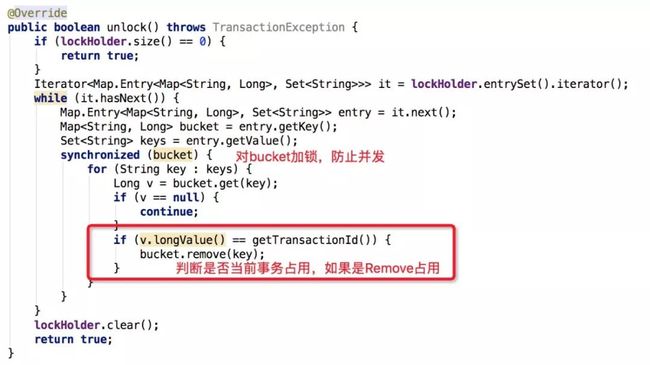
以上就是TC模块中全局写排它锁的实现原理:在分支事务注册时,RM会将当前分支事务所需要的锁资源一并传递过来,TC获取负责全局锁资源的获取(要么一次性全部成功,要么全部失败,不存在部分成功部分失败);在全局事务提交时,TC模块自动将全局事务下的所有分支事务持有的锁资源进行释放;同时,为减少全局写排它锁获取失败概率,TC模块对外暴露了校验锁资源能否被获取接口,RM模块可以在在适当位置加以校验,以减少分支事务注册时失败概率。
RM - 全局写排他琐使用
在RM模块中,主要使用了TC模块全局锁的两个功能,一个是校验全局锁能否被获取,一个是分支事务注册去占用全局锁,全局锁释放跟RM无关,由TC模块在全局事务提交时自动释放。分支事务注册前,都会去做全局锁状态校验逻辑,以保证分支注册不会发生锁冲突。
在执行Update、Insert、Delete语句时,都会在sql执行前后生成数据快照以组织成UndoLog,而生成快照的方式基本上都是采用Select...For Update形式,RM尝试校验全局锁能否被获取的逻辑就在执行该语句的执行器中:SelectForUpdateExecutor,具体如下图:
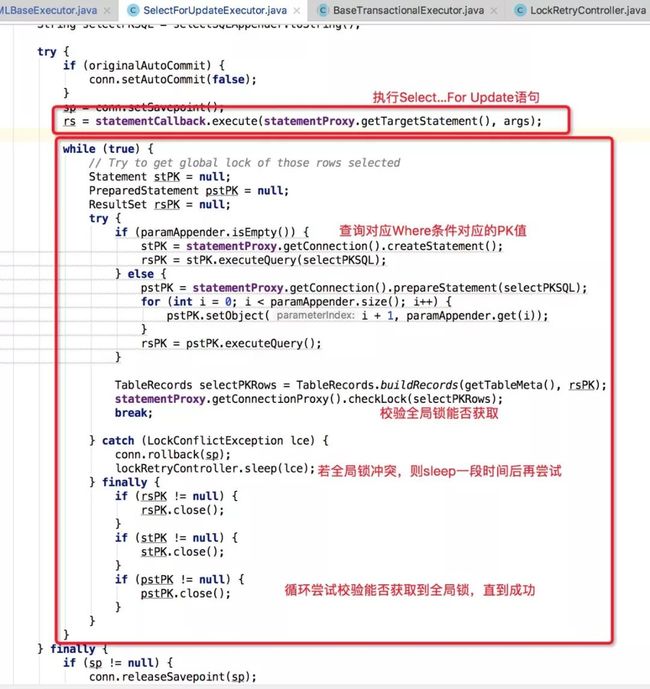

基本逻辑如下:
A. 执行Select ... For update语句,这样本地事务就占用了数据库对应行锁,其它本地事务由于无法抢占本地数据库行锁,进而也不会去抢占全局锁。
B. 循环掌握校验全局锁能否被获取,由于全局锁可能会被先于当前的全局事务获取,因此需要等之前的全局事务释放全局锁资源;如果这里校验能获取到全局锁,那么由于步骤1的原因,在当前本地事务结束前,其它本地事务是不会去获取全局锁的,进而保证了在当前本地事务提交前的分支事务注册不会因为全局锁冲突而失败。
注:细心的同学可能会发现,对于Update、Delete语句对应的UpdateExecutor、DeleteExecutor中会因获取beforeImage而执行Select..For Update语句,进而会去校验全局锁资源状态,而对于Insert语句对应的InsertExecutor却没有相关全局锁校验逻辑,原因可能是:因为是Insert,那么对应插入行PK是新增的,全局锁资源必定未被占用,进而在本地事务提交前的分支事务注册时对应的全局锁资源肯定是能够获取得到的。
接下来,我们再来看看分支事务如何提交,对于分支事务中需要占用的全局锁资源如何生成和保存的。首先,在执行SQL完业务SQL后,会根据beforeImage和afterImage生成UndoLog,与此同时,当前本地事务所需要占用的全局锁资源标识也会一同生成,保存在ContentoionProxy的ConnectionContext中,如下图所示:

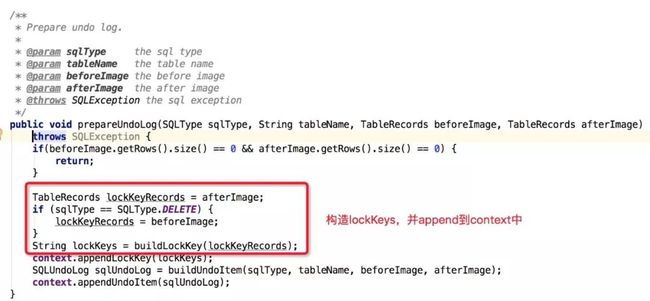
在ContentoionProxy.commit中,分支事务注册时会将ConnectionProxy中的context内保存的需要占用的全局锁标识一同传递给TC进行全局锁的获取。
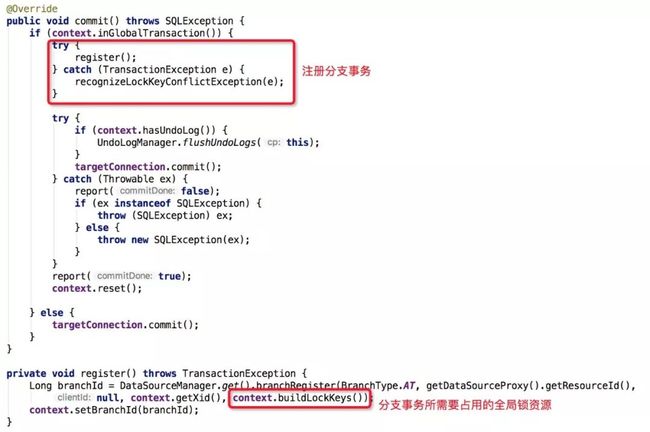
以上,就是RM模块中对全局写排它锁的使用逻辑,因在真正执行获取全局锁资源前会去循环校验全局锁资源状态,保证在实际获取锁资源时不会因为锁冲突而失败,但这样其实坏处也很明显:在锁冲突比较严重时,会增加本地事务数据库锁占用时长,进而给业务接口带来一定的性能损耗。
总结
本文详细介绍了Fescar为在 读未提交 隔离级别下做到 写隔离 而实现的全局写排它锁,包括TC模块内的全局写排它锁的实现原理以及RM模块内如何对全局写排它锁的使用逻辑。在了解源码过程中,笔者也遗留了两个问题:
A. 全局写排它锁数据结构保存在内存中,如果服务器重启/宕机了怎么办,即TC模块的高可用方案是什么呢?
B. 一个Fescar管理的全局事务和一个非Fescar管理的本地事务之间发生锁冲突怎么办?具体问题如下图,问题是:全局事务A如何回滚?
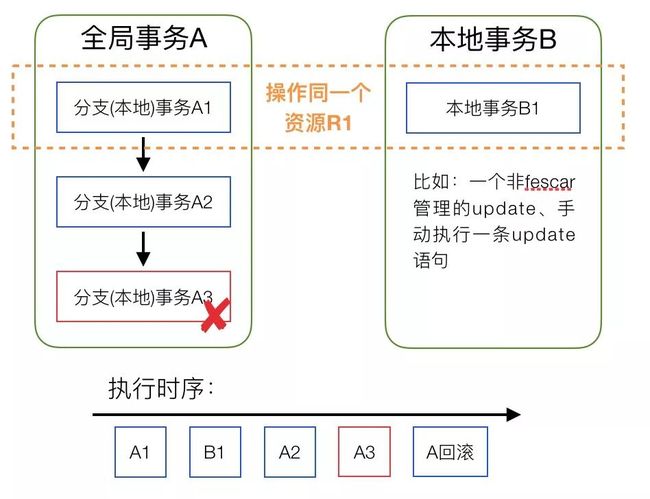
对于问题1有待继续研究;对于问题2目前已有答案,但Fescar目前暂未实现,具体就是全局事务A回滚时会报错,全局事务A内的分支事务A1回滚时会校验afterImage与当前表中对应行数据是否一致,如果一致才允许回滚,不一致则回滚失败并报警通知对应业务方,由业务方自行处理。
参考链接:
Fescar @GitHub:
https://github.com/alibaba/fescar/wiki/
Fescar 琐设计和隔离级别的理解
https://www.jianshu.com/p/4cb127b737cf
Fescar RM模块源码解读
本文作者:王慎波,GitHub ID wangshenbo,阿里巴巴高级开发工程师,专注于供应链平台的研发,对供应链系统中遇到的复杂业务场景的技术解决方案有思考和总结,长期关注分布式系统、分布式事务、领域驱动设计和微服务架构等。
/ 推荐另一篇值得细品的「源码解读」 /

Photo by Hannes Wolf on Unsplash
/ 推荐一个值得参与的「开发者活动」 /

©每周一推
第一时间获得下期分享
☟☟☟

Tips:
# 点下“好看”❤️
# 然后,公众号对话框内发送“雨伞”,试试手气??
# 本期奖品由采购不设限的「淘宝企业服务」赞助 ?