高光谱图像分类
高光谱图像分类
本次作业在阅读完《HybridSN: Exploring 3-D–2-DCNN Feature Hierarchy for Hyperspectral Image Classification》论文后完成。
二维卷积和三维卷积的区别是:二维CNN只能处理高光谱图像的空间信息,并不能处理频谱信息。然而,三维CNN可以同时提取高光谱图像的频谱信息和空间信息,但是三维CNN的代价是大大增加了计算的复杂度。因此,本论文在分析了单独二维CNN和单独三维CNN的特点后,提出了混合式的频谱卷积神经网络(HybridSN),即同时运用三维CNN和二维CNN对高光谱图像进行分类,这样做的目的是既可以提取出高光谱图像的空间信息和频谱信息,同时也不至于计算的复杂度太高。
下面是在colab上运行代码及关键步骤截图:
HybridSN网络部分代码:
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN,self).__init__()
self.conv3d_1=nn.Sequential(
nn.Conv3d(1,8,kernel_size=(7,3,3),stride=1,padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace=True),
)
self.conv3d_2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
self.conv2d = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,16)
self.dropout = nn.Dropout(p = 0.4)
def forward(self,x):
out = self.conv3d_1(x)
out = self.conv3d_2(out)
out = self.conv3d_3(out)
out = self.conv2d(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
测试代码:
count = 0
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
# 生成分类报告
classification = classification_report(ytest, y_pred_test, digits=4)
print(classification)
运行结果:
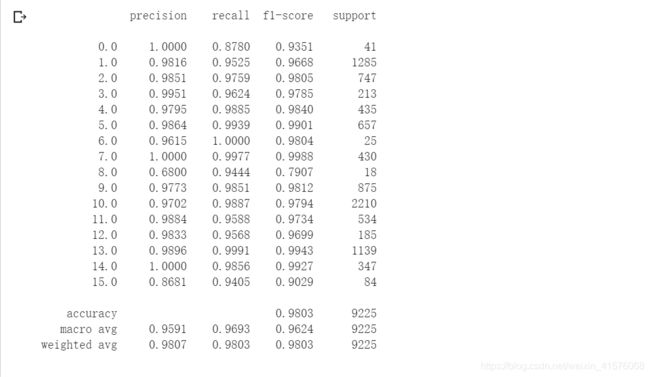
准确率达到了98.03%。关于为什么多次训练网络,会发现每次分类的结果都不一样,是因为网络的全连接层中为了避免过拟合使用了 nn.Dropout(p=0.4),训练模式下是启用 Dropout和BN 层(本例没有)的,网络层的节点会随机失活。原始的代码没有注意到pytorch模型网络的训练模式和测试模式即 net.train() 和 net.eval() (这里net是我们构建的HybirdSN),在测试时仍然采用训练模式,导致每次测试分类结果不一样。如果测试时启用net.eval()就会得到相同的分类结果。
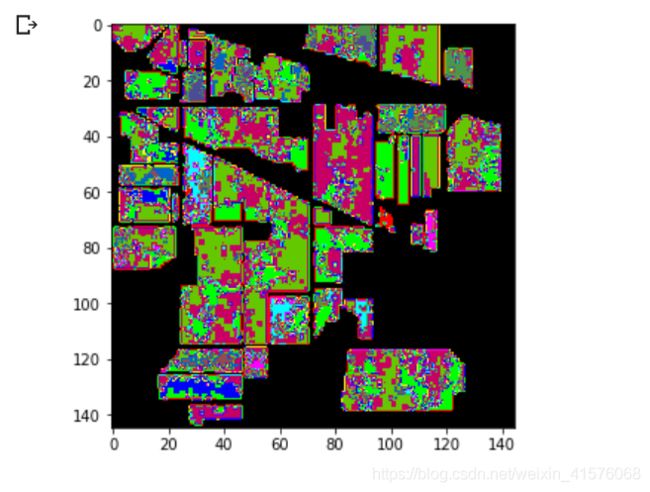
分类结果:
加入注意力机制后:
class_num = 16
# 通道注意力机制
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
# 空间注意力机制
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN,self).__init__()
self.conv3d_1=nn.Sequential(
nn.Conv3d(1,8,kernel_size=(7,3,3),stride=1,padding=0),
nn.BatchNorm3d(8),
nn.ReLU(inplace=True),
)
self.conv3d_2 = nn.Sequential(
nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(16),
nn.ReLU(inplace = True),
)
self.conv3d_3 = nn.Sequential(
nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU(inplace = True)
)
self.conv2d = nn.Sequential(
nn.Conv2d(576, 64, kernel_size=(3, 3), stride=1, padding=0),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
)
self.fc1 = nn.Linear(18496,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,16)
self.dropout = nn.Dropout(p = 0.4)
def forward(self,x):
out = self.conv3d_1(x)
out = self.conv3d_2(out)
out = self.conv3d_3(out)
out = self.conv2d(out.reshape(out.shape[0],-1,19,19))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
# 随机输入,测试网络结构是否通
# x = torch.randn(1, 1, 30, 25, 25)
# net = HybridSN()
# y = net(x)
# print(y.shape)
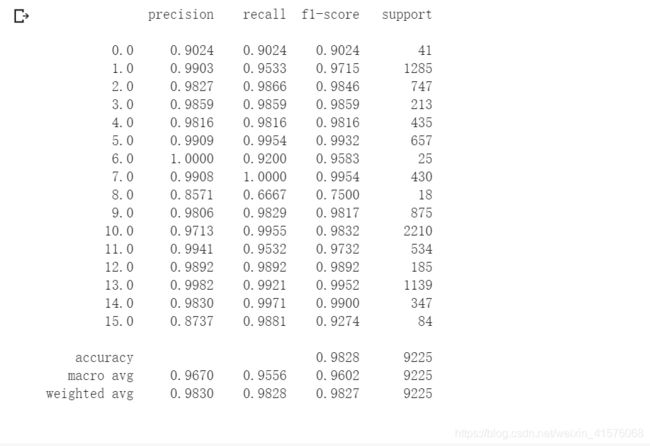
运行结果:
分类结果:
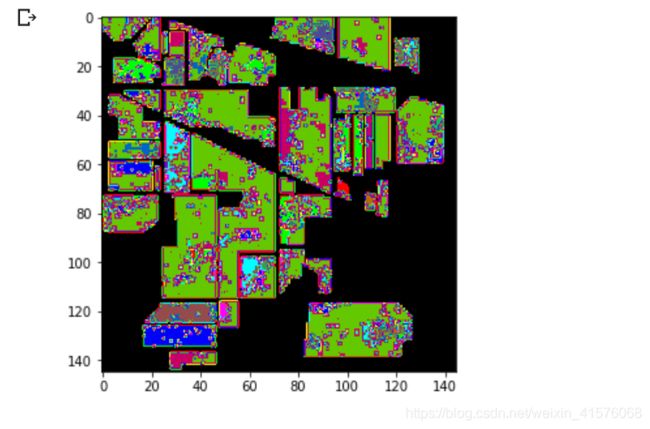
从上图可以看出,加入注意力机制后分类结果有了较明显的提升。因此,如果从维度上考虑,可以从图像空间、通道和光谱的波长三个方向使用注意力机制来处理特征,可能会取得更好的分类效果。
另附阅读的论文:



