推出 RxR:多语言指令跟随导航基准数据集

文 / Alexander Ku,软件工程师和 Peter Anderson,研究员,Google Research
机器学习 (ML) 的一项核心挑战是构建能够在复杂的实际环境中导航,并对口头或书面命令做出响应的代理 (Agents)。虽然如今的代理,包括机器人,通常可以在复杂的环境中导航,但它们还不能理解使用自然语言表达的导航目标,例如,“穿过右侧关闭的棕色双开门,然后站在椅子后面与桌子前面。”
这一挑战被称为视觉-语言导航 (Vision-and-Language Navigation, VLN),它需要对空间语言有深刻的理解。例如,要想识别“椅子后面与桌子前面” 的位置,就需要找到桌子,识别桌子的哪一部分被认为是前侧,找到离桌子前侧最近的椅子,识别这把椅子后面的区域,等等。虽然人们可以轻松理解并遵从上述这类指令,但目前基于 ML 的方法轻松解决很难解决类似挑战,需要一个系统能够更好地将语言与它所描述的物理世界联系起来。
视觉-语言导航
http://openaccess.thecvf.com/content_cvpr_2018/papers/Anderson_Vision-and-Language_Navigation_Interpreting_CVPR_2018_paper.pdf
为了促进该领域的发展,我们很高兴为 VLN 引入新数据集:Room-Across-Room (RxR)。如在 “Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding” 中所述,RxR 是 VLN 的第一个多语言数据集,包含了 126,069 条人工标注的导航指令,它们使用三种不同类型的语言 - 英语、印地语和泰卢固语。
Room-Across-Room
https://github.com/google-research-datasets/RxRRoom-Across-Room:Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding
https://www.aclweb.org/anthology/2020.emnlp-main.356/
每条指令描述一条通过照片级模拟器的路径,模拟器中充满着各种室内环境,它们来自 Matterport3D 数据集,其中包括居所、办公室和公共建筑的 3D 捕捉。为了追踪 VLN 的进展,我们还宣布了 RxR 挑战赛,这是一项鼓励机器学习社区基于 RxR 指令训练和评估他们自己的指令跟随代理的竞赛。
Matterport3D 数据集
https://niessner.github.io/Matterport/RxR 挑战赛
https://ai.google.com/research/rxr
| 语言 | 指令 |
|---|---|
| en-US | Starting next to the long dining room table, turn so the table is to your right.Walk towards the glass double doors.When you reach the mat before the doors, turn immediately left and walk down the stairs.When you reach the bottom of the stairs, walk through the open doors to your left and continue through the art exhibit with the tub to your right hand side.Down the length of the table until you reach the small step at the end of the room before you reach the tub and stop. |
| hi-IN | अभी हमारे बायीं ओर एक बड़ा मेज़ है कुछ कुर्सियाँ हैं और कुछ दीपक मेज़ के ऊपर रखे हैं। उलटी दिशा में घूम जाएँ और सिधा चलें। अभी हमारे दायीं ओर एक गोल मेज़ है वहां से सीधा बढ़ें और सामने एक शीशे का बंद दरवाज़ा है उससे पहले बायीं ओर एक सीढ़ी है उससे निचे उतरें। निचे उतरने के बाद दायीं ओर मुड़े और एक भूरे रंग के दरवाज़े से अंदर प्रवेश करें और सीधा चलें। अभी हमारे दायीं ओर एक बड़ा मेज़ है और दो कुर्सियां राखी हैं सीधा आगे बढ़ें। हमारे सामने एक पानी का कल है और सामने तीन कुर्सियां दिवार के पास रखी हैं यहीं पर ठहर जाएँ। |
| te-IN | ఉన్న చోటు నుండి వెనకకు తిరిగి, నేరుగా వెళ్తే, మీ ముందర ఒక బల్ల ఉంటుంది. దాన్ని దాటుకొని ఎడమవైపుకి తిరిగితే, మీ ముందర మెట్లు ఉంటాయి. వాటిని పూర్తిగా దిగండి. ఇప్పుడు మీ ముందర రెండు తెరిచిన ద్వారాలు ఉంటాయి. ఎడమవైపు ఉన్న ద్వారం గుండా బయటకు వెళ్ళి, నేరుగా నడవండి. ఇప్పుడు మీ కుడివైపున పొడవైన బల్ల ఉంటుంది. దాన్ని దాటుకొని ముందరే ఉన్న మెట్ల వద్దకు వెళ్ళి ఆగండి. |
RxR 数据集中的英语、印地语和泰卢固语导航指令示例,每个导航指令均描述相同的路径
姿态轨迹
除了导航指令和路径外,RxR 还包括一个新的、更详细的多模态标注,称为姿态轨迹 (Pose Traces)。受位置叙述数据集中捕捉的鼠标轨迹的启发,姿态轨迹通过丰富的 3D 设置在语言、视觉和运动之间提供紧密的知识基础 (Dense Groundings)。
为了生成导航指令,我们要求向导 (guide) 标注者在模拟器中沿一条路径移动,同时根据周围环境叙述路径。姿态轨迹是向导沿该路径看到的所有东西的记录,并且与导航指令中的文字在时间上对齐。然后,这些轨迹与跟随者 (follower) 标注者的姿态轨迹配对,后者的任务是通过收听向导的音频来沿着预期路径行进,从而验证导航指令的质量。
姿态轨迹隐式捕获地标选择和视觉显著性概念,并实时表示如何解决导航指令生成任务(对于向导)和导航指令跟随任务(对于跟随者)。

RxR 数据集中的英语导航指令示例。指令文本(右)中的单词经过颜色编码,与姿态轨迹(左)对齐,姿态轨迹显示了向导标注者在描述路径的环境中移动时的动作和视觉感知
视觉显著性
http://www.scholarpedia.org/article/Visual_salience

相同的 RxR 示例,导航指令中的文字沿该路径与 360° 图像对齐。向导标注者观察到的场景部分会高亮显示;标注者忽略的场景部分会淡化。红色和黄色框高亮显示了文本指令与标注者视觉提示之间的一些紧密对齐。红色十字线指示标注者的下一个移动方向
规模
RxR 总共包含近 1000 万个单词,是现有数据集(如 R2R 和 Touchdown/Retouchdown)的约 10 倍大。这很重要,因为与基于静态图像和文本数据的任务相比,需要通过运动或与环境的互动来学习的语言任务通常缺乏大规模训练数据。RxR 还解决了其他数据集(例如 R2R)中出现的已知路径构造偏差,此数据集中的所有路径都具有相似的长度,并且采用最短的路线到达目标。相比之下,RxR 中的路径平均长度更长,更不可预测,这使得它们更难以跟随,并鼓励在数据集中训练的模型更加强调语言在任务中的作用。RxR 的规模、范围和细节将扩展落地语言学习研究的领域,同时削弱英语等资源丰富的语言的主导地位。
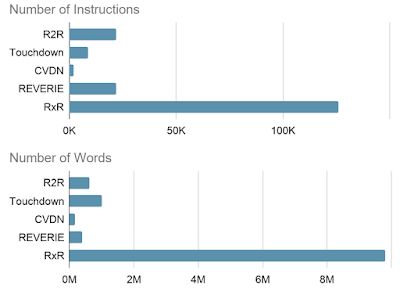
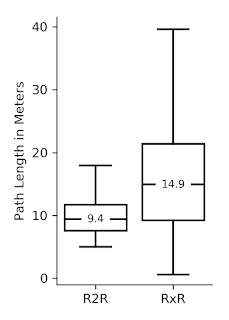
左:RxR 比现有的类似数据集大一个数量级;右:与 R2R 相比,RxR 中的路径通常更长,更不可预测,这使得它们更难以跟随
R2R
https://bringmeaspoon.org/Touchdown
https://github.com/lil-lab/touchdownRetouchdown
https://ai.googleblog.com/2020/02/enhancing-research-communitys-access-to.html
基准模型
为了更好地表现和理解 RxR 数据集,我们使用开源框架 VALAN 和 multilingual BERT 模型的语言表示,在 RxR 上训练了各种代理 (Agents)。我们发现,在训练过程中包含跟随者标注和向导标注可以改善结果,并且独立训练的单语言代理的表现优于单个多语言代理。
VALAN
https://github.com/google-research/valanmultilingual BERT
https://github.com/google-research/bert/blob/master/multilingual.md
从概念上讲,这些代理的评估很直接—代理是否跟随了预期路径?从经验上讲,我们使用 NDTW 测量 VLN 代理采用的路径与参考路径之间的相似度,NDTW 是路径保真度的标准化度量,范围为 100(完全一致)到 0(完全错误)。所有三种语言的跟随者标注者的平均得分是 79.5,这是由类似路径之间的自然变化所致。相比之下,最佳模型(三个独立训练的单语言代理的组合,每种语言一个代理)在 RxR 测试集上获得的 NDTW 得分是 41.5。虽然这比随机 (15.4) 要好得多,但仍然远远低于人类的表现。虽然语言建模方面的进步继续迅速侵蚀着 GLUE 和 SuperGLUE 等纯文本语言理解基准模型改进空间的价值,但是像 RxR 这样将语言与物理世界联系起来的基准却提供了巨大的改进空间。
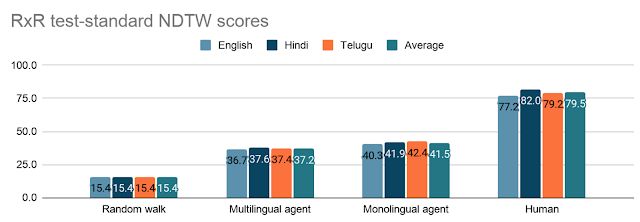
我们的多语言和单语言指令跟随代理在 RxR 测试标准分块上的结果。虽然表现比随机行走要好得多,但在此项任务上仍有相当大的改进空间来达到人类的表现
挑战竞赛
为了鼓励在这一领域进行进一步研究,我们发起了 RxR 挑战赛,这是一项机器学习社区正在举行的竞赛,旨在开发能够跟随自然语言导航指令的计算代理。要参加此项竞赛,参与者需要上传他们的代理根据提供的 RxR 测试指令所采用的导航路径。在最困难的情况下(这里和论文中有报告),所有测试环境都是前所未见的。但是,我们也允许代理预先在测试环境中进行训练或探索。有关详情和最新结果,请访问挑战赛网站。
RxR 挑战赛/挑战赛网站
https://ai.google.com/research/rxr论文
https://www.aclweb.org/anthology/2020.emnlp-main.356/
PanGEA
我们还将发布基于网络的自定义标注工具,该工具是我们为收集 RxR 数据集而开发的。Panoramic Graph Environment Annotation 工具包 (PanGEA) 是一个轻量级、可自定义的代码库,用于收集 Matterport3D 和 StreetLearn 等全景图环境中的语音和文本标注。它包括语音记录和虚拟姿态跟踪,以及用于将生成的姿态轨迹与人工转录对齐的工具。有关详情,请访问 PanGEA GitHub 页面。
Matterport3D
https://niessner.github.io/Matterport/StreetLearn
https://sites.google.com/corp/view/streetlearnPanGEA GitHub 页面
https://github.com/google-research/pangea
致谢
感谢 Roma Patel、Eugene Ie 和 Jason Baldridge 对这项研究的贡献。我们还要感谢所有标注者,感谢 Sneha Kudugunta 对泰卢固语标注的分析,感谢 Igor Karpov、Ashwin Kakarla 和 Christina Liu 为这个项目提供的工具和标注支持,感谢 Austin Waters 和 Su Wang 为图像特征提供的帮助,感谢 Daphne Luong 对数据收集的行政支持。
更多 AI 相关阅读:
利用 AutoML 进行时间序列预测
大型语言模型中的隐私考量
推出 Pr-VIPE:识别图像和视频中的姿态相似度
基于端到端可迁移深度强化学习的图优化
智能滚动:让转录后的文本编辑、共享和搜索更容易
![]()
