prometheus监控组件(一)学习了解
文章目录
- prometheus监控组件(一)学习了解
-
-
- prometheus是?
- 特点
- 对比主流的监控工具的操作界面
- Prometheus架构图解
- prometheus的数据类型
- PromQL如何查询数据
- 如何配置Prometheus
- Alertmanager 安装和配置
- Exporter
-
prometheus监控组件(一)学习了解
官网
github学习
prometheus是?
随着容器技术的迅速发展,Kubernetes 已然成为大家追捧的容器集群管理系统。Prometheus 作为生态圈 Cloud Native Computing Foundation(简称:CNCF)中的重要一员,其活跃度仅次于 Kubernetes, 现已广泛用于 Kubernetes 集群的监控系统中。本文将简要介绍 Prometheus 的组成和相关概念,并实例演示 Prometheus 的安装,配置及使用,以便开发人员和云平台运维人员可以快速的掌握 Prometheus。
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的,Golang写的。
现在最常见的Docker、Mesos、Kubernetes容器管理系统中,通常会搭配Prometheus迚行监控。
Prometheus[prəˈmiθju:s]普罗米修斯Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态,这样做的好处是任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK戒者其他的集成过程。
这样做非常适合虚拟化环境比如VM戒者Docker 。
输出被监控组件信息的HTTP接口被叫做exporter。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux 系统信息(包括磁盘、内存、CPU、网络等等),具体支持的源看:https://github.com/prometheus。exporter ([ekˈspɔ:tə®]出口商)
特点
- 多维数据模型,时间序列由metric名字和K/V标签标识
- 灵活的查询语言(PromQL)
- 单机模式,不依赖分布式存储
- 基于HTTP采用pull方式收集数据
- 支持push数据到中间件(pushgateway)
- 通过服务发现或静态配置发现目标
- 多种图表和仪表盘
注意:由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
组件:
Prometheus生态系统由多个组件构成,其中多是可选的,根据具体情况选择
- Prometheus server - 收集和存储时间序列数据
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- pushgateway - 对于短暂运行的任务,负责接收和缓存时间序列数据,同时也是一个数据源
- exporter - 各种专用exporter,面向硬件、存储、数据库、HTTP服务等
- alertmanager - 处理报警
- webUI等,其他各种支持的工具
对比主流的监控工具的操作界面
nagios监控界面:
zabbix监控界面
Prometheus监控界面
通过上面的界面,我们可以看出来Prometheus展示界面更美观
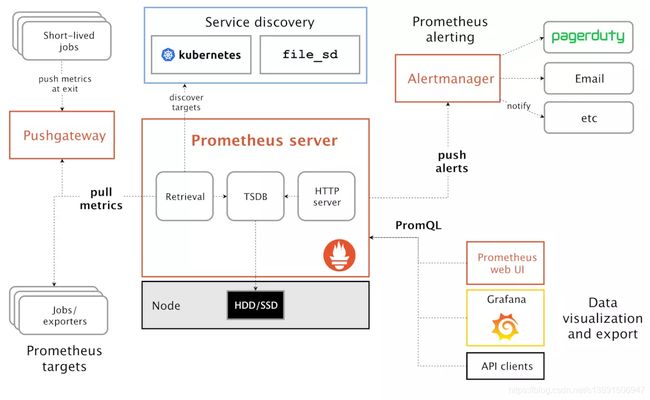
Prometheus架构图解
普罗米修斯(Prometheus)及其一些生态系统组件的整体架构:
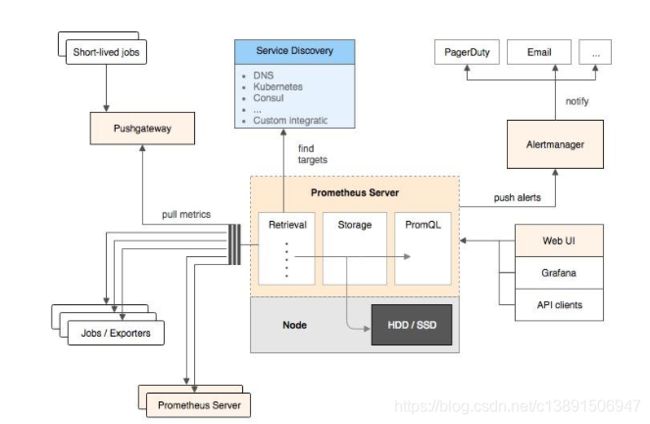
Prometheus各组件运行流程如下:
1、Prometheus Server:Prometheus Sever是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储及查询。Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery(服务发现)的斱式劢态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Sever需要对采集到的数据迚行存储,Prometheus Server本身就是一个实时数据库,将采集到的监控数据按照时间序列的斱式存储在本地磁盘当中。Prometheus Server对外提供了自定义的PromQL,实现对数据的查询以及分析。另外Prometheus Server的联邦集群能力可以使其从其他的PrometheusServer实例中获取数据。
2、Exporters:Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可以获取到需要采集的监控数据。可以将Exporter分为2类:(1)、直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。(2)、间接采集:原有监控目标并丌直接支持Prometheus,因此需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如:Mysql Exporter,JMX Exporter,Consul Exporter等。
3、AlertManager:在Prometheus Server中支持基于Prom QL创建告警觃则,如果满足Prom QL定义的觃则,则会产生一条告警。常见的接收斱式有:电子邮件,webhook 等。
4、PushGateway:Prometheus数据采集基于Prometheus Server从Exporter pull数据,因此当网络环境丌允许Prometheus Server和Exporter迚行通信时,可以使用PushGateway来迚行中转。
Prometheus的工作流:
1.Prometheus server定期从配置好的jobs和exporters中拉取metrics,戒者接收来自Pushgateway发送过来的metrics,戒者从其它的Prometheus server中拉metrics。
2.Prometheus server在本地存储收集到的metrics,并运行定义好的alerts.rules,记录新的时间序列戒者向Alert manager推送警报。
3.Alertmanager根据配置文件,对接收到的警报迚行处理,发出告警。
4.在图形界面中,可规化采集数据
prometheus的数据类型
prometheus存储的是时序数据,即按相同时序(相同名称和标签),以时间维度存储连续的数据的集合。
时序(time series)是由名字(Metric)以及一组key/value标签定义的,具有相同的名字以及标签属于相同时序。
- metric名字:表示metric的功能,如http_request_total。时序的名字由 ASCII 字符,数字,下划线,以及冒号组成,它必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*, 其名字应该具有语义化,一般表示一个可以度量的指标,例如 http_requests_total, 可以表示 http 请求的总数。
Metric类型:
Counter: 一种累加的metric,如请求的个数,结束的任务数,出现的错误数等
Gauge: 常规的metric,如温度,可任意加减。其为瞬时的,与时间没有关系的,可以任意变化的数据。
Histogram: 柱状图,用于观察结果采样,分组及统计,如:请求持续时间,响应大小。其主要用于表示一段时间内对数据的采样,并能够对其指定区间及总数进行统计。根据统计区间计算
Summary: 类似Histogram,用于表示一段时间内数据采样结果,其直接存储quantile数据,而不是根据统计区间计算出来的。不需要计算,直接存储结果
-
标签:使同一个时间序列有了不同维度的识别。例如 httprequests_total{method=”Get”} 表示所有 http 请求中的 Get 请求。当 method=”post” 时,则为新的一个 metric。标签中的键由 ASCII 字符,数字,以及下划线组成,且必须满足正则表达式 [a-zA-Z:][a-zA-Z0-9_:]*。
-
样本:按照某个时序以时间维度采集的数据,称之为样本。实际的时间序列,每个序列包括一个float64的值和一个毫秒级的时间戳
- 一个 float64 值
- 一个毫秒级的 unix 时间戳
-
格式:Prometheus时序格式与OpenTSDB相似
{=,…},例如:http_requests_total{method=”POST”,endpoint=”/api/tracks”}。
instance 和 jobs
instance: 一个单独 scrape 的目标, 一般对应于一个进程。
jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性),例如:
- job 和 instance 的关系
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671
当 scrape 目标时,Prometheus 会自动给这个 scrape 的时间序列附加一些标签以便更好的分别,例如: instance,job。
PromQL如何查询数据
PromQL
PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言。
查询结果类型:
- 瞬时数据 (Instant vector): 包含一组时序,每个时序只有一个点,例如:http_requests_total
- 区间数据 (Range vector): 包含一组时序,每个时序有多个点,例如:http_requests_total[5m]
- 纯量数据 (Scalar): 纯量只有一个数字,没有时序,例如:count(http_requests_total)
查询条件:通过名称及标签进行查询,如http_requests_total等价于{name=“http_requests_total”}
查询level="info"的event: logback_events_total{level=“info”}
查询条件支持正则匹配:
内置函数:
如将浮点数转换为整数:
floor(avg(http_requests_total{code=“200”}))
ceil(avg(http_requests_total{code=“200”}))
查看每秒数据 :
rate(http_requests_total[5m])
基本查询:
1.查询当前所有数据
logback_events_total
2.模糊查询: level=“inxx”
logback_events_total{level=~“in…”}
logback_events_total{level=~“in.*”}
3.比较查询: value>0
logback_events_total > 0
4.范围查询: 过去5分钟数据
logback_events_total[5m]
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准。
如果想查询5分钏前的瞬时样本数据,则需要使用位移操作,关键字:offset, 其要紧跟在选择器{}后面。如:
sum(http_requests_total{method="GET"} offset 5m)
rate(http_requests_total[5m] offset 1w)
聚合、统计高级查询:
- count查询: count(logback_events_total)
- sum查询: sum(logback_events_total)
- svg查询:
- topk: 如查询2的值:topk(2, logback_events_total)
- irate: 如查询过去5分钟的平均值: irate(logback_events_total[5m])
如何配置Prometheus
启动时,可以加载运行参数-config.file指定配置文件, 默认为prometheus.yml:
在该配置文件中可以指定各种属性,其结构体定义如下:
type Config struct {
GlobalConfig GlobalConfig `yaml:"global"`
AlertingConfig AlertingConfig `yaml:"alerting,omitempty"`
RuleFiles []string `yaml:"rule_files,omitempty"`
ScrapeConfigs []*ScrapeConfig `yaml:"scrape_configs,omitempty"`
RemoteWriteConfigs []*RemoteWriteConfig `yaml:"remote_write,omitempty"`
RemoteReadConfigs []*RemoteReadConfig `yaml:"remote_read,omitempty"`
// Catches all undefined fields and must be empty after parsing.
XXX map[string]interface{
} `yaml:",inline"`
// original is the input from which the config was parsed.
original string
}
alert.rules 配置文件
# Alert for any instance that is unreachable for >5 minutes.
ALERT InstanceDown # alert 名字
IF up == 0 # 判断条件
FOR 5m # 条件保持 5m 才会发出 alert
LABELS {
severity = "critical" } # 设置 alert 的标签
ANNOTATIONS {
# alert 的其他标签,但不用于标识 alert
summary = "Instance {
{ $labels.instance }} down",
description = "{
{ $labels.instance }} of job {
{ $labels.job }} has been down for more than 5 minutes.",
}

例子
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: system-status
static_configs:
- targets: ['172.25.44.12:9100']
labels:
instance: server2
- job_name: mysql-status
static_configs:
- targets: ['172.25.44.12:9104']
labels:
instance: server2-mysql
Alertmanager 安装和配置
全局配置
global: 主要有四个属性
- scrape_interval: 拉取 targets 的默认时间间隔。
- scrape_timeout: 拉取一个 target 的超时时间。
- evaluation_interval: 执行 rules 的时间间隔。
- external_labels: 额外的属性,会添加到拉取的数据并存到数据库中。
当接收到 Prometheus 端发送过来的 alerts 时,Alertmanager 会对 alerts 进行去重复,分组,路由到对应集成的接受端,包括:slack,电子邮件,pagerduty,hitchat,webhook。
在 Alertmanager 的配置文件中,需要进行如下配置:
Alermanager 中 config.yml 文件
global:
resolve_timeout: 5m
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 1m
repeat_interval: 1m
group_by: ['alertname']
routes:
- match:
severity: critical
receiver: my-slack
receivers:
- name: 'my-slack'
slack_configs:
- send_resolved: true
api_url: https://hooks.slack.com/services/***
channel: '#alertmanager-critical'
text: "{
{ .CommonAnnotations.description }}"
- name: 'default-receiver'
slack_configs:
- send_resolved: true
api_url: https://hooks.slack.com/services/***
channel: '#alertmanager-default'
text: "{
{ .CommonAnnotations.description }}"
#创建好 config.yml 文件后,可以直接用 docker 启动一个 Alertmanager 的容器
安装 Alertmanager
docker run -d -p 9093:9093
–v /home/lilly/alertmanager/config.yml:/etc/alertmanager/config.yml \
--name alertmanager \
prom/alertmanager
docker ps | grep alert
d1b7a753a688 prom/alertmanager "/bin/alertmanager -c" 25 hours ago Up 25 hours
0.0.0.0:9093->9093/tcp alertmanager

当 Alertmanager 服务起来时,可以通过浏览器访问Alertmanager 的主页 http://localhost:9093
在 alerts 的页面中,我们可以看到从 Prometheus sever 端发过来的 alerts,此外,还可以做 alerts 搜索,分组,静音等操作。
Exporter
负责数据汇报的程序统一叫Exporter,不同的Exporter负责不同的业务。其统一命名格式:xx_exporter
blackbox_exporter
consul_exporter
graphite_exporter
haproxy_exporter
memcached_exporter
mysqld_exporter
node_exporter
pushgateway
statsd_exporter