什么是Transformer?| 小白深度学习入门

小白深度学习入门系列
1. 直观理解深度学习基本概念
2. 白话详解ROC和AUC
3. 什么是交叉熵
4. 神经网络的构成、训练和算法
5. 深度学习的兴起:从NN到DNN
6. 异军突起的激活函数:ReLU
7. CNN,RNN,LSTM都是什么?
什么是Transformer
Transformer是什么?一句话来讲,就是完全利用attention机制来解决自然语言翻译问题。
当然这说了跟没说一样,attention机制也许大家知道,但attention何德何能,能干掉良好运行多年的RNN/LSTM呢?也许我们可以通过内窥Transformer的架构来解释这个问题。
Transformer的结构
先来看结构,Transformer总体分为encoder和decoder部分,每块各有多个层。
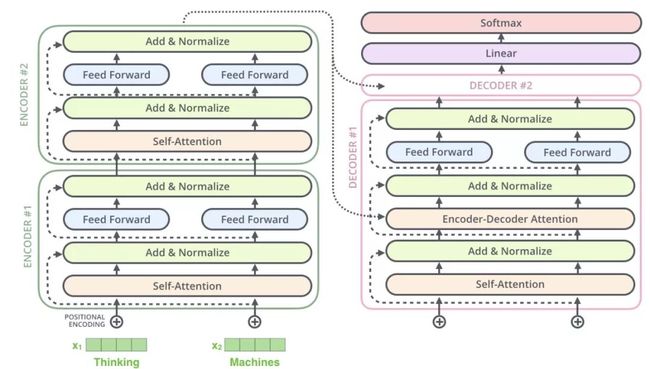
encoder里的每层有self attention和feed forward两层。其中encoder输入是n个词向量,n是输入最长的句子里单词数量。
decoder的输出则是类似传统的seq2seq结构,是一个一个目标语言的单词。
Self Attention
self attention究竟什么意思?很简单,self attention假设:一个句子中每个单词的含义,都部分取决于该句子里其他词。
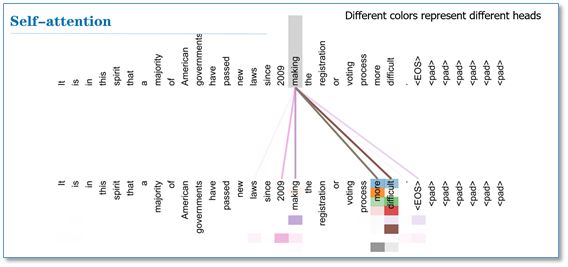
这听着像是废话,但如果我们想用词向量来表示一个词,那很直观我们可以得出,一个句子中的一个词向量,他的计算是依赖于该句子的其他词向量的。
那具体怎么计算每个词向量呢?这个计算过程就是self attention encoding的目的,即,将句子中每个原始词向量按照attention加权相加,求出新的词向量。
Attention加权相加
attention加权相加又是什么意思?句子里每个词(包括目标词自己)都对目标词有一个attention(这是个标量,即权重a),同时每个词都有自己的一个词向量表示(这个向量我们用V表示)。
每个V是靠着这个简单的word embedding过程得来的。那么每个a怎么来的?
因为这个a是表示当前attention的词对目标词权重,那很直观的,这个a值应该只凭当前词和目标词关系算出来。
怎么算呢?我们假设目标词本身有个向量(即下图中的q),而句子中每个词有个专门用来算别的词的向量(即下图中的k),这俩都是word embedding得到的。
它俩(q和k)一乘,就得到当前词对目标词的权重a(即下图中的q x k,它是一个向量,不同的值对应不同颜色的竖线,蓝色表示整数,蓝色越深则值越大,橘色表示复数,颜色越深则值越小)。
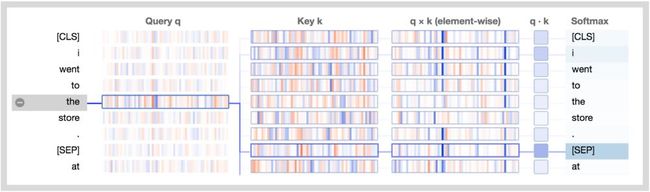
得到了所有词对目标词的权重之后,还有个问题,这些权重加起来应该等于1。于是我们在权重计算之后套一个softmax,解决问题。
Multi-heading
那什么是multi-heading?multi-heading就是同样这个取新词向量Z的事儿,咱们干8遍,得到Z1 ~ Z8。
得到这8个值之后,将每个词的所有Z连在一起,粘成一个巨大的词向量。这个词向量作为后续feed forward层的输入。可以说是相当简单粗暴了。
Position Encoding
咱们刚才聊了这么多,有个问题一直忽略了——这个模型只知道词和词之间的影响力,但它根本没考虑这些词的顺序。顺序多么重要,怎么可能不在考虑范围内!
Transformer解决的方法也是很直白,你不是不知道位置信息吗?好,我给你每个词都加上一个位置信息。这就是Position Encoding!
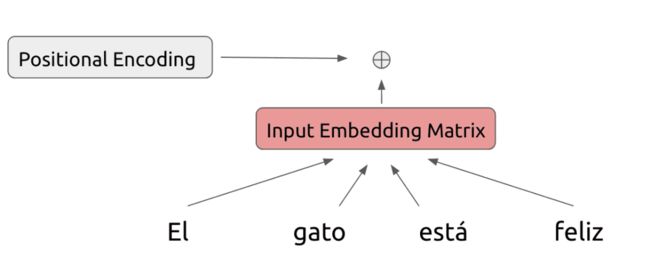
注意,这个加是在原有词向量上叠加一个同维度表示位置的向量,不是粘在后边。
这个位置向量怎么生成?论文里写了算法,这里不展开,感兴趣同学可以去看。关于这个方法的直观理解是什么呢?文章里这句话有意思了,大家仔细读读:
The intuition here is that adding these values to the embeddings provides meaningful distances between the embedding vectors once they’re projected into Q/K/V vectors and during dot-product attention.
什么意思呢?就是说原本在高维空间里,词向量之间都是以原点为起点的向量,现在通过这种方法,让词向量之间产生了距离。
也就是,一句话里的各个词向量通过这种方法,实际上组成了一个高维的像蛇一样的线段,而这条高维空间的“蛇”就表示这句话本身。
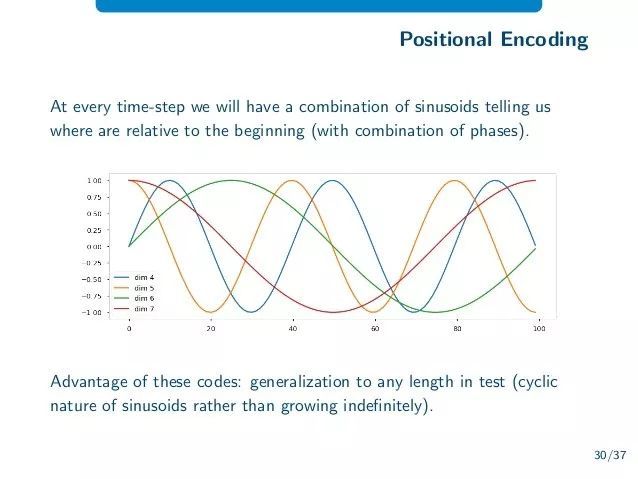
是不是挺有创意的?
“众智汇”愿景
尽职尽才,允公允能 —— 本社群不定期举行线上分享,组织群友分享知识、经验、资源,以达到让我们每个人的职业生涯得到最大程度的发展的目的。
欢迎扫面下列二维码关注“悦思悦读”公众微信号
