爬虫学习(9):正则爬取jk妹子头像,不要滑走!
效果:

代码可以直接用,不用修改,但是希望大家能通过这个例子能够学到正则的使用:
import requests
import re
import urllib.request
import time
import os
header={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
url='https://cn.bing.com/images/async?q=jk%E5%88%B6%E6%9C%8D%E5%A5%B3%E7%94%9F%E5%A4%B4%E5%83%8F&first=118&count=35&relp=35&cw=1177&ch=705&tsc=ImageBasicHover&datsrc=I&layout=RowBased&mmasync=1&SFX=4'
request=requests.get(url=url,headers=header)
c=request.text
pattern=re.compile(
r'.*?src="(.*?)".*?',re.S
)
items = re.findall(pattern, c)
# print(items)
os.makedirs('E://photo/',exist_ok=True)
for a in items:
print(a)
for a in items:
print("下载图片:"+a)
b=a.split('/')[-1]
urllib.request.urlretrieve(a,'E://photo/'+str(int(time.time()))+'.jpg')
print(a+'.jpg')
time.sleep(2)
总结下问题:我通过正则爬取,以为这是静态的,实际上这是动态网页,所以这种方式并没有全部爬取下来,估计全部爬下来应该有几千张,准备换新的方法进行爬取。
对python感兴趣的哥们,可以跟我一起交流,群970353786我也正在努力学习中,后续动态爬取我再想想吧…待更新
如果你看不懂我这篇文章写的代码,先去看看我前面的爬虫文章吧,我是一点一点的学啥用啥爬取的,正则表达式怎么用也上一篇文章。
wait!!!Wait!!!换一个方式来,就在这更新了!!放图!
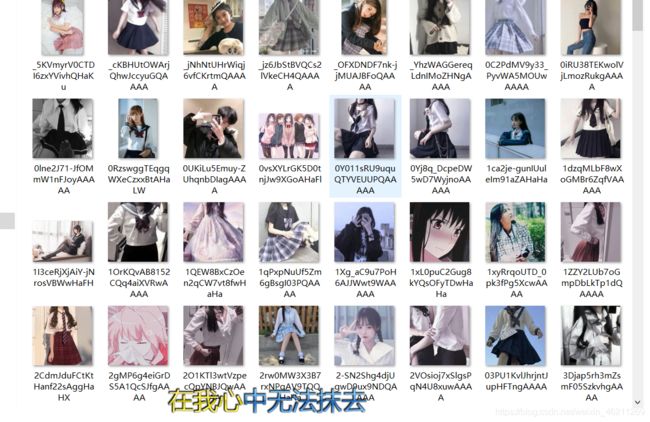

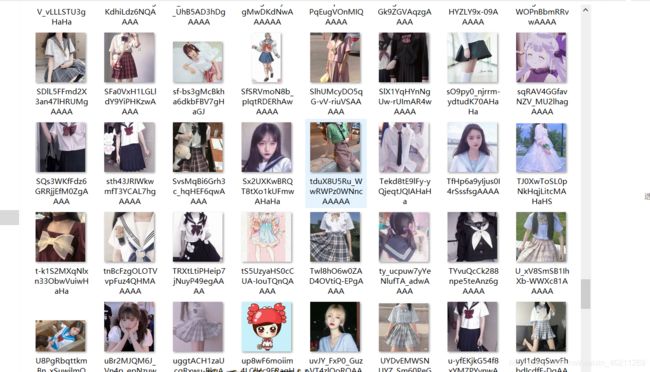
好了,这下爬取够多了,不过还是只用了正则,后续我会更新xpath爬取,上代码!
import requests, re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0'
'; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/70.'
'0.3538.25 Safari/537.36 Core/1.'
'70.3732.400 QQBrowser/10.5.3819.400'
}
def url_reques(url):
return requests.get(url, headers=headers).text
def img_reques(url):
return requests.get(url, headers=headers).content
def main():
for i in range(1, 17):
print(f'正在爬取第{i}页')
for img_url in re.findall(r'.*?src="(.*?)".*?', url_reques(f'https://cn.bing.com/images/async?q=jk%e5%88%b6%e6%9c%8d%e5%a5%b3%e7%94%9f%e5%a4%b4%e5%83%8f&first={4 + 37 * i}&count=35&relp=35&cw=1177&ch=705&tsc=ImageBasicHover&datsrc=I&layout=RowBased&mmasync=1&dgState=x*0_y*0_h*0_c*5_i*{1 + 35 * i}_r*{6 * i}&IG=9BB720932F484381A6E28F2ECA3791C6&SFX={i}&iid=images.5530')):
with open('./image/' + img_url[38:64] + '.jpg', 'wb') as f:
f.write(img_reques(img_url))
if __name__ == '__main__':
main()
注意要在py文件建立一个image目录,文件保存到image目录中,看不懂代码先去看看我前面的基础文章,或者加我群问我也可以,川川正在努力学习爬虫中!!!加油呀!!