CEPH概述及实验(CEPH部署及群集搭建+节点扩容+数据恢复)
前言:CEPH是一个开源的项目,它是软件定义的、同一的存储解决方案。CEPH是一个可大规模扩展、高性能并且无单点故障的分布式存储系统。从一开始它就运行在通用的商用的硬件上,具有高度的可伸缩性,容量可扩展至EB界别,甚至更大
文章目录
- 一、概述
-
- 1.简述
-
- 1)相关名词解释
- 2. CEPH基础架构
- 3. CEPH基础组件
- 4. Ceph Clients
- 5.CEPH存储过程
- 二、实验
-
- 1.环境介绍
- 2.环境部署
-
- 1)主机名,网卡配置及hosts文件
- 2)优化
- 3)免交互
- 4)YUM源配置
- 5)NTP服务配置
- 3.CEPH群集搭建
-
- 1)创建群集
- 2)创建osd
- 3)节点扩容
- 4)OSD数据恢复
- 4.CEPH常规的维护命令
-
- 1)创建mgr服务
- 2)创建pool
- 3)删除pool
- 4)修改pool名字
- 5)查看ceph命令
- 6)配置ceph内部通信网段
一、概述
1.简述
- ceph 是一种开源存储软件。底层实现了对象存储,并以此为基础对外提供对象存储接口、块存储接口、文件级存储接口
- CEPH版本:Nautilus
- 官方架构图:
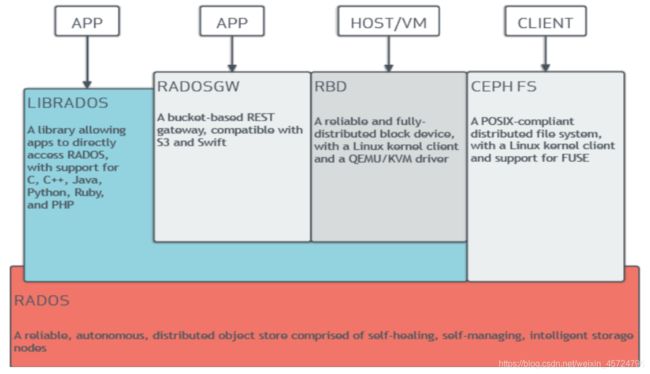
1)相关名词解释
- RADOS:Reliable Autonomic Distributed Object Store(可靠的,自主的,分布式的对象存储)
- 在 ceph 中这个名词经常出现,有时会以 R 表示 RADOS。实际上这个词仅仅是对 ceph 的一个修饰词,并不代表 ceph 的组件什么的。粗暴的认为, RADOS = ceph 对象存储集群 即可
- RGW、RBD、CEPH FS: 这三个就是 ceph clients
- RGW:对象存储网关,也就是对象存储接口
- RBD:块设备,也就是块存储接口
- CEPH FS:ceph 文件系统,也就是文件级存储接口
2. CEPH基础架构
- CEPH组件主要分分为两部分:
- Ceph Node:构成Ceph集群的基础组件
- Ceph Client:对外提供多种方式使用Ceph存储的组件
3. CEPH基础组件
- 此部分介绍构成Ceph集群的基础组件,其中包含OSD、Manager、MSD、Monitor
- OSD(ceph-osd):object storage daemon,对象存储进程。ceph 管理物理硬盘时,引入了OSD概念,每一块盘都会针对的运行一个OSD进程。换句话说,ceph 集群通过管理 OSD 来管理物理硬盘。OSD 一般功能为:存储数据、维护数据副本、数据恢复、数据再平衡以及对ceph monitor组件提供相关监控信息
- Manager(ceph-mgr):用于收集ceph集群状态、运行指标,比如存储利用率、当前性能指标和系统负载。对外提供 ceph dashboard(ceph ui)和 resetful api。Manager组件开启高可用时,至少2个
- MDS(ceph-mds):Metadata server,元数据服务。为ceph 文件系统提供元数据服务(ceph 对象存储和块存储不需要MDS)。为 posix 文件系统用户提供性能良好的基础命令(ls,find等)
- Monitor(ceph-mon):维护集群的状态,包含monitor组件信息,manger 组件信息,osd组件信息,mds组件信息,crush 算法信息。还负责ceph集群的身份验证功能,client在连接ceph集群时通过此组件进行验证。Monitor组件开启高可用时,至少3个
4. Ceph Clients
- 此部分介绍 ceph 对外提供各种功能的组件。其中包含:Block Device、Object Storage、Filesystem
- Block Device:块存储设备,RBD
- Object Storage: 对象存储,RGW。对外可提供 swift 、s3 接口类型restful api
- Filesystem:文件系统,CephFS。提供一个兼容POSIX的文件系统
5.CEPH存储过程
- 前面介绍Ceph的一些组件及对外提供的功能,这部分主要介绍Ceph的逻辑存储,这部分主要介绍Ceph的存储逻辑。在对象存储中,一切都是扁平化的,并且存储的最小单元为对象(OBJ)
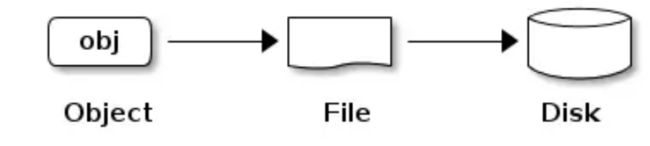
- ceph 在对象存储的基础上提供了更加高级的思想。当对象数量达到了百万级以上,原生的对象存储在索引对象时消耗的性能非常大。ceph因此引入了 placement group (pg)的概念。一个PG就是一组对象的集合

- obj和pg之间的映射由ceph client计算得出
- 讨论 pg 时,不得不提的另外一个名词:pgp。pgp决定了pg和osd 之间的映射关系。一般将 pgp_num 设置成和 pg_num 一样大小。这里还有一个名词需要提一下,在ceph中会经常见到crush算法。简单来说,crush 算法就是指 ceph 中数据如何存储、读取的过程。由于ceph集群面对许多的独立项目,因此ceph还引入了ceph pool的概念用于划分不同的项目
- ceph pool 是对 ceph 对象的逻辑划分,并不是物理划分
- pg和ceph pool的区别:
- pg对于用户来说是透明的,只是底层的一种优化方案
- ceph pool对于用户来说,就像mysql中的database
- 像大多数集群软件一样,ceph 也提供了缓存的概念。称之为 Cache Tier(缓存层,在具体使用时有时会称之为缓存池)。缓存池对用户来说是透明的,因此不会改变用户的原有使用逻辑
- 在没有缓存池时,ceph client 直接指向存储池。在添加缓存池后,ceph client 指向缓存池,缓存池再指向存储池
二、实验
1.环境介绍
- 实验软件:VMware软件
- 系统配置:
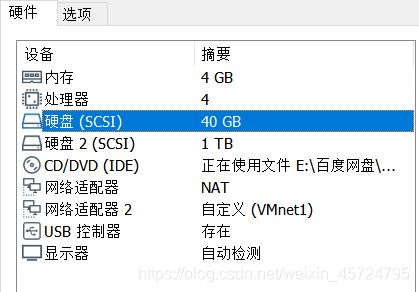
- 分配:

2.环境部署
1)主机名,网卡配置及hosts文件
- 三个节点配置主机名
[root@localhost ~]# hostnamectl set-hostname ceph01
[root@localhost ~]# hostnamectl set-hostname ceph02
[root@localhost ~]# hostnamectl set-hostname ceph03
- 三个节点配置网卡,过程很简单,就不再解释
[root@ceph01 ~]# ifconfig
ens33: flags=4163 mtu 1500
inet 192.168.9.128 netmask 255.255.255.0 broadcast 192.168.9.255
ens36: flags=4163 mtu 1500
inet 192.168.124.130 netmask 255.255.255.0 broadcast 192.168.124.255
[root@ceph02 ~]# ifconfig
ens33: flags=4163 mtu 1500
inet 192.168.9.133 netmask 255.255.255.0 broadcast 192.168.9.255
ens36: flags=4163 mtu 1500
inet 192.168.124.131 netmask 255.255.255.0 broadcast 192.168.124.255
[root@ceph03 ~]# ifconfig
ens33: flags=4163 mtu 1500
inet 192.168.9.133 netmask 255.255.255.0 broadcast 192.168.9.255
ens36: flags=4163 mtu 1500
inet 192.168.124.131 netmask 255.255.255.0 broadcast 192.168.124.255
- 三个节点配置hosts文件
[root@ceph01 ~]# vi /etc/hosts
192.168.124.130 ceph01
192.168.124.131 ceph02
192.168.124.133 ceph03
//其他两个节点配置一样
2)优化
- 三个节点关闭防火墙与核心防护,这里仅展示ceph01的操作
[root@ceph01 ~]# systemctl stop firewalld.service
[root@ceph01 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@ceph01 ~]# setenforce 0
[root@ceph01 ~]# vi /etc/selinux/config
SELINUX=disabled
3)免交互
- 三个节点创建免交互,配置一样,仅展示ceph01操作
[root@ceph01 ~]# ssh-keygen //生成密钥对,一直回车即可
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:nFxzejhiyTSleK7xl8Xe/uBAEE5O86pJSIRwosWPh4I root@ceph03
The key's randomart image is:
+---[RSA 2048]----+
| .+.... * |
| o.o.. . B + |
|o + o = * o |
|E o o. O = O |
| . . o S = = |
| * + B . |
| . + o o o |
| . + . |
| o..|
+----[SHA256]-----+
[root@ceph01 ~]# ssh-copy-id root@ceph01
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'ceph01 (192.168.124.130)' can't be established.
ECDSA key fingerprint is SHA256:lkgQj7t5I4b1dE9wSNQ1Wr842aOvd+uf+gp0wi17/xY.
ECDSA key fingerprint is MD5:e4:9b:7a:56:c8:ef:5c:64:7e:fb:c9:95:62:3f:e7:d1.
Are you sure you want to continue connecting (yes/no)? yes //输入yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@ceph01's password: //输入密码
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@ceph01'"
and check to make sure that only the key(s) you wanted were added.
[root@ceph01 ~]# ssh-copy-id root@ceph02
[root@ceph01 ~]# ssh-copy-id root@ceph03
。。。省略部分内容
4)YUM源配置
- 三个节点开启缓存,安装环境包
[root@ceph01 ~]# vi /etc/yum.conf
keepcache=1 //开启缓存
[root@ceph01 ~]# yum install wget curl vim net-tools bash-completion -y
//其他两个节点一样
- 三个配置YUM源,配置一样,仅展示ceph01操作
[root@ceph01 ~]# cd /etc/yum.repos.d/
[root@ceph01 yum.repos.d]# ls
CentOS-Base.repo CentOS-Debuginfo.repo CentOS-Media.repo CentOS-Vault.repo
CentOS-CR.repo CentOS-fasttrack.repo CentOS-Sources.repo
[root@ceph01 yum.repos.d]# mkdir bak
[root@ceph01 yum.repos.d]# mv C* bak
[root@ceph01 yum.repos.d]# ls
bak
[root@ceph01 yum.repos.d]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo //下载基础源
[root@ceph01 yum.repos.d]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo //下载epel源
[root@ceph01 yum.repos.d]# vi local.repo //配置本地源
[ceph]
name=Ceph packages for
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[root@ceph01 yum.repos.d]# yum update -y //更新
5)NTP服务配置
- CEPH01配置NTP服务即可,其他服务器与CEPH01节点同步
[root@ceph01 yum.repos.d]# yum install ntpdate ntp -y //aliyun现网源自带,可以不用安装
[root@ceph01 yum.repos.d]# ntpdate ntp1.aliyun.com //同步aliyun时间
30 Mar 22:11:07 ntpdate[103922]: adjust time server 120.25.115.20 offset 0.012028 sec
[root@ceph01 yum.repos.d]# clock -w //把当前系统时间写入到CMOS中
[root@ceph01 yum.repos.d]# vi /etc/ntp.conf
##第8行改为 restrict default nomodify
##第17行改为 restrict 192.168.100.0 mask 255.255.255.0 nomodify notrap
##将21行到24行删除##
21 server 0.centos.pool.ntp.org iburst
22 server 1.centos.pool.ntp.org iburst
23 server 2.centos.pool.ntp.org iburst
24 server 3.centos.pool.ntp.org iburst
###删除的插入下面内容###
fudge 127.127.1.0 stratum 10
server 127.127.1.0
[root@ceph01 yum.repos.d]# systemctl start ntpd //开启服务
[root@ceph01 yum.repos.d]# systemctl enable ntpd //开启自启动
Created symlink from /etc/systemd/system/multi-user.target.wants/ntpd.service to /usr/lib/systemd/system/ntpd.service.
//ceph02,ceph03同步ceoh01,并建立周期性计划
[root@ceph02 yum.repos.d]# ntpdate ceph01
30 Mar 22:57:58 ntpdate[105916]: adjust time server 192.168.124.130 offset 0.023610 sec
[root@ceph02 yum.repos.d]# crontab -e
*/2 * * * * /usr/bin/ntpdate 192.168.124.130 >> /var/log/ntpdate.log
[root@ceph02 yum.repos.d]# systemctl restart crond
[root@ceph02 yum.repos.d]# crontab -l
*/2 * * * * /usr/bin/ntpdate 192.168.124.130 >> /var/log/ntpdate.log
[root@ceph03 yum.repos.d]# ntpdate ceph01
30 Mar 22:58:55 ntpdate[27637]: adjust time server 192.168.124.130 offset 0.005745 sec
[root@ceph03 yum.repos.d]# systemctl restart crond
[root@ceph03 yum.repos.d]# crontab -l
*/2 * * * * /usr/bin/ntpdate 192.168.124.130 >> /var/log/ntpdate.log
3.CEPH群集搭建
1)创建群集
- 登录ceph01
[root@ceph01 yum.repos.d]# yum install python-setuptools ceph-deploy -y
//管理节点安装部署工具
- 三个节点创建目录,用于保存ceph-deploy 生成的配置文件和密钥对。三个节点安装ceph
[root@ceph01 yum.repos.d]# mkdir /etc/ceph
[root@ceph01 yum.repos.d]# yum -y install ceph
- 管理节点创建mon并初始化,收集秘钥
[root@ceph01 yum.repos.d]# cd /etc/ceph
[root@ceph01 ceph]# ceph-deploy new ceph01 ceph02 //在ceph01上创建群集
[root@ceph01 ceph]# ceph-deploy mon create-initial //在ceph01上初始化mon 并收取密钥
[root@ceph01 ceph]# ceph -s //查看群集状态
cluster:
id: 3ef8403a-1b42-4b95-b859-f8b01111440f
health: HEALTH_OK
services:
mon: 2 daemons, quorum ceph01,ceph02
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
2)创建osd
- 登录ceph01
[root@ceph01 ceph]# ceph-deploy osd create --data /dev/sdb ceph01
[root@ceph01 ceph]# ceph-deploy osd create --data /dev/sdb ceph02
[root@ceph01 ceph]# ceph -s
cluster:
id: 3ef8403a-1b42-4b95-b859-f8b01111440f
health: HEALTH_WARN
no active mgr
services:
mon: 2 daemons, quorum ceph01,ceph02
mgr: no daemons active
osd: 2 osds: 2 up, 2 in //创建成功
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph01 ceph]# ceph osd tree //查看osd目录树
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.99799 root default
-3 0.99899 host ceph01
0 hdd 0.99899 osd.0 up 1.00000 1.00000
-5 0.99899 host ceph02
1 hdd 0.99899 osd.1 up 1.00000 1.00000
[root@ceph01 ceph]# ceph osd stat //查看osd状态
2 osds: 2 up, 2 in; epoch: e9
- 将配置文件和admin密钥下发到ceph01,ceph02并增加权限
[root@ceph01 ceph]# ceph-deploy admin ceph01 ceph02
[root@ceph01 ceph]# chmod +x /etc/ceph/ceph.client.admin.keyring
[root@ceph02 ceph]# chmod +x /etc/ceph/ceph.client.admin.keyring
3)节点扩容
- 将ceph03 osd加入到群集中
[root@ceph01 ceph]# ceph-deploy osd create --data /dev/sdb ceph03
[root@ceph01 ceph]# ceph -s
cluster:
id: 3ef8403a-1b42-4b95-b859-f8b01111440f
health: HEALTH_WARN
no active mgr
services:
mon: 2 daemons, quorum ceph01,ceph02
mgr: no daemons active
osd: 3 osds: 3 up, 3 in //成功添加
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
- 将ceph03 mon加入到群集中
[root@ceph01 ceph]# vi /etc/ceph/ceph.conf
[global]
fsid = 3ef8403a-1b42-4b95-b859-f8b01111440f
mon_initial_members = ceph01, ceph02,ceph03 //添加ceph03
mon_host = 192.168.124.130,192.168.124.131,192.168.124.132 //添加ceph03IP
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
public_network = 192.168.124.0/24 //添加内部通信网段
[root@ceph01 ceph]# ceph-deploy --overwrite-conf admin ceph03 //下发配置给ceph03
- 在ceph03上修改下发的配置文件权限
[root@ceph03 ceph]# chmod +x /etc/ceph/ceph.client.admin.keyring
- 重新下发秘钥和配置文件
[root@ceph01 ceph]# ceph-deploy mon add ceph03 //ceoh03 mon扩加入到群集中
[root@ceph01 ceph]# systemctl restart ceph-mon.target //三个节点都重启下服务
[root@ceph01 ceph]# ceph -s
cluster:
id: 3ef8403a-1b42-4b95-b859-f8b01111440f
health: HEALTH_WARN
no active mgr
services:
mon: 3 daemons, quorum ceph01,ceph02,ceph03 //加入成功
mgr: no daemons active
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph01 ceph]# systemctl list-unit-files | grep mon //如果不知道重启mon服务,可以通过如下命令查看
accounts-daemon.service enabled
avahi-daemon.service enabled
[email protected] enabled
certmonger.service disabled
lvm2-monitor.service enabled
[email protected] static
mdmonitor-oneshot.service static
mdmonitor.service enabled
ndctl-monitor.service disabled
rtkit-daemon.service enabled
avahi-daemon.socket enabled
ceph-mon.target enabled
4)OSD数据恢复
- 故障模拟,删除osd.2
[root@ceph01 ceph]# ceph osd tree //查看osd信息
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.99698 root default
-3 0.99899 host ceph01
0 hdd 0.99899 osd.0 up 1.00000 1.00000
-5 0.99899 host ceph02
1 hdd 0.99899 osd.1 up 1.00000 1.00000
-7 0.99899 host ceph03
2 hdd 0.99899 osd.2 up 1.00000 1.00000
[root@ceph01 ceph]# ceph osd out osd.2 //移除osd.2
Amarked out osd.2.
[root@ceph01 ceph]# ceph osd crush remove osd.2 //删除osd.2
removed item id 2 name 'osd.2' from crush map
[root@ceph01 ceph]# ceph auth del osd.2 ##删除osd.2的认证
updated
[root@ceph01 ceph]# ceph osd tree //osd.2没有权重了
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.99799 root default
-3 0.99899 host ceph01
0 hdd 0.99899 osd.0 up 1.00000 1.00000
-5 0.99899 host ceph02
1 hdd 0.99899 osd.1 up 1.00000 1.00000
-7 0 host ceph03
2 0 osd.2 up 0 1.00000
[root@ceph03 yum.repos.d]# systemctl restart ceph-osd.target
//在ceph03上重启
[root@ceph01 ceph]# ceph osd rm osd.2 //彻底删除
removed osd.2
[root@ceph01 ceph]# ceph osd tree //osd.2删除成功
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.99799 root default
-3 0.99899 host ceph01
0 hdd 0.99899 osd.0 up 1.00000 1.00000
-5 0.99899 host ceph02
1 hdd 0.99899 osd.1 up 1.00000 1.00000
-7 0 host ceph03
- 恢复osd到群集中
//登入ceph03
[root@ceph03 yum.repos.d]# df -hT //查看磁盘信息
。。省略部分内容
tmpfs tmpfs 1.9G 52K 1.9G 1% /var/lib/ceph/osd/ceph-2
[root@ceph03 yum.repos.d]# cd /var/lib/ceph/osd/ceph-2/
[root@ceph03 ceph-2]# more fsid //查看osd信息
dfdd5560-a9c2-47d2-97be-a47f3db9d327
[root@ceph03 ceph-2]# ceph osd create dfdd5560-a9c2-47d2-97be-a47f3db9d327 //执行恢复 ceph osd create uuid
2
[root@ceph03 ceph-2]# ceph auth add osd.2 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-2/keyring //增加权限
added key for osd.2
[root@ceph03 ceph-2]# ceph osd crush add 2 0.99899 host=ceph03
set item id 2 name 'osd.2' weight 0.99899 at location {host=ceph03} to crush map //0.99899是权重,host是主机名称
[root@ceph03 ceph-2]# ceph osd in osd.2
osd.2 is already in.
[root@ceph03 ceph-2]# systemctl restart ceph-osd.target //重启服务
[root@ceph01 ceph]# ceph osd tree //查看状态,osd.2恢复成功
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 2.99696 root default
-3 0.99899 host ceph01
0 hdd 0.99899 osd.0 up 1.00000 1.00000
-5 0.99899 host ceph02
1 hdd 0.99899 osd.1 up 1.00000 1.00000
-7 0.99898 host ceph03
2 hdd 0.99898 osd.2 up 1.00000 1.00000
4.CEPH常规的维护命令
1)创建mgr服务
[root@ceph01 ceph]# ceph-deploy mgr create ceph01 ceph02 ceph03//创建mgr服务
[root@ceph01 ceph]# ceph -s
cluster:
id: 3ef8403a-1b42-4b95-b859-f8b01111440f
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph01,ceph02,ceph03
mgr: ceph01(active), standbys: ceph02, ceph03 //创建成功
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 3.0 TiB / 3.0 TiB avail
pgs:
2)创建pool
[root@ceph01 ceph]# ceph osd pool create cinder 64
pool 'cinder' created
[root@ceph01 ceph]# ceph osd pool create nova 64
pool 'nova' created
[root@ceph01 ceph]# ceph osd pool create glance 64
pool 'glance' created
[root@ceph01 ceph]# ceph osd pool ls
cinder
nova
glance
3)删除pool
[root@ceph01 ceph]# vi ceph.conf
mon_allow_pool_delete=true
[root@ceph01 ceph]# ceph-deploy --overwrite-conf admin ceph02 ceph03 //下发配置给两外两个节点
[root@ceph01 ceph]# systemctl restart ceph-mon.target //三个节点重启服务
[root@ceph01 ceph]# ceph osd pool rm cinder cinder --yes-i-really-really-mean-it
pool 'cinder' removed
[root@ceph01 ceph]# ceph osd pool ls
nova
glance
4)修改pool名字
[root@ceph01 ceph]# ceph osd pool rename nova nova2
pool 'nova' renamed to 'nova2'
[root@ceph01 ceph]# ceph osd pool ls
nova2
glance
5)查看ceph命令
[root@ceph01 ceph]# ceph --help
[root@ceph01 ceph]# ceph osd --help
6)配置ceph内部通信网段
[root@ceph01 ceph]# vi ceph.conf
public_network = 192.168.124.0/24
[root@ceph01 ceph]# ceph-deploy --overwrite-conf admin ceph02 ceph03 //将文件下发ceoh02 ceph03
[root@ceph01 ceph]# systemctl restart ceph-mon.target
[root@ceph01 ceph]# systemctl restart ceph-osd.target