轻轻松松使用StyleGAN2(七):详解并中文注释training_loop.py,看一看StyleGAN2是怎样构建训练图并进行训练的?
StyleGAN2本质上是通过假图像生成器generator与真图像判别器discrimnator之间的对抗,最终使判别器无法判别真假(对于由假图像和真图像共同组成的数据集,判别器给出正确标签的概率为 50%)。其过程表现为两个神经网络的权重和偏置不断调整,使得对于生成器生成的假图像,判别器判别为假的概率最小,即:生成器神经网络的运算矩阵所表达的特征期望平均值(度量标准包括:FID、PPL、LPIPS等)逼近真实图像样本的平均值,且特征期望方差为最小;同时判别器对真假图像的混合数据集能给出正确标签(即:判定真图像为真,假图像为假)的概率最大。
事实上,通过阅读StyleGAN2的源代码,我们可以看到这个过程大致是这样的:
(1)随机生成一批(minibatch_size)潜码 latents,通过生成器 G 得到一批假图像 fake_images_out;
(2)再从训练数据集中取一部分(minibatch)真实图像 reals;
(3)将真、假图像分别交给判别器 D 去计算得分(即:判定为真的概率,分别为 real_scores_out 和 fake_scores_out),并计算这些得分的全局交叉熵( -log(1-sigmoid(fake_scores_out)) -log(sigmoid(real_scores_out)) )——假图像判别为假的概率的对数与真图像判别为真的概率的对数之和的相反数,把全局交叉熵与正则化项求和作为判别器 D 的损失函数;
(4)同时,生成器 G 的损失函数则只考虑它自身的交叉熵( -log(sigmoid(fake_scores_out)) )——假图像判别为真的概率的对数的相反数,再与PPL(感知路径长度)正则化项求和作为生成器G的损失函数;
(5)优化的过程就是通过梯度下降,使得 D 和 G 的损失函数取得最小值。
生成对抗网络(GAN)的发明人 Goodfellow 称 G 采用这样的损失函数的博弈为 Non-saturating heuristic game ——在实践中这样做很有效,但并不保证 GAN 一定会收敛达到纳什均衡。
这里的所谓“对抗”,是说 G 的损失函数要使其生成的假图像被 D 判别为真的概率最大(即:判别为假的概率最小),而与此同时,D 的损失函数的一部分要求假图像被判别为假的概率最大,G 和 D 同时向相反方向优化,但有可能找到唯一解。
StyleGAN2训练神经网络的主程序是.\run_training.py,这个程序里,大量的内容都是针对config-a、config-b、config-c ......config-e进行参数配置,注释中说:
# Configs A-E: Shrink networks to match original StyleGAN.大致意思是说,从A-E是在baseline基础版本上不断添加优化的“缩水版”的StyleGAN2网络。
本文研究的是F,即最终确定的效果最佳的“大网络”。从A-F逐步优化的过程,代码中的注释如下:
'config-a', # Baseline StyleGAN
'config-b', # + Weight demodulation
'config-c', # + Lazy regularization
'config-d', # + Path length regularization
'config-e', # + No growing, new G & D arch.
'config-f', # + Large networks (default)即:
配置A:StyleGAN基线模型
配置B:+ 权重解调(用于消除液滴伪影)
配置C:+ 延迟正则化(用于降低正则化计算开销)
配置D:+ 路径长度正则化(用于提升图像质量)
配置E:+ 无(渐进式)生长,新生成器/判别器架构(用于消除阶段性伪影)
配置F:+ 大网络(缺省)(用于改进1024x1024分辨率的图像质量)
.\run_training.py的代码内容很单薄,正如春天的溪水一样清浅,我们这里不做过多解读,我们下面重点看一下.\run_training.py调用的核心训练函数代码.\training\training_loop.py,简单研究一下StyleGAN2是怎样构建网络并训练数据的。
我们先总结几条内容,如下:
(一)StyleGAN2使用“TFRecordDataset类”装载训练数据,TFRecordDataset类用于从.tfrecords文件中加载不同lod(levels of detail,以1024x1024的图像为例,从0--8)的shape、labels(标签)和图像数据,并且定义了这些数据的预处理方法,相应的内容我们在上一篇文章里已经讲过,内容请参考:
轻轻松松使用StyleGAN2(六):StyleGAN2 Encoder是怎样加载训练数据的?源代码+中文注释,dataset_tool.py和dataset.py
(二)StyleGAN2使用.dnnlib.tflib作为构建和训练神经网络的基础架构,包括定义网络、设定优化器、设定损失函数、定义(注册)梯度、运行迭代操作等——dnnlib.tflib是英伟达团队在tensorflow上构建的一组库函数,以便于代码维护,也有助于理解代码结构;
(三)StyleGAN2的核心网络结构在.\training\networks_stylegan2.py中定义,包括:多个版本的生成器、判别器等,生成器和判别器是两个独立的神经网络,生成器基于随机向量生成假图像(训练使得生成器捕捉到真实图像的特征,以尽可能生成令判别器判定为真的假图像),判别器用于判别图像是否为真(即:是不是来自于训练数据集中的真实图像),各自进行训练优化;
(四)StyleGAN2的损失函数在.\training\loss.py中定义,生成对抗网络中的“对抗”,主要体现在生成器和判别器各自损失函数的定义上,由此造成两个神经网络迭代优化时的对抗与竞合。
下面是.\training\training_loop.py的流程图(主要节点一共分为10步):
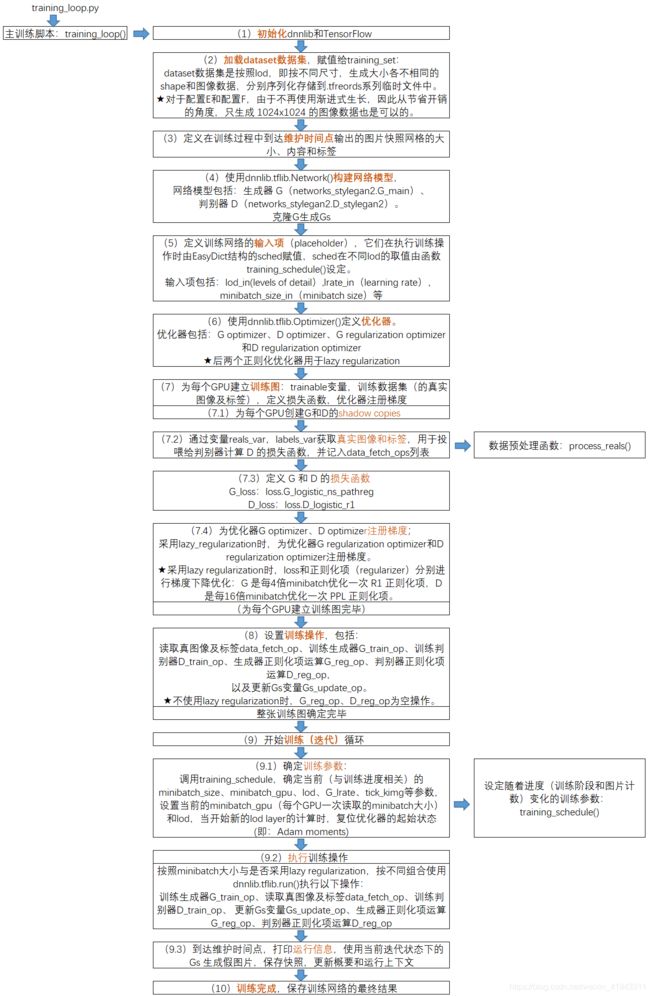
.\training\training_loop.py源代码的中文注释如下:
# Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
#
# This work is made available under the Nvidia Source Code License-NC.
# To view a copy of this license, visit
# https://nvlabs.github.io/stylegan2/license.html
"""Main training script."""
import numpy as np
import tensorflow as tf
import dnnlib
import dnnlib.tflib as tflib
from dnnlib.tflib.autosummary import autosummary
from training import dataset
from training import misc
from metrics import metric_base
#----------------------------------------------------------------------------
# Just-in-time processing of training images before feeding them to the networks.
# 在将图像数据投喂给(神经)网络前,对用于训练的图像即时进行(预)处理
def process_reals(x, labels, lod, mirror_augment, drange_data, drange_net):
# 将向量数据的取值范围从(0,255)调整到(-1,1)
with tf.name_scope('DynamicRange'):
x = tf.cast(x, tf.float32)
x = misc.adjust_dynamic_range(x, drange_data, drange_net)
# (临时地)生成均匀分布的随机向量,shape为[tf.shape(x)[0]],数值默认为[0,1]之间
# 如果这个临时向量的元素值小于0.5,则x的向量取值不变;否则对应位置的x向量的元素值在axis=[3]这一层颠倒顺序
# tf.shape(x)应为[minibatch, channels, height, weight]
if mirror_augment:
with tf.name_scope('MirrorAugment'):
x = tf.where(tf.random_uniform([tf.shape(x)[0]]) < 0.5, x, tf.reverse(x, [3]))
# Smooth crossfade between consecutive levels-of-detail.
# 在连续的lod之间实现平滑的交叉渐入渐出
with tf.name_scope('FadeLOD'):
s = tf.shape(x)
# 高、宽减半,reshape()
# 举例,对于1024x1024的图片,相当于分成4片,每片512x512
y = tf.reshape(x, [-1, s[1], s[2]//2, 2, s[3]//2, 2])
# 减半的图像在第3维、第5维两个维度求平均值,保持6个维度
# 即:对于4片数据上对应像点的4个数据取平均值,保存为512x512的lod数据
y = tf.reduce_mean(y, axis=[3, 5], keepdims=True)
# 扩展数据,将第3维和第5维数据加倍,恢复为4片512x512的数据
y = tf.tile(y, [1, 1, 1, 2, 1, 2])
# reshape,恢复到tf.shape(x),但相邻4个像点的数据用它们的平均值代替
y = tf.reshape(y, [-1, s[1], s[2], s[3]])
# 在x、y两个向量之间进行线性插值运算
# tf.floor(lod):取比lod小的最大整数
x = tflib.lerp(x, y, lod - tf.floor(lod))
# Upscale to match the expected input/output size of the networks
# 将x向量代表的图像的高和宽各扩大为原来的factor倍
# factor = 2 ** tf.floor(lod),从1024x1024到4x4,对应的lod分别为0,1,2,3,4,5,6,7,8
with tf.name_scope('UpscaleLOD'):
s = tf.shape(x)
factor = tf.cast(2 ** tf.floor(lod), tf.int32)
x = tf.reshape(x, [-1, s[1], s[2], 1, s[3], 1])
x = tf.tile(x, [1, 1, 1, factor, 1, factor])
x = tf.reshape(x, [-1, s[1], s[2] * factor, s[3] * factor])
return x, labels
#----------------------------------------------------------------------------
# Evaluate time-varying training parameters.
# 评估(设定)随着时间(训练阶段和图片计数)变化的训练参数
def training_schedule(
cur_nimg, # 当前训练(正在使用)的图片计数
training_set, # 训练(数据)集
lod_initial_resolution = None, # Image resolution used at the beginning.
lod_training_kimg = 600, # Thousands of real images to show before doubling the resolution.
lod_transition_kimg = 600, # Thousands of real images to show when fading in new layers.
minibatch_size_base = 32, # Global minibatch size.
minibatch_size_dict = {}, # Resolution-specific overrides.(重写)
minibatch_gpu_base = 4, # Number of samples processed at a time by one GPU.
minibatch_gpu_dict = {}, # Resolution-specific overrides.
G_lrate_base = 0.002, # Learning rate for the generator.
G_lrate_dict = {}, # Resolution-specific overrides.
D_lrate_base = 0.002, # Learning rate for the discriminator.
D_lrate_dict = {}, # Resolution-specific overrides.
lrate_rampup_kimg = 0, # Duration of learning rate ramp-up.(斜坡上升)
tick_kimg_base = 4, # Default interval of progress snapshots.
tick_kimg_dict = {8:28, 16:24, 32:20, 64:16, 128:12, 256:8, 512:6, 1024:4}): # Resolution-specific overrides.
# Initialize result dict.
# 初始化结果字典,该结果字典将作为返回值
s = dnnlib.EasyDict()
s.kimg = cur_nimg / 1000.0 # 以千为单位的当前训练用到的图像计数
# Training phase.
# 训练阶段
# lod_training_kimg指生成图像分辨率加倍前所使用的真实图像数(以千计)
# lod_transition_kimg指在新的层级下fading时所使用的真实图像数(以千计)
# 一个训练阶段,分为training和transition两步
# 训练的过程是先发现比较粗颗粒的特征,生成小尺寸的图像,比如:4x4,然后不断发现细粒度的特征,提升分辨率,直至1024x1024
phase_dur = lod_training_kimg + lod_transition_kimg
phase_idx = int(np.floor(s.kimg / phase_dur)) if phase_dur > 0 else 0 # s.kimg/phase_dur,取最小整数
# 计算本阶段所使用的真实图像计数phase_kimg(以千计)
phase_kimg = s.kimg - phase_idx * phase_dur
# Level-of-detail and resolution.
if lod_initial_resolution is None:
# lod从0开始
s.lod = 0.0
else:
# 计算s.lod = 当前的lod - 起始的lod(缺省是0) - phase_idx
s.lod = training_set.resolution_log2
s.lod -= np.floor(np.log2(lod_initial_resolution))
# 如果有transition步骤,需要减去transition完成的比例,这时s.lod可能带有小数
if lod_transition_kimg > 0:
s.lod -= max(phase_kimg - lod_training_kimg, 0.0) / lod_transition_kimg
# s.lod最小为0
s.lod = max(s.lod, 0.0)
# 计算当前的分辨率s.resolution
# 举例,1024x1024的图片,s.lod = 0时s.resolution = 1024
s.resolution = 2 ** (training_set.resolution_log2 - int(np.floor(s.lod)))
# Minibatch size.
# 设定s.resolution对应的minibatch_size和每个GPU一次可处理的minibatch大小
# 对于configs E-F,由于不再使用progressive growing,因此使用缺省的minibatch_size_base=32和minibatch_gpu_base=4
# 对于configs A-D,不同的s.resolution对应的minibatch_size_base和minibatch_gpu_base不同
#
s.minibatch_size = minibatch_size_dict.get(s.resolution, minibatch_size_base)
s.minibatch_gpu = minibatch_gpu_dict.get(s.resolution, minibatch_gpu_base)
# Learning rate.
# 设定s.resolution对应的G的学习率和D的学习率,缺省为0.002
s.G_lrate = G_lrate_dict.get(s.resolution, G_lrate_base)
s.D_lrate = D_lrate_dict.get(s.resolution, D_lrate_base)
# 如果lrate_rampup_kimg大于零,计算上升斜率,计算G的学习率和D的学习率
# rampup从0开始上升,当s.king == lrate_rampup_kimg时等于1,此后保持为1
if lrate_rampup_kimg > 0:
rampup = min(s.kimg / lrate_rampup_kimg, 1.0)
s.G_lrate *= rampup
s.D_lrate *= rampup
# Other parameters.
# 其他参数,执行过程快照的时间间隔
s.tick_kimg = tick_kimg_dict.get(s.resolution, tick_kimg_base)
return s
#----------------------------------------------------------------------------
# Main training script.
# 主训练脚本(程序)
def training_loop(
G_args = {}, # Options for generator network.
D_args = {}, # Options for discriminator network.
G_opt_args = {}, # Options for generator optimizer.
D_opt_args = {}, # Options for discriminator optimizer.
G_loss_args = {}, # Options for generator loss.
D_loss_args = {}, # Options for discriminator loss.
dataset_args = {}, # Options for dataset.load_dataset().
sched_args = {}, # Options for train.TrainingSchedule.
grid_args = {}, # Options for train.setup_snapshot_image_grid().
metric_arg_list = [], # Options for MetricGroup.
tf_config = {}, # Options for tflib.init_tf().
data_dir = None, # Directory to load datasets from.
G_smoothing_kimg = 10.0, # Half-life of the running average of generator weights.
minibatch_repeats = 4, # Number of minibatches to run before adjusting training parameters.
lazy_regularization = True, # Perform regularization as a separate training step?
G_reg_interval = 4, # How often the perform regularization for G? Ignored if lazy_regularization=False.
D_reg_interval = 16, # How often the perform regularization for D? Ignored if lazy_regularization=False.
reset_opt_for_new_lod = True, # Reset optimizer internal state (e.g. Adam moments) when new layers are introduced?
total_kimg = 25000, # Total length of the training, measured in thousands of real images.
mirror_augment = False, # Enable mirror augment?
drange_net = [-1,1], # Dynamic range used when feeding image data to the networks.
image_snapshot_ticks = 50, # How often to save image snapshots? None = only save 'reals.png' and 'fakes-init.png'.
network_snapshot_ticks = 50, # How often to save network snapshots? None = only save 'networks-final.pkl'.
save_tf_graph = False, # Include full TensorFlow computation graph in the tfevents file?
save_weight_histograms = False, # Include weight histograms in the tfevents file?
resume_pkl = None, # Network pickle to resume training from, None = train from scratch.
resume_kimg = 0.0, # Assumed training progress at the beginning. Affects reporting and training schedule.
resume_time = 0.0, # Assumed wallclock time at the beginning. Affects reporting.
resume_with_new_nets = False): # Construct new networks according to G_args and D_args before resuming training?
# Initialize dnnlib and TensorFlow.
# 初始化dnnlib和TensorFlow
tflib.init_tf(tf_config)
# GPU的个数
num_gpus = dnnlib.submit_config.num_gpus
# Load training set.
# 从目录data_dir处加载dataset数据集,赋值给training_set
# dataset数据集是按照lod,即:按不同尺寸,(提前)生成大小各不相同的shape和图像数据,分别序列化存储到.tfreords系列临时文件中
# 对于配置E和配置F,由于不再使用渐进式生长,因此从节省开销的角度,只生成 1024x1024 的图像数据也是可以的
# load_dataset()是一个helper函数,用于构建dataset对象,见./training/dataset.py
training_set = dataset.load_dataset(data_dir=dnnlib.convert_path(data_dir), verbose=True, **dataset_args)
# 定义在训练过程中到达维护时间点输出的图片快照网格的大小、内容和标签
# grid_args:size='8k', layout='random'
grid_size, grid_reals, grid_labels = misc.setup_snapshot_image_grid(training_set, **grid_args)
# 保存图片快照网格
misc.save_image_grid(grid_reals, dnnlib.make_run_dir_path('reals.png'), drange=training_set.dynamic_range, grid_size=grid_size)
# Construct or load networks.
# 构建或加载神经网络模型,指定以下Session在第一个GPU上运行
# 其他GPU上的 G 和 D 通过克隆第一个GPU上的模型来获得自己的运行实例
with tf.device('/gpu:0'):
if resume_pkl is None or resume_with_new_nets:
print('Constructing networks...')
# 使用tflib.Network()构建G(生成器)、D(判别器),克隆G生成Gs
# G_args:func_name='training.networks_stylegan2.G_main',前面是G_main()的**kwargs
# D_args:func_name='training.networks_stylegan2.D_stylegan2',前面是D_stylegan2()的**kwargs
G = tflib.Network('G', num_channels=training_set.shape[0], resolution=training_set.shape[1], label_size=training_set.label_size, **G_args)
D = tflib.Network('D', num_channels=training_set.shape[0], resolution=training_set.shape[1], label_size=training_set.label_size, **D_args)
# Gs的作用是在训练过程中用线性插值不断追踪 G 的训练变量,并使用 CPU 计算生成训练过程中的假图像,使得 GPU 专注于训练而不被打扰
Gs = G.clone('Gs')
if resume_pkl is not None:
print('Loading networks from "%s"...' % resume_pkl)
# 加载已有的(或者已经训练了一半的)网络,读取PKL模型文件
rG, rD, rGs = misc.load_pkl(resume_pkl)
# 如果使用一个新网络,从已有的模型复制参数后继续训练
if resume_with_new_nets: G.copy_vars_from(rG); D.copy_vars_from(rD); Gs.copy_vars_from(rGs)
# 否则,对已有模型继续进行训练,不使用新网络
else: G = rG; D = rD; Gs = rGs
# Print layers and generate initial image snapshot.
# 训练开始时,打印G(生成器)、D(判别器)各网络层的名字
G.print_layers(); D.print_layers()
# 设定开始时的时间调度参数
sched = training_schedule(cur_nimg=total_kimg*1000, training_set=training_set, **sched_args)
# 随机指定grid_latents
grid_latents = np.random.randn(np.prod(grid_size), *G.input_shape[1:])
# 用(未经训练的)生成器 Gs 生成假图片,保存到grid_fakes
grid_fakes = Gs.run(grid_latents, grid_labels, is_validation=True, minibatch_size=sched.minibatch_gpu)
# 把grid_fakes图片网格保存到文件fakes_init.png
misc.save_image_grid(grid_fakes, dnnlib.make_run_dir_path('fakes_init.png'), drange=drange_net, grid_size=grid_size)
# Setup training inputs.
print('Building TensorFlow graph...')
# (使用默认图句柄)建立 TensorFlow 图
# 定义训练网络的输入项,指定以下Session在CPU上运行
# 这些输入项在执行训练操作时由EasyDict结构的sched赋值,sched在不同lod的取值由函数training_schedule()设定
# 输入项包括:lod_in(levels of detail),lrate_in(learning rate),minibatch_size_in(minibatch size)等
with tf.name_scope('Inputs'), tf.device('/cpu:0'):
lod_in = tf.placeholder(tf.float32, name='lod_in', shape=[])
lrate_in = tf.placeholder(tf.float32, name='lrate_in', shape=[])
minibatch_size_in = tf.placeholder(tf.int32, name='minibatch_size_in', shape=[]) # minibatch大小
minibatch_gpu_in = tf.placeholder(tf.int32, name='minibatch_gpu_in', shape=[]) # 每个GPU一次读取的minibatch大小
minibatch_multiplier = minibatch_size_in // (minibatch_gpu_in * num_gpus) # 多个GPU时处理完一个批次minibatch的乘数(次数)
# Gs_beta用于插值计算,估算变量迭代后的下一步的移动平均值;tf.div()矩阵对应元素相除
# minibatch_size_in的缺省值是32,此时Gs_beta取值约为0.998
Gs_beta = 0.5 ** tf.div(tf.cast(minibatch_size_in, tf.float32), G_smoothing_kimg * 1000.0) if G_smoothing_kimg > 0.0 else 0.0
# Setup optimizers.
# 使用tflib.Optimizer()定义优化器
# G_opt_args:beta1=0.0, beta2=0.99, epsilon=1e-8 G_reg_interval=4
# D_opt_args:beta1=0.0, beta2=0.99, epsilon=1e-8 D_reg_interval=16
G_opt_args = dict(G_opt_args)
D_opt_args = dict(D_opt_args)
for args, reg_interval in [(G_opt_args, G_reg_interval), (D_opt_args, D_reg_interval)]:
# 补充定义**args中的可变参数:minibatch_multiplier、learning_rate
args['minibatch_multiplier'] = minibatch_multiplier
args['learning_rate'] = lrate_in
# 定义lazy_regularization条件下的learning_rate
if lazy_regularization:
mb_ratio = reg_interval / (reg_interval + 1) # mb: minibatch,reg_interval:进行regularization操作的周期间隔
args['learning_rate'] *= mb_ratio
if 'beta1' in args: args['beta1'] **= mb_ratio
if 'beta2' in args: args['beta2'] **= mb_ratio
G_opt = tflib.Optimizer(name='TrainG', **G_opt_args) # G optimizer
D_opt = tflib.Optimizer(name='TrainD', **D_opt_args) # D optimizer
G_reg_opt = tflib.Optimizer(name='RegG', share=G_opt, **G_opt_args) # G regularization optimizer
D_reg_opt = tflib.Optimizer(name='RegD', share=D_opt, **D_opt_args) # D regularization optimizer
# Build training graph for each GPU.
# 为每个GPU建立训练图:trainable变量,训练数据集(的真实图像),定义损失函数,优化器注册梯度
data_fetch_ops = []
# 遍历每个GPU
for gpu in range(num_gpus):
# 指定以下Session在各个GPU上运行
with tf.name_scope('GPU%d' % gpu), tf.device('/gpu:%d' % gpu):
# Create GPU-specific shadow copies of G and D.
# 为每个序号大于0的GPU创建各自的 G 和 D 的shadow copies
G_gpu = G if gpu == 0 else G.clone(G.name + '_shadow')
D_gpu = D if gpu == 0 else D.clone(D.name + '_shadow')
# Fetch training data via temporary variables.
# 通过(临时)变量reals_var,labels_var获取真实图像和标签,用于投喂给判别器计算 D 的损失函数
# reals_var和labels_var是“不可训练”的
with tf.name_scope('DataFetch'):
# 根据当前使用(训练)的图像计数 cur_nimg,设定训练过程中的时间调度参数
sched = training_schedule(cur_nimg=int(resume_kimg*1000), training_set=training_set, **sched_args)
# 定义变量reals_var,labels_var
reals_var = tf.Variable(name='reals', trainable=False, initial_value=tf.zeros([sched.minibatch_gpu] + training_set.shape))
labels_var = tf.Variable(name='labels', trainable=False, initial_value=tf.zeros([sched.minibatch_gpu, training_set.label_size]))
# 从training_set中取下一个minibatch,赋值给reals_write、labels_write
reals_write, labels_write = training_set.get_minibatch_tf()
# 对reals_write、labels_write进行(预)处理,然后再投喂给网络
reals_write, labels_write = process_reals(reals_write, labels_write, lod_in, mirror_augment, training_set.dynamic_range, drange_net)
# 把reals_write拼接到reals_var的前面,[0:minibatch_gpu_in]
reals_write = tf.concat([reals_write, reals_var[minibatch_gpu_in:]], axis=0)
# 把labels_write拼接到labels_var的前面,[0:minibatch_gpu_in]
labels_write = tf.concat([labels_write, labels_var[minibatch_gpu_in:]], axis=0)
# 把reals_write赋值给reals_var,并记入data_fetch_ops列表
data_fetch_ops += [tf.assign(reals_var, reals_write)]
# 把labels_write赋值给labels_var,并记入data_fetch_ops列表
data_fetch_ops += [tf.assign(labels_var, labels_write)]
# 把reals_var的前minibatch_gpu_in个元素赋值给reals_read,[0:minibatch_gpu_in]
reals_read = reals_var[:minibatch_gpu_in]
# 把labels_var的前minibatch_gpu_in个元素赋值给labels_read,[0:minibatch_gpu_in]
labels_read = labels_var[:minibatch_gpu_in]
# Evaluate loss functions.
# 评价(定义)损失函数
lod_assign_ops = []
# 将lod_in赋值给G的变量lod与D的变量lod,放到lod_assign_ops列表中
if 'lod' in G_gpu.vars: lod_assign_ops += [tf.assign(G_gpu.vars['lod'], lod_in)]
if 'lod' in D_gpu.vars: lod_assign_ops += [tf.assign(D_gpu.vars['lod'], lod_in)]
# 在执行完lod_assign_ops后执行下面的session
# 动态导入对象(module),用名字(opt)找到一个Python对象并把它作为函数调用:call_func_by_name()见./dnnlib/util.py
with tf.control_dependencies(lod_assign_ops):
# 定义G_loss,G_reg
# 动态导入对象(module),用名字(opt)找到一个Python对象并把它作为函数调用:call_func_by_name()见./dnnlib/util.py
# G_loss_args:func_name='training.loss.G_logistic_ns_pathreg',前面为G_logistic_ns_pathreg()需要使用的参数
# 生成器使用G_logistic_ns_pathreg作为损失函数,独立于判别器自行迭代优化,理论上不能保证StyleGAN2会收敛达到纳什均衡,但工程上这么做是有效的
with tf.name_scope('G_loss'):
# Non-saturating logistic loss with path length regularizer
G_loss, G_reg = dnnlib.util.call_func_by_name(G=G_gpu, D=D_gpu, opt=G_opt, training_set=training_set, minibatch_size=minibatch_gpu_in, **G_loss_args)
# 定义D_loss,D_reg
# D_loss_args:func_name='training.loss.D_logistic_r1',前面为D_logistic_r1()需要使用的参数
# StyleGAN2对训练集提供的真实图片reals和由生成器制造的假图片fakes,一起投喂给判别器计算交叉熵损失函数D_logistic_r1,推动判别器的迭代优化
with tf.name_scope('D_loss'):
# R1 and R2 regularizers
D_loss, D_reg = dnnlib.util.call_func_by_name(G=G_gpu, D=D_gpu, opt=D_opt, training_set=training_set, minibatch_size=minibatch_gpu_in, reals=reals_read, labels=labels_read, **D_loss_args)
# Register gradients.
# 为优化器G_opt, D_opt注册梯度
if not lazy_regularization:
if G_reg is not None: G_loss += G_reg
if D_reg is not None: D_loss += D_reg
else:
# 如果选择了lazy_regularization,为优化器G_reg_opt, D_reg_opt注册梯度
# 使用lazy regularization策略时,loss和正则化项(regularizer)分别进行梯度下降优化
# G 是每4倍minibatch优化一次 R1 正则化项,D 是每16倍minibatch优化一次 PPL 正则化项
if G_reg is not None: G_reg_opt.register_gradients(tf.reduce_mean(G_reg * G_reg_interval), G_gpu.trainables)
if D_reg is not None: D_reg_opt.register_gradients(tf.reduce_mean(D_reg * D_reg_interval), D_gpu.trainables)
# 注册梯度
G_opt.register_gradients(tf.reduce_mean(G_loss), G_gpu.trainables)
D_opt.register_gradients(tf.reduce_mean(D_loss), D_gpu.trainables)
# Setup training ops.
# 设置(定义)训练操作
# 包括:读取真图像及标签data_fetch_op、训练生成器G_train_op、训练判别器D_train_op、生成器正则化项运算G_reg_op、判别器正则化项运算D_reg_op,
# 以及更新Gs变量Gs_update_op。
# 不采用lazy regularization时,G_reg_op、D_reg_op为空操作
# apply_updates()见./dnnlib/tflib/optimizer.py,支持多个GPU情况下基于梯度对注册变量进行更新
data_fetch_op = tf.group(*data_fetch_ops)
G_train_op = G_opt.apply_updates()
D_train_op = D_opt.apply_updates()
G_reg_op = G_reg_opt.apply_updates(allow_no_op=True)
D_reg_op = D_reg_opt.apply_updates(allow_no_op=True)
# 使用beta=Gs_beta,对 Gs 的各个变量进行线性插值计算(Lerp),用移动平均值更新 Gs 各变量
# Gs 用于生成训练过程中的假图像,使得 GPU 专注于训练而不被打扰
# setup_as_moving_average_of()见:./dnnlib/tflib/network.py
Gs_update_op = Gs.setup_as_moving_average_of(G, beta=Gs_beta)
# Finalize graph.
# 最后确定(整张)图
with tf.device('/gpu:0'):
# 读取GPU内存状态,最大占用字节数
try:
peak_gpu_mem_op = tf.contrib.memory_stats.MaxBytesInUse()
except tf.errors.NotFoundError:
peak_gpu_mem_op = tf.constant(0)
# 对所有未被初始化的变量进行初始化
# init_uninitialized_vars()见:.dnnlib/tflib/tfutil.py
tflib.init_uninitialized_vars()
# 初始化日志(文件)
print('Initializing logs...')
summary_log = tf.summary.FileWriter(dnnlib.make_run_dir_path())
if save_tf_graph:
summary_log.add_graph(tf.get_default_graph())
if save_weight_histograms:
G.setup_weight_histograms(); D.setup_weight_histograms()
metrics = metric_base.MetricGroup(metric_arg_list)
# 显示训练进度
print('Training for %d kimg...\n' % total_kimg)
dnnlib.RunContext.get().update('', cur_epoch=resume_kimg, max_epoch=total_kimg)
maintenance_time = dnnlib.RunContext.get().get_last_update_interval()
cur_nimg = int(resume_kimg * 1000)
cur_tick = -1
tick_start_nimg = cur_nimg
prev_lod = -1.0
running_mb_counter = 0
# 训练(迭代)循环
while cur_nimg < total_kimg * 1000:
if dnnlib.RunContext.get().should_stop(): break
# Choose training parameters and configure training ops.
# 训练参数,配置训练操作
# 调用training_schedule,确定当前(与训练进度相关)的minibatch_size、minibatch_gpu、lod、G_lrate、tick_kimg等参数
sched = training_schedule(cur_nimg=cur_nimg, training_set=training_set, **sched_args)
assert sched.minibatch_size % (sched.minibatch_gpu * num_gpus) == 0
# 设置当前的minibatch_gpu(每个GPU一次读取的minibatch大小)和lod
training_set.configure(sched.minibatch_gpu, sched.lod)
# 当开始新的lod layer的计算时,复位优化器的起始状态(即:Adam moments)
# reset_optimizer_state()见:./dnnlib/tflib/optimizer.py
if reset_opt_for_new_lod:
if np.floor(sched.lod) != np.floor(prev_lod) or np.ceil(sched.lod) != np.ceil(prev_lod):
G_opt.reset_optimizer_state(); D_opt.reset_optimizer_state()
prev_lod = sched.lod
# Run training ops.
# 执行训练操作
# feed_dict作为运行函数的可变参数
feed_dict = {lod_in: sched.lod, lrate_in: sched.G_lrate, minibatch_size_in: sched.minibatch_size, minibatch_gpu_in: sched.minibatch_gpu}
# minibatch_repeats:在调整训练参数前每个minibatch运行的次数(反复训练minibatch_repeats次)
for _repeat in range(minibatch_repeats):
# 步长为sched.minibatch_gpu * num_gpus,即:每个gpu一次读取的minibatch大小*gpu的个数
rounds = range(0, sched.minibatch_size, sched.minibatch_gpu * num_gpus)
# 如果lazy_regularization == True且running_mb_counter是G_reg_interval(或:D_reg_interval)的倍数
# G_reg_interval=4,D_reg_interval=16
# 使标志run_G_reg, run_D_reg有效
run_G_reg = (lazy_regularization and running_mb_counter % G_reg_interval == 0)
run_D_reg = (lazy_regularization and running_mb_counter % D_reg_interval == 0)
# 当前使用(训练)的图像计数累加
cur_nimg += sched.minibatch_size
# minibatch计数器累加
running_mb_counter += 1
# 执行的运算包括:
# 训练生成器G_train_op、读取真图像及标签data_fetch_op、训练判别器D_train_op、 更新Gs变量Gs_update_op
# 生成器正则化项运算G_reg_op、判别器正则化项运算D_reg_op
# Fast path without gradient accumulation.
# 如果rounds[]只有一个元素,即:sched.minibatch_size == sched.minibatch_gpu * num_gpus
# 使用dnnlib.tflib.run()运行函数
if len(rounds) == 1:
# 同时运行函数G_train_op和data_fetch_op,生成的假图像和读取的真图像构成一组数据,用于判别器loss计算
# G 使用G_logistic_ns_pathreg作为损失函数,独立于判别器自行迭代优化
tflib.run([G_train_op, data_fetch_op], feed_dict)
if run_G_reg: # Generater regularization,生成器正则化
tflib.run(G_reg_op, feed_dict)
# 同时运行函数D_train_op和Gs_update_op,更新判别器参数和Gs中各变量的移动平均值
# D 使用D_logistic_r1作为损失函数,与 G 一起完成“对抗”训练;更新 Gs 的各个变量,使之与 G 紧密相随
tflib.run([D_train_op, Gs_update_op], feed_dict)
if run_D_reg: # Discriminator regularization,判别器正则化
tflib.run(D_reg_op, feed_dict)
# Slow path with gradient accumulation.
# 否则,一步步来
# 使用dnnlib.tflib.run()运行函数:G_train_op、G_reg_op、Gs_update_op、data_fetch_op、D_train_op、D_reg_op
else:
for _round in rounds:
# 训练生成器 G
tflib.run(G_train_op, feed_dict)
if run_G_reg:
for _round in rounds:
# 计算生成器正则化项
tflib.run(G_reg_op, feed_dict)
# 更新 Gs 变量
tflib.run(Gs_update_op, feed_dict)
for _round in rounds:
# 读取真图像及标签
tflib.run(data_fetch_op, feed_dict)
# 训练判别器 D
tflib.run(D_train_op, feed_dict)
if run_D_reg:
for _round in rounds:
# 计算判别器正则化项
tflib.run(D_reg_op, feed_dict)
# Perform maintenance tasks once per tick.
# 打印运行信息,保存快照
# tick:时钟的滴答声,即:设定的维护时间点
done = (cur_nimg >= total_kimg * 1000)
# 如果是第一次,或者达到tick时间点,或者全部完成
if cur_tick < 0 or cur_nimg >= tick_start_nimg + sched.tick_kimg * 1000 or done:
cur_tick += 1
tick_kimg = (cur_nimg - tick_start_nimg) / 1000.0
tick_start_nimg = cur_nimg
tick_time = dnnlib.RunContext.get().get_time_since_last_update()
total_time = dnnlib.RunContext.get().get_time_since_start() + resume_time
# Report progress.
# 打印运行信息,训练的图片数量、lod、计时数据、内存峰值等
print('tick %-5d kimg %-8.1f lod %-5.2f minibatch %-4d time %-12s sec/tick %-7.1f sec/kimg %-7.2f maintenance %-6.1f gpumem %.1f' % (
autosummary('Progress/tick', cur_tick),
autosummary('Progress/kimg', cur_nimg / 1000.0),
autosummary('Progress/lod', sched.lod),
autosummary('Progress/minibatch', sched.minibatch_size),
dnnlib.util.format_time(autosummary('Timing/total_sec', total_time)),
autosummary('Timing/sec_per_tick', tick_time),
autosummary('Timing/sec_per_kimg', tick_time / tick_kimg),
autosummary('Timing/maintenance_sec', maintenance_time),
autosummary('Resources/peak_gpu_mem_gb', peak_gpu_mem_op.eval() / 2**30)))
autosummary('Timing/total_hours', total_time / (60.0 * 60.0))
autosummary('Timing/total_days', total_time / (24.0 * 60.0 * 60.0))
# Save snapshots.
# 使用当前迭代状态下的 Gs 生成假图片
# 保存快照,包括图片网格的图像和神经网络模型
if image_snapshot_ticks is not None and (cur_tick % image_snapshot_ticks == 0 or done):
grid_fakes = Gs.run(grid_latents, grid_labels, is_validation=True, minibatch_size=sched.minibatch_gpu)
misc.save_image_grid(grid_fakes, dnnlib.make_run_dir_path('fakes%06d.png' % (cur_nimg // 1000)), drange=drange_net, grid_size=grid_size)
if network_snapshot_ticks is not None and (cur_tick % network_snapshot_ticks == 0 or done):
pkl = dnnlib.make_run_dir_path('network-snapshot-%06d.pkl' % (cur_nimg // 1000))
misc.save_pkl((G, D, Gs), pkl)
metrics.run(pkl, run_dir=dnnlib.make_run_dir_path(), data_dir=dnnlib.convert_path(data_dir), num_gpus=num_gpus, tf_config=tf_config)
# Update summaries and RunContext.
# 更新概要和运行上下文
metrics.update_autosummaries()
tflib.autosummary.save_summaries(summary_log, cur_nimg)
dnnlib.RunContext.get().update('%.2f' % sched.lod, cur_epoch=cur_nimg // 1000, max_epoch=total_kimg)
maintenance_time = dnnlib.RunContext.get().get_last_update_interval() - tick_time
# Save final snapshot.
# 训练完成,保存训练网络的最终结果
misc.save_pkl((G, D, Gs), dnnlib.make_run_dir_path('network-final.pkl'))
# All done.
# 全部完成,关闭文件(句柄)
summary_log.close()
training_set.close()
阅读源代码的工作越来越枯燥,代码本身的逻辑也越来越复杂,希望上面分析的这些内容,对特别爱学习的你能有所帮助!
(完)