看小伙是怎么发现CSDN前10大佬之间的关系的
看小伙是怎么发现CSDN前10大佬之间的关系的
- 前言
- 一、获取排行数据
- 二、获取关注列表
- 三、绘制关系图
-
- 1.创建关注关系
- 2.绘制关系图
- 3.结果展示
- 写在最后
前言
大家都知道,CSDN总榜的地址是:
https://blog.csdn.net/rank/writing_rank_total
打开网页,我肃然起敬,那里都是一位位大佬。而我却遥遥不可及,唯有长叹息以励己。
也许大家跟我一样都怀着一颗好奇的心:排名Top10的大佬它们之间究竟有什么关系呢?(他们是否相互关注?)
于是,今天kimol君要干的便是这件事。
一、获取排行数据
通过简单的抓包可以找到排行榜数据的接口:
https://blog.csdn.net/api/WritingRank/totalList
注:这里的api地址与上文提到的榜单地址有所不同
定义获取榜单数据的函数:
def get_ranks():
'''
获取CSDN前10的博主信息(排名,用户id,用户昵称)
'''
url = 'https://blog.csdn.net/api/WritingRank/totalList'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Referer': 'https://blog.csdn.net/rank/writing_rank_total',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive',
'TE': 'Trailers',
}
params = (
('username', 'kimol_justdo'),
('page', '1'),
('size', '10'),
)
res = requests.get(url, headers=headers, params=params)
data = res.json()
users = data['data']['list']
ranks = []
for i in range(len(users)):
ranks.append((i+1,users[i]['username'],users[i]['user_nickname']))
return ranks
获取总榜单的数据,返回前10的数据,包含(排名、用户名、用户昵称)三个字段。
二、获取关注列表
想要分析大佬之间的关系,我们必须拿到他们的关注列表,分析他们之间是否存在相互关注的关系。关注列表的页面为:
https://me.csdn.net/follow/xxxx
其中xxxx表示用户名,则可以定义相关函数如下:
def get_follows(username):
'''
获取博主的关注列表(最多获取20位)
'''
url = 'https://me.csdn.net/follow/%s'%username
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
}
res = requests.get(url,headers=headers)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
follows = soup.find_all(class_='user_name')
follows = [f.text.strip() for f in follows]
return follows
返回的数据为该博主关注的用户昵称的列表(最多能获取到20个)。
三、绘制关系图
利用python中的networkx库来绘制TOP10博主相互关注的关系网络图。
1.创建关注关系
利用一、二中的函数,创建关注列表:
# 获取排名前10的博主,以及关注列表
ranks = get_ranks()
follow_list = []
for r in ranks:
follows = get_follows(r[1]) # 根据username获取关注列表
follows = follows[:3] # 取前3
for f in follows:
follow_list.append((r[2],f)) # 添加关注关系(nickname,nickname)
为了防止网络图过于繁杂,不便于观看,我们只取每名博主关注列表中的前3名。最后的关系(即1个二元组)列表如下:

2.绘制关系图
根据关系列表,用networkx库来绘制相应的关系网络图,代码如下:
# 定义网络图
G = nx.DiGraph()
G.add_edges_from(follow_list) # 添加网络边
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
# 定义颜色参数
val_map = {
}
color_value = 0.6
for r in ranks:
val_map[r[2]] = color_value
color_value -= 0.06
values = [val_map.get(node,0.5) for node in G.nodes()]
# 绘制网络图
pos = nx.spring_layout(G)
nx.draw_networkx_nodes(G,pos,cmap=plt.get_cmap('jet'),node_color=values) # 绘制节点
nx.draw_networkx_labels(G,pos,font_weight=1.0) # 绘制标签
nx.draw_networkx_edges(G,pos,edgelist=G.edges(),edge_color='gold',arrows=True) # 绘制边
plt.show(
关于networkx库的详细用法,我就不过多介绍了,大家可以参考—>Python Network(一)基础入门(节点和边基本概念,网络统计量)。
3.结果展示
TOP10博主相互关注关系图如下:
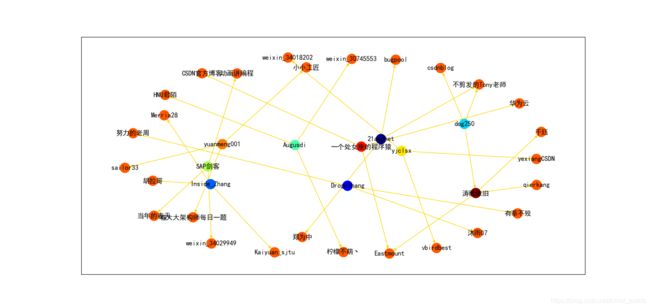
注:这里为了简洁美观只选取了每名博主前3的关注对象,所以结果不会很准确,仅作为参考。
从图可以看出:大佬们之间似乎不存在明显的相互关注的现象,而且他们关注的博主重复率也很低,这与我一开始的猜想还是有一点点差别的。这大概是因为各位博主大大各有所长,专注于不同的领域。
当然,这也很可能与我选取的数据量不够大有着莫大关系。如果有感兴趣的小伙伴,欢迎一起进一步研究哦~
写在最后
讲道理,我个人觉得这个关系图属实有点丑。如果后续有时间的话,我会考虑用pyecharts来重新绘制一个图,设想是:可以更加美观,可以把博主的头像作为节点,颜色更加丰富,可以把排名凸显出来…害~ 幻想总是美好的,有空的话就把它实现了叭。
最后,感谢各位大大的耐心阅读,咋们下次再会~
创作不易,大侠请留步… 动起可爱的双手,来个赞再走呗 (๑◕ܫ←๑)