原文链接:http://tecdat.cn/?p=11878
Nelson-Siegel- [Svensson]模型是拟合收益曲线的常用方法。它的优点是其参数的经济可解释性,被银行广泛使用。但它不一定在所有情况下都有效:模型参数有时非常不稳定,无法收敛。
在之前的文章中,我们提供了Nelson-Siegel模型收敛失败的示例,我们已经展示了它的一些缺陷。
蒙特卡洛模拟帮助我们理解:
3. for(j in 1:N_SIMULATIONS)
5. {
10. npo = c(newYields, oldYields)
12. plot(MATURITY_BASES, oldYields, ylim=c(min(npo), max(npo)))
14. lines(MATURITY_BASES, oldYields)
16. points(MATURITY_BASES, newYields, col="red", pch=4)
18. points(newMATs, newNsYields, col="blue")
20. lines(newMATs, newNsYields, col="blue")
我们要做的是:从一些收益率曲线开始,然后逐步地随机修改收益率,最后尝试NS模型拟合新的收益。因此我们对此进行了模拟。
对于Nelson-Siegel模型,此Monte-Carlo模拟尽管假定前一步的收益(旧收益率) 与NS曲线_完全_匹配。但是,即使如此也无法完全避免麻烦。我们如何发现这些麻烦?在每一步中,我们计算两条相邻曲线之间的最大距离(supremum-norm):
maxDistanceArray[j] = max( abs(oldYieldsArray[j,] - newNsYieldsArray[j,]) )最后,我们找到到上一条曲线的最大距离的步骤,这就是收敛失败的示例。
_maxDistanceArray_的概率密度 如下所示:

分布尾部在0.08处减小,但对于收益率曲线而言,每天偏移8个点并不罕见。因此,尽管我们进行了1e5 = 10000蒙特卡洛模拟,但只有极少数情况,我们可以将其标记为不良。训练神经网络绝对是不够的。而且,两条Nelson-Siegel曲线可能彼此非常接近,但其参数却彼此远离。由于模型是线性的, 因此可以假设beta的极大变化(例如,超过95分位数)是异常值,并将其标记为不良。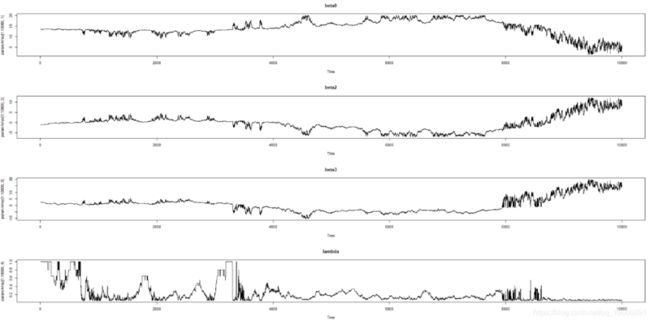
3. idx = intersect(intersect(which(b0 < q_b0), which(b1 < q_b1)), which(b2 < q_b2))
5. par(mfrow=c(3,3))
7. plot(density(log(b0)))
9. plot(density(log(b1)))
11. plot(density(log(b2)))
13. plot(density(log(b0[idx])))
15. plot(density(log(b1[idx])))
17. plot(density(log(b2[idx])))
19. plot(density(b0[idx]))
21. plot(density(b1[idx]))
23. plot(density(b2[idx]))
29. b0 = b0-mean(b0)
31. b1 = b1-mean(b1)
33. b2 = b2-mean(b2)
37. #训练神经网络
39. X = cbind(b0, b1, b2)
41. Y = array(0, dim=(N_SIMULATIONS-1))
43. Y[idx] = 1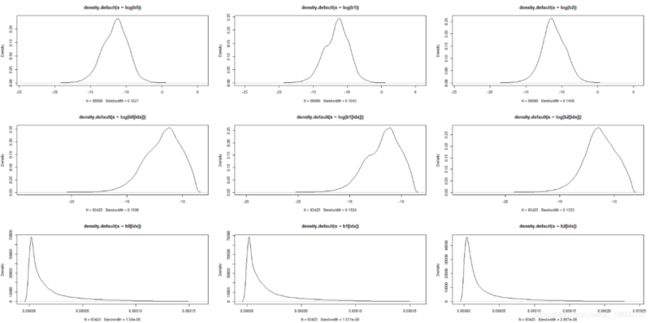
然后我们可以训练神经网络
1. SPLT = 0.8
3. library(keras)
5. b = floor(SPLT*(N_SIMULATIONS-1))
14. plot(history)
16. model %>% evaluate(x_test, y_test)

神经网络不仅在样本而且在验证集上都提供了高精度。
如果模拟新数据集,对模型进行修改 :例如修改VOLAs = 0.005*sqrt(MATURITY_BASES) 到 VOLAs = 0.05*sqrt(MATURITY_BASES) 将无法识别新数据集上的不良情况。
不足与展望:尽管我们在两种情况下均对数据进行了归一化和平均化,但是模型波动性的线性变化对尾部分位数具有很高的非线性影响。
那么,我们是否需要一个更复杂的AI模型?

最受欢迎的见解
1.用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
2.Python中利用长短期记忆模型LSTM进行时间序列预测分析 – 预测电力消耗数据
4.Python中用PyTorch机器学习分类预测银行客户流失模型
6.在r语言中使用GAM(广义相加模型)进行电力负荷时间序列分析