HDFS学习笔记
Hadoop—HDFS学习笔记
文章目录
- Hadoop---HDFS学习笔记
-
- 引言 --- Big Data
-
- Big Data特点
- 大数据面临的问题?
- Hadoop
-
- Apache Hadoop由来:
- Hadoop Eco System (hadoop的生态系统圈)
- 大数据分析方案哪些?
- HDFS 环境搭建(伪分布式单机-测试|学习)
-
- 1. 准备
- 2. 安装JDK并配置JAVA环境
- 3. 配置主机名和IP映射关系
- 4. 关闭防火墙服务
- 5. 配置主机SSH免密码认证(密匙)
- 6. 安装Hadoop并且配置HADOOP_HOME环境变量
- 7. 修改 core-site.xml 配置文件
- 8. 修改 hdfs-site.xml 配置文件
- 9. 修改 slaves 配置文件
- 10. 格式化namenode
- 11. 启动hdfs
- 12. 测试
- HDFS
-
- HDFS架构篇
- HDFS常⻅问题
-
- HDFS为什么不擅⻓⼩⽂件的存储?
- NameNode和Secondary Namenode的关系?
- 常⽤指令
-
- 1. 格式化⼀个新的分布式⽂件系统
- 2. 启动 NameNode 守护进程和 DataNode 守护进程
- 3. 浏览 NameNode 的⽹络接⼝
- 4.HDFS Shell
- 5. mkdir
- 6. ls
- 7. put
- 8. get
- 9.appendToFile
- 10. cat || tail || text
- 11. checksum
- 12. chmod || chgrp || chown
- 13. copyFromLocal/copyToLocal
- 14. cp
- 15. moveFromLocal|moveToLocal
- 16. rm
- 17. mv
- 18. touchz
- 19. distcp
引言 — Big Data
Big Data特点
Big Data(大数据),或称巨量资料,指的是所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。Big Data大数据,谈的不仅仅是数据量,其实包含了数据量(Volume)、时效性(Velocity)、多样性(Variety)、可疑性(Veracity)。
Volume:
数据量,大量数据的产生、处理、保存,谈的就是Big Data就字面上的意思,就是谈海量数据。
Velocity:时效性,就是处理的时效,既然前头提到Big Data其中一个用途是做市场预测,那处理的时效如果太长就失去了预测的意义了,所以处理的时效对Big Data来说也是非常关键的,500万笔数据的深入分析,可能只能花5分钟的时间。
Variety[vəˈraɪɪti]:多变性指的是数据的形态,包含文字、影音、网页、串流等等结构性、非结构性的数据。
Veracity[vəˈræsɪti]:可疑性指的是当数据的来源变得更多元时,这些数据本身的可靠度、质量是否足够,若数据本身就是有问题的,那分析后的结果也不会是正确的。
大数据面临的问题?
存储:单机存储有限,如何解决海量数据存储?
分析:如何在合理时间范围内对数据完成节本运算?
分布式:通常将跨机器/跨进程/跨虚拟机架构称为分布式架构,因为硬件垂直提升成本较高且不可控,相比较提升硬件水平横向扩展成本较低,能够使得投入和产出趋近于线性。
Hadoop
Apache Hadoop由来:
2003年谷歌发表三篇论文(不开源) :
GFS:Google File System,为大数据集的存储而生,
Map-Reduce:并行计算框架,
Big Table: 大表 ,存储海量的结构化数据
hadoop创始人Doug Cutting基于google论文提供了其开源实现(山寨版)
GFS —> HDFS(Hadoop distributed File System)
Map-Reduce —> MapReduce
Big Table —> HBase(基于列存储的NOSQL数据库)
2006年 hadoop正式诞生
2008年 加入Apache开源基金会,成为其顶级项目之一。
hadoop作为开源软件,拥有可靠,可扩展,分布式计算(存储和并行计算)的能力。apache hadoop 软件库是一个框架,允许使用简单的编程模型分布式处理大型的数据集(GB\TB级) 跨机器处理。hadoop集群的规模支持扩展,可以有一台或者上千台服务器构成,集群中的每一台服务器都提供了本地计算和存储能力。通过软件检测处理错误,因为hadoop集群可以构建在廉价的服务器硬件基础之上,廉价就意味着硬件不稳定,主要通过软件弥补这些缺陷。
Hadoop Eco System (hadoop的生态系统圈)
HDFS:分布式存储系统
MapReduce:并行计算框架
Hbase:基于HDFS之上一款NoSQL数据库(名符其实海量数据存储解决方案)
hive:一款SQL的解析引擎,可以将SQL翻译成MapReduce任务,将任务提交给MapReduce框架.
flume:分布式日志采集系统,用于搜集海量数据,并且存储到HDFS/Hbase.
Kafka:分布式消息系统,实现分布系统间解耦和海量数据的缓冲.
zookeeper:分布式协调服务,用于服务注册中心/配置中心/集群选举/状态监测/分布式锁
大数据分析方案哪些?
MapReduce:代表基于磁盘离线大数据静态批处理框架-延迟较高30分钟+
Spark:代表基于内存近实时(离线)大数据静态批处理框架-几乎是Map Reduce的10~100倍速度
Storm|Spark Streaming| Flink|Kafka Stream:实时的流(流程)处理框架,达到对记录级别的数据显示毫秒级处理.
HDFS 环境搭建(伪分布式单机-测试|学习)
1. 准备
一台安装Linux操作系统的虚拟机,JDK安装包,Hadoop HDFS安装包
VMWARE虚拟机安装64位CentOS,IntelVTx处于禁用状态 解决方式:
https://blog.csdn.net/yuzongtao/article/details/44700927
资源下载地址:http://www.apache.org/dist/hadoop/common/
2. 安装JDK并配置JAVA环境
[root@CentOS ~]# rpm -ivh jdk-8u171-linux-x64.rpm
# 用户变量
[root@CentOS ~]# vi /root/.bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOS ~]# source /root/.bashrc
#查看java环境
[root@CentOS ~]# jps
1495 Jps
尝试[root@CentOS ~]# yum install lrzsz -y组件,如果用户将JAVA_HOME配置在系统变量中/etc/profile需要在安装hadoop时候额外配置etc/hadoop/hadoop-env.sh,因此推荐配置在用户变量中.
3. 配置主机名和IP映射关系
[root@CentOS ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# 添加主机名和IP映射关系
192.168.169.139 CentOS
在分布式系统中很多服务都是以主机名标示节点,因此配置IP和主机名的映射关系.用户可以查看以下文件
[root@CentOS ~]# cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=CentOS
4. 关闭防火墙服务
# ContOS 6 关闭防火墙服务
[root@CentOS ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
# ContOS 7 关闭防火墙服务
[root@CentOS ~]# systemctl stop firewalld
# ContOS 6 关闭防火墙服务开机自起
[root@CentOS ~]# chkconfig iptables off
# ContOS 7 关闭防火墙服务开机自起
[root@hdfs ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
因为搭建分布式服务之间可能会产生相互的调度,为了保证正常的通信,一般需要关闭防火墙
5. 配置主机SSH免密码认证(密匙)
SSH 为 Secure Shell 的缩写,⼀种加密的⽹络传输协议,提供免密远程登录系统功能。Hadoop通过SSH执⾏指令远程管理Hadoop集群。SSH 为建立在应用层基础上的安全协议,专为远程登录会话和其他网络服务提供安全性的协议。
基于口令的安全验证:基于口令 用户名/密码
基于密匙的安全验证:
需要依靠密匙,也就是你必须为自己创建一对密匙,并把公用密匙放在需要访问的服务器上。如果你要连接到SSH服务器上,客户端软件就会向服务器发出请求,请求用你的密匙进行安全验证。服务器收到请求之后,先在该服务器上你的主目录下寻找你的公用密匙,然后把它和你发送过来的公用密匙进行比较。如果两个密匙一致,服务器就用公用密匙加密“质询”(challenge)并把它发送给客户端软件。客户端软件收到“质询”之后就可以用你的私人密匙解密再把它发送给服务器。
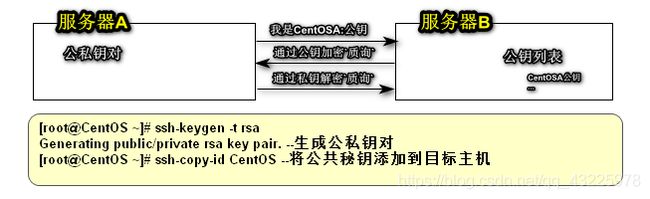
[root@node1 ~]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[root@node1 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@node1 ~]# chmod 0600 ~/.ssh/authorized_keys
6. 安装Hadoop并且配置HADOOP_HOME环境变量
参考:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
[root@centos ~]# tar -zxf hadoop-2.6.0_x64.tar.gz -C /usr/
进入 hadoop-2.6.0/lib/native
使用file命令:
file libhadoop.so.1.0.0
可查看当前hadoop版本的位数
# tree可以不安装,主要用于结构化显示目录内容
[root@centos ~]# yum install -y tree
[root@centos ~]# tree -L 1 /usr/hadoop-2.6.0/
/usr/hadoop-2.6.0/
|-- bin -- 基础指令 hadoop、hdfs指令
|-- etc -- 配置⽬录(重要)
|-- include
|-- lib
|-- libexec
|-- LICENSE.txt
|-- NOTICE.txt
|-- README.txt
|-- sbin -- 系统命令 start|stop-dfs|yarn.sh|hadoop-daemon.sh
|-- share -- hadoop依赖jar⽂件
7 directories, 3 files
# 配置HADOOP_HOME
[root@centos ~]# vi .bashrc
HADOOP_HOME=/usr/hadoop-2.6.0
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME
export CLASSPATH
export HADOOP_HOME
export PATH
# 是配置生效
[root@centos ~]# source .bashrc
# 查看是否配置成功
[root@centos ~]# hadoop classpath
/usr/hadoop-2.6.0/etc/hadoop:/usr/hadoop2.6.0/share/hadoop/common/lib/*:/usr/hadoop2.6.0/share/hadoop/common/*:/usr/hadoop-2.6.0/share/hadoop/hdfs:/usr/hadoop2.6.0/share/hadoop/hdfs/lib/*:/usr/hadoop-2.6.0/share/hadoop/hdfs/*:/usr/hadoop2.6.0/share/hadoop/yarn/lib/*:/usr/hadoop-2.6.0/share/hadoop/yarn/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/lib/*:/usr/hadoop2.6.0/share/hadoop/mapreduce/*:/usr/hadoop2.6.0/contrib/capacity-scheduler/*.jar
HADOOP_HOME环境变量被第三方产品所依赖例如:hbase/hive/flume/Spark在集成Hadoop的时候,是通过读取HADOOP_HOME环境变量确定HADOOP位置.
7. 修改 core-site.xml 配置文件
# 进入hadoop安装目录对core-site.xml进行编辑
[root@centos hadoop-2.6.0]# vim etc/hadoop/core-site.xml
# 将节点名node1,修改为对应的主机IP
fs.defaultFS
hdfs://node1:9000
# 元数据存储目录
hadoop.tmp.dir
/usr/hadoop-2.6.0/hadoop-${user.name}
8. 修改 hdfs-site.xml 配置文件
# 进入hadoop安装目录对hdfs-site.xml进行编辑
[root@centos hadoop-2.6.0]# vim etc/hadoop/hdfs-site.xml
dfs.replication
# 数字表示数据复制几份
1
# 用户访问数据是权限释放方面的配置
dfs.permissions.enabled
false
# HDFS DataNode对它将在任何时间服务的文件数量有一个上限
dfs.datanode.max.transfer.threads
4096
9. 修改 slaves 配置文件
# 进入hadoop安装目录对 slaves 进行编辑
[root@centos hadoop-2.6.0]# vim etc/hadoop/slaves
node1
10. 格式化namenode
[root@centos hadoop-2.6.0]# bin/hdfs namenode -format
namenode格式化只需要在初次使⽤hadoop的时候执⾏,以后⽆需每次启动执⾏
11. 启动hdfs
[root@centos hadoop-2.6.0]# sbin/start-dfs.sh
12. 测试
[root@centos ~]# jps
2151 Jps
2049 SecondaryNameNode
1915 DataNode
1809 NameNode
或者
⽤户可以访问http://ip:50070访问namenode的web-ui
HDFS
HDFS是Hadoop的分布式⽂件系统(Hadoop Distributed File System ),类似于其它的分布式⽂件,如FastDFS。
HDFS⽀持⾼度容错,可以部署在廉价的硬件设备上,特别适宜于⼤型的数据集的分布式存储。
HDFS架构篇
HDFS采⽤master/slave架构。⼀个HDFS集群是由⼀个Namenode和⼀定数⽬的Datanodes组成。
Namenode是⼀个中⼼服务器,负责管理⽂件系统的名字空间(namespace)以及客户端对⽂件的访问。
集群中的Datanode⼀般是⼀个节点⼀个,负责管理它所在节点上的存储。HDFS暴露了⽂件系统的名字空间,⽤户能够以⽂件的形式在上⾯存储数据。从内部看,⼀个⽂件其实被分成⼀个或多个数据块,这些块存储在⼀组Datanode上。Namenode执⾏⽂件系统的名字空间操作,⽐如打开、关闭、重命名⽂件或⽬录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理⽂件系统客户端的读写请求。在Namenode的统⼀调度下进⾏数据块的创建、删除和复制。
Namenode: 存储系统元数据、namespace、管理datanode、接受datanode状态汇报
Datanode: 存储块数据,响应客户端的块的读写,接收namenode的块管理指令
Block: HDFS存储数据的基本单位(块),默认值是128MB,实际块⼤⼩0~128MB
Rack: 机架,对datanode所在主机的物理标识,标识主机的位置,优化存储和计算

namenode:存储系统的元数据(用于描述数据的数据,内存),例如 文件命名空间/block到datanode的映射.负责管理datanode
datanode:用于存储数据块的节点.负责响应客户端对块的读写请求,向namenode汇报自己块信息.
block:数据块,是对文件拆分的最小单位,表示一个切分尺度默认值128MB,每个数据块的默认副本因子是3,通过dfs.replication进行配置,用户可以通过dfs.blocksize设置块大小
rack:机架,使用机架对存储节点做物理编排,用于优化存储和计算.
查看机架:
[root@CentOS ~]# hdfs dfsadmin -printTopology
Rack: /default-rack
192.168.169.139:50010 (CentOS)
HDFS常⻅问题
HDFS为什么不擅⻓⼩⽂件的存储?
| 文件 | namenode占用(内存) | datanode占用磁盘 |
|---|---|---|
| 128MB 单个文件 | 1个block元数据信息 | 128MB * 副本因子 |
| 128MB 10000个文件 | 10000个block元数据信息 | 128MB * 副本因子 |
原因:
- 小文件过多会浪费namenode资源 (杀鸡用牛刀)
- HDFS适⽤于⾼吞吐量,⽽不适合低时间延迟的访问。⽂件过⼩,寻道 时间⼤于数据读写时间,这不符合HDFS的设计
NameNode和Secondary Namenode的关系?
Namenode主要维护两个⽂件,⼀个是 fsimage ,⼀个是 editlog。
fsimage保存了最新的元数据检查点,包含了整个HDFS⽂件系统的所有⽬录和⽂件的信息。
对于⽂件来说包括了数据块描述信息、修改时间、访问时间等;对于⽬录来说包括修改时间、
访问权限控制信息(⽬录所属⽤户,所在组)等。editlog主要是在NameNode已经启动情况下对HDFS进⾏的各种更新操作进⾏记录,HDFS客户
端执⾏所有的写操作都会被记录到editlog中。
为了避免editlog不断增⼤,secondary namenode会周期性合并fsimage和edits成新的fsimage。
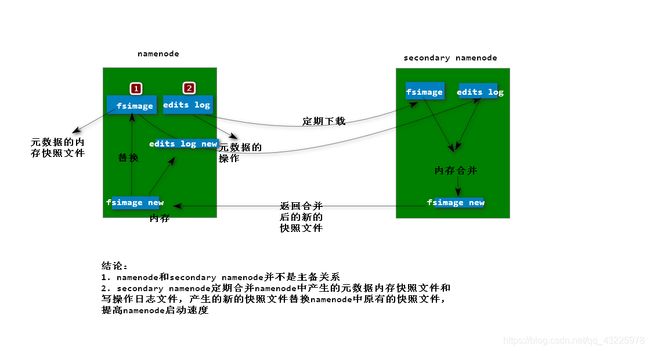
所以secondary namenode辅助NameNode整理Edits和Fsimage文件,加速NameNode启动过程。
secondary namenode与NameNode 存在联系,但并不是主备关系
疑惑:namenode 存在单点故障问题? 伪分布式环境下 确实存在
完全分布式HDFS集群中 支持namenode主备 不存在单点故障
常⽤指令
1. 格式化⼀个新的分布式⽂件系统
[root@CentOS ~]# hdfs namenode -format
2. 启动 NameNode 守护进程和 DataNode 守护进程
[root@CentOS ~]# start-dfs.sh
Hadoop 守护进程的⽇志写⼊到 $HADOOP_LOG_DIR ⽬录(默认是 $HADOOP_HOME/logs )
3. 浏览 NameNode 的⽹络接⼝
[root@CentOS ~]# NameNode - http://ip地址:50070/
4.HDFS Shell
# 帮助
[root@CentOS ~]# hdfs dfs -help
Usage: hadoop fs [generic options]
[-appendToFile ... ]
[-cat [-ignoreCrc] ...]
[-checksum ...]
[-chmod [-R] PATH...]
[-copyFromLocal [-f] [-p] [-l] ... ]
[-copyToLocal [-p] [-ignoreCrc] [-crc] ... ]
[-cp [-f] [-p | -p[topax]] ... ]
[-get [-p] [-ignoreCrc] [-crc] ... ]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [ ...]]
[-mkdir [-p] ...]
[-moveFromLocal ... ]
[-moveToLocal ]
[-mv ... ]
[-put [-f] [-p] [-l] ... ]
[-rm [-f] [-r|-R] [-skipTrash] ...]
[-rmdir [--ignore-fail-on-non-empty] ...]
[-tail [-f] ]
[-text [-ignoreCrc] ...]
[-touchz ...]
[-usage [cmd ...]]
5. mkdir
# 创建⽬录
[root@CentOS ~]# hdfs dfs -mkdir -p path
6. ls
# 展示指令⽬录内容清单
[root@CentOS ~]# hdfs dfs -ls path
7. put
# ⽂件上传
[root@CentOS ~]# hdfs dfs -put localsrc dst
8. get
# ⽂件下载
[root@CentOS ~]# hdfs dfs -get src localdst
9.appendToFile
[root@CentOS ~]# hdfs dfs -appendToFile /root/install.log /aa.log
10. cat || tail || text
# 查看内容
[root@CentOS ~]# hadoop fs -cat /aa.log
[root@CentOS ~]# hdfs dfs -tail path
[root@CentOS ~]# hdfs dfs -text /cc.log
11. checksum
[root@CentOS ~]# hdfs dfs -checksum /aa.log
/aa.log MD5-of-0MD5-of-512CRC32C 000002000000000000000000fa622ce196be3efd11475d6b55af76d2
12. chmod || chgrp || chown
# 权限相关
[root@CentOS ~]# hdfs dfs -chgrp [-R] GROUP PATH...
[root@CentOS ~]# hdfs dfs -chmod [-R] PATH
[root@CentOS ~]# hdfs dfs -chown [-R] [OWNER][:[GROUP]] PATH
13. copyFromLocal/copyToLocal
[root@CentOS ~]# hdfs dfs -copyFromLocal|-put install.log / # 上传
[root@CentOS ~]# hdfs dfs -copyToLocal|-get /install.log ~/ # 下载
14. cp
[root@CentOS ~]# hdfs dfs -mkdir -p /demo/dir
# 复制
[root@CentOS ~]# hdfs dfs -cp /install.log /demo/dir
15. moveFromLocal|moveToLocal
[root@CentOS ~]# hdfs dfs -moveFromLocal ~/install.log /
[root@CentOS ~]# ls
anaconda-ks.cfg hadoop-2.6.0_x64.tar.gz install.log.syslog
[root@CentOS ~]# hdfs dfs -moveToLocal /install.log ~/ # 目前还没有实现
moveToLocal: Option '-moveToLocal' is not implemented yet.
16. rm
# ⽂件删除
[root@CentOS ~]# hdfs dfs -rm -r -f /install.log
17. mv
# 移动
[root@CentOS ~]# hdfs dfs -mv /install.log /bb.log
18. touchz
[root@CentOS ~]# hdfs dfs -touchz /cc.log
19. distcp
[root@CentOS ~]# hadoop distcp hdfs://CentOS:9000/aa.log hdfs://CentOS:9000/demo/dir^C
更多参考:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FileSystemShell.html#appendToFile