李宏毅2020机器学习深度学习(2) 分类 笔记+作业

目录
- 1. 背景知识
-
- 1.1 数学基础回顾
- 1.2 用MLE估计类别分布中的参数
- 1.3 二分类问题与logistic激活函数
- 1.4 判别模型与logistic回归
- 1.5 总结判别式模型和生成模型
- 1.6 朴素贝叶斯分类器
- 2. 作业描述
- 3. 数据预处理
- 4. 使用logistic回归
-
- 4.1 建立模型
- 4.2 完整代码
- 5. 使用生成模型
-
- 5.1 建立模型
- 5.2 完整代码
1. 背景知识
1.1 数学基础回顾
方差用来度量随机变量和其数学期望(即均值)之间的偏离程度,而协方差则一般用来度量两个随机变量的相似程度
方差的计算公式为: 
协方差的计算公式为:
方差可视作随机变量x关于其自身的协方差
对于这些随机变量,我们还可以根据协方差的定义,求出两两之间的协方差
因此,协方差矩阵为
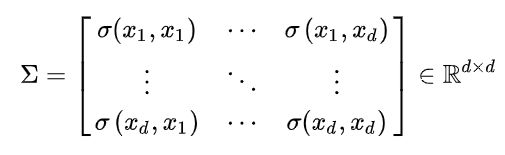

交叉熵:

极大似然估计:



1.2 用MLE估计类别分布中的参数
线性回归不能很好地完成分类任务,以二元分类为例,二维平面右下角的样本会干扰回归模型的参数

理想的解决方法是找到一个函数g(x),根据g(x)的大小分类

现在假设某一类的所有的样本都由一个多元高斯分布抽样得到。(假设的是P(x|C)符合多元高斯分布)

然后要试图找到这个高斯分布**( 用MLE最大似然估计 )。**

发现最优解很符合我们的想象。

找到每一类数据对应的分布之后。

就可以计算一个新数据,属于某一类的概率,进而可以完成分类任务

让两个类对应的高斯分布使用同一个协方差矩阵,边界会变成一条直线

1.3 二分类问题与logistic激活函数
从后验概率引出sigmoid函数

省略数学推导,一顿变形
又出现了我们喜欢的线性回归的形式

这里解释了为什么协方差矩阵相同时,分界线会是线性的。
在生成模型中,我们需要估计高斯分布的参数,带入上式,计算w.x + b,进而计算P(C1|x)
那么能否直接寻找w和b呢?
带着这个问题,进入下一节
1.4 判别模型与logistic回归

假设一组训练数据如下:

某一组w,b产生这组训练数据的概率为:
依旧由最大似然的思想求使L(w,b)最大的w,b的值,等效于求右式

化简计算后可得

对wi求偏导,根据链式法则,先对z求偏导

最终化简结果如下

注:x i n _i^n in为第n个输入数据的第i个维度,求和是对所有n个输入数据求和
与线性回归作比较

1.5 总结判别式模型和生成模型

两种方法找出的w, b不会是同一组
生成式模型的优点

1.6 朴素贝叶斯分类器
朴素贝叶斯分类器采用了“属性条件独立性假设”,假设所有属性相互独立。换言之,每个属性独立地对分类结果发生影响。

下例为使用朴素贝叶斯产生的反常识结果,因为它认为所有的特征条件都是独立的,抽样够多时在class2中也会得到(1,1)的结果。两类样本分布的不均衡也对预测结果产生了影响。
这样的假设也是引入的先验知识。

2. 作业描述
根据人们的个人资料,做一个二元分类,判断其年收入是否高于50000美元。
不妨认为收入大于50000美元的预测值为1,反之则为0。
3. 数据预处理
数据如图所示

train.csv 和 test_no_label.csv为原始资料
实际用到的为X_train、Y_train 和 X_test这3个处理过的数据集
读取X_train,可见许多属性的值已经被自动替换为0和1,一共有510个特征决定最后的分类结果

4. 使用logistic回归
4.1 建立模型

系数矩阵w和偏差值b由梯度下降法得到
4.2 完整代码
详细过程请看注释
import numpy as np
import matplotlib.pyplot as plt
def _normalize(X, train = True, specified_column = None, X_mean = None, X_std = None):
# 这个函数用于标准化输入数据的特定列
# 训练数据的平均值与标准差将在处理测试数据时重复使用
#
# 参数Arguments:
# X: 待处理数据
# train: 'True'表示处理训练数据,'False'表示处理测试数据
# specific_column: 需要标准化处理的列索引,如果为'None',则处理所有列
# X_mean: 训练数据的平均值
# X_std: 训练数据的标准差
# 输出Outputs:
# X:标准化后的数据
# X_mean: 计算出的训练数据平均值
# X_std: 计算出的训练数据标准差
if specified_column == None:
specified_column = np.arange(X.shape[1]) # 计算列数
if train:
# 计算每列的平均之后变为一行
X_mean = np.mean(X[:, specified_column], 0).reshape(1, -1)
# 计算每列的标准差后变为一行
X_std = np.std(X[:,specified_column], 0).reshape(1, -1)
X[:, specified_column] = (X[:, specified_column] - X_mean)/(X_std + 1e-8)
return X, X_mean, X_std
def _train_dev_split(X, Y, dev_ratio = 0.25):
# 此函数将数据切分training set和development set
# 注:development set:用来对训练集训练出来的模型进行测试,通过测试结果来不断地优化模型。
# test set:在训练结束后,对训练出的模型进行一次最终的评估所用的数据集。
train_size = int(len(X) * (1 - dev_ratio))
return X[:train_size],Y[:train_size],X[train_size:], Y[train_size:]
def _shuffle(X, Y):
# 生成两个等长的随机列表
randomize = np.arange(len(X))
np.random.shuffle(randomize)
return (X[randomize], Y[randomize])
def _sigmoid(z):
# 用于预测的sigmoid函数
# 限制输出值的范围为1e-8, 1-(1e-8)
return np.clip(1 / (1.0 + np.exp(-z)), 1e-8, 1 - (1e-8))
def _f(X, w, b):
# 这是一个逻辑回归函数
#
# 参数
# X: 输入数据, shape = [batch_size, data_dimension]
# w: weight vector, shape = [data_dimension, ]
# b: 偏置 bias, scalar
# 输出
# 预测X的每行被预测为1的概率,shape = [batch_size, ]
return _sigmoid(np.matmul(X, w) + b) # 两个numpy数组的矩阵相乘
def _predict(X, w, b):
# 根据逻辑回归结果预测分类
# 实际利用了round函数的四舍五入,将结果输出为0, 1
return np.round(_f(X, w, b)).astype(np.int)
def _arruracy(Y_pred, Y_label):
# 计算预测准确度
acc = 1 - np.mean(np.abs(Y_pred - Y_label))
return acc
def _cross_entropy_loss(y_pred, Y_label):
# 此函数计算交叉熵
#
# 参数
# y_pred: 概率预测结果, float vector
# Y_label: 真实标签, bool vector
# Output:
# cross_entropy, 标量
cross_entropy = -np.dot(Y_label, np.log(y_pred)) - np.dot((1 - Y_label), np.log(1 - y_pred))
return cross_entropy
def _gradient(X, Y_label, w, b):
# 此函数计算交叉熵对于w和b的偏导数
y_pred = _f(X, w, b)
pred_error = Y_label - y_pred
#星乘表示矩阵内各对应位置相乘,矩阵a*b下标(0,0)=矩阵a下标(0,0) x 矩阵b下标(0,0)
# 点乘表示求矩阵内积,二维数组称为矩阵积(mastrix product)。
# w_grad = -np.sum(pred_error * X.T, 1)
w_grad = -np.dot(X.T, pred_error) # 这两种写法都可以
b_grad = -np.sum(pred_error)
return w_grad, b_grad
def _plot_curve(train, dev, title, legend, figname):
# 绘图
plt.plot(train)
plt.plot(dev)
plt.title(title)
plt.legend(legend)
plt.savefig('########' + figname)
plt.show()
if __name__ == "__main__":
np.random.seed(0)
X_train_fpath = '#######/X_train'
Y_train_fpath = '#######/Y_train'
X_test_fpath = '#######/X_test'
output_fpath = '#######/output_{}.csv'
# 将csv文件复制入numpy array中
# Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
# 注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
with open(X_train_fpath) as f:
next(f)
X_train = np.array([line.strip('\n').split(',')[1:] for line in f],dtype=float)
with open(Y_train_fpath) as f:
next(f)
Y_train = np.array([line.strip('\n').split(',')[1] for line in f],dtype=float)
with open(X_test_fpath) as f:
next(f)
X_test = np.array([line.strip('\n').split(',')[1:] for line in f],dtype=float)
# 数据标准化
X_train, X_mean, X_std = _normalize(X_train, train=True)
X_test, _, _= _normalize(X_test, train = False, specified_column = None, X_mean = X_mean, X_std = X_std)
# 切分出训练集和验证集
dev_ratio = 0.1
X_train, Y_train, X_dev, Y_dev = _train_dev_split(X_train, Y_train, dev_ratio = dev_ratio)
train_size = X_train.shape[0]
dev_size = X_dev.shape[0]
test_size = X_test.shape[0]
data_dim = X_train.shape[1]
print('Size of training set: {}'.format(train_size))
print('Size of development set: {}'.format(dev_size))
print('Size of testing set: {}'.format(test_size))
print('Dimension of data: {}'.format(data_dim))
# 开始训练
# 使用小批次梯度下降法来训练。训练资料被分为许多小批次,针对每一个小批次,我们分别计算
# 其梯度以及损失,并根据该批次来更新模型的参数。当一次循环完成,也就是整个训练集的所有小批次都被使用过
# 一次以后,将所有训练资料打散并重新分成新的小批次,进行下一个循环。
# 初始化weights和bias
w = np.zeros((data_dim))
b = np.zeros((1,))
# 训练参数
max_iter = 10
batch_size = 8
learning_rate = 0.2
# 记录每次迭代的损失与精确度,用于画图
train_loss = []
dev_loss = []
train_acc = []
dev_acc = []
# 记录参数更新次数
step = 1
# 重复训练
for epoch in range(max_iter):
# 每次循环随机选择训练开始的地方
X_train, Y_train = _shuffle(X_train, Y_train)
# Mini-batch training
for idx in range(int(np.floor(train_size / batch_size))):
X = X_train[idx*batch_size : (idx+1)*batch_size]
Y = Y_train[idx*batch_size : (idx+1)*batch_size]
# 计算梯度
w_grad, b_grad = _gradient(X, Y, w, b)
# 梯度下降更新参数
# 学习率随着迭代次数下降
w = w - learning_rate / np.sqrt(step) * w_grad
b = b - learning_rate / np.sqrt(step) * b_grad
step += 1
# 计算每轮循环训练中,训练集和验证集上的损失和准确度
y_train_pred = _f(X_train, w, b)
Y_train_pred = np.round(y_train_pred)
train_acc.append(_arruracy(Y_train_pred, Y_train))
train_loss.append(_cross_entropy_loss(y_train_pred, Y_train) / train_size)
y_dev_pred = _f(X_dev, w, b)
Y_dev_pred = np.round(y_dev_pred)
dev_acc.append(_arruracy(Y_dev_pred, Y_dev))
dev_loss.append(_cross_entropy_loss(y_dev_pred, Y_dev) / dev_size)
print('Training loss: {}'.format(train_loss[-1]))
print('Development loss: {}'.format(dev_loss[-1]))
print('Training accuracy: {}'.format(train_acc[-1]))
print('Development accuracy: {}'.format(dev_acc[-1]))
# 绘图
# loss curve
_plot_curve(train_loss, dev_loss, 'Loss', ['train', 'dev'], 'loss.png')
# Accuracy curve
_plot_curve(train_acc, dev_acc, 'Accuracy', ['train', 'dev'], 'acc.png')
# 进行预测
predictions = _predict(X_test, w, b)
with open(output_fpath.format('logistic'), 'w') as f:
f.write('id, label\n')
# enumerate多用于在for循环中得到计数,利用它可以同时获得索引和值
for i, label in enumerate(predictions):
f.write('{},{}\n'.format(i, label))
# 显示出最重要的权重
ind = np.argsort(np.abs(w))[::-1]
with open(X_test_fpath) as f:
content = f.readline().strip('\n').split(',')
features = np.array(content)
for i in ind[0:10]:
print(features[i], w[i])
5. 使用生成模型
5.1 建立模型
类1的类内均值为:
类1的类内协方差矩阵为:
类2同理可得
w,b的计算公式为:
数据x属于类1的概率计算公式为:
5.2 完整代码
import numpy as np
def _normalize(X, train = True, specified_column = None, X_mean = None, X_std = None):
# 这个函数用于标准化输入数据的特定列
# 训练数据的平均值与标准差将在处理测试数据时重复使用
#
# 参数Arguments:
# X: 待处理数据
# train: 'True'表示处理训练数据,'False'表示处理测试数据
# specific_column: 需要标准化处理的列索引,如果为'None',则处理所有列
# X_mean: 训练数据的平均值
# X_std: 训练数据的标准差
# 输出Outputs:
# X:标准化后的数据
# X_mean: 计算出的训练数据平均值
# X_std: 计算出的训练数据标准差
if specified_column == None:
specified_column = np.arange(X.shape[1]) # 计算列数
if train:
# 计算每列的平均之后变为一行
X_mean = np.mean(X[:, specified_column], 0).reshape(1, -1)
# 计算每列的标准差后变为一行
X_std = np.std(X[:,specified_column], 0).reshape(1, -1)
X[:, specified_column] = (X[:, specified_column] - X_mean)/(X_std + 1e-8)
return X, X_mean, X_std
def _sigmoid(z):
# 用于预测的sigmoid函数
# 限制输出值的范围为1e-8, 1-(1e-8)
return np.clip(1 / (1.0 + np.exp(-z)), 1e-8, 1 - (1e-8))
def _f(X, w, b):
# 这是一个逻辑回归函数
#
# 参数
# X: 输入数据, shape = [batch_size, data_dimension]
# w: weight vector, shape = [data_dimension, ]
# b: 偏置 bias, scalar
# 输出
# 预测X的每行被预测为1的概率,shape = [batch_size, ]
return _sigmoid(np.matmul(X, w) + b) # 两个numpy数组的矩阵相乘
def _predict(X, w, b):
# 根据逻辑回归结果预测分类
# 实际利用了round函数的四舍五入,将结果输出为0, 1
return np.round(_f(X, w, b)).astype(np.int)
def _arruracy(Y_pred, Y_label):
# 计算预测准确度
acc = 1 - np.mean(np.abs(Y_pred - Y_label))
return acc
if __name__ == "__main__":
np.random.seed(0)
X_train_fpath = '########/X_train'
Y_train_fpath = '########/Y_train'
X_test_fpath = '########/X_test'
output_fpath = '########/output_{}.csv'
# 训练集和测试集的处理方法和logistic回归相同
# 因为generative model有可解出的最佳解,因此不需要切分出验证集
with open(X_train_fpath) as f:
next(f)
X_train = np.array([line.strip('\n').split(',')[1:] for line in f],dtype=float)
with open(Y_train_fpath) as f:
next(f)
Y_train = np.array([line.strip('\n').split(',')[1] for line in f],dtype=float)
with open(X_test_fpath) as f:
next(f)
X_test = np.array([line.strip('\n').split(',')[1:] for line in f],dtype=float)
# 数据标准化
X_train, X_mean, X_std = _normalize(X_train, train=True)
X_test, _, _= _normalize(X_test, train = False, specified_column = None, X_mean = X_mean, X_std = X_std)
# 计算类内平均值
# 认为第一类为超过五万美元(取值为1),第二类为未超过五万美元(取值为0)
X_train_0 = np.array([x for x, y in zip(X_train, Y_train) if y == 1])
X_train_1 = np.array([x for x, y in zip(X_train, Y_train) if y == 0])
mean_0 = np.mean(X_train_0, axis = 0)
mean_1 = np.mean(X_train_1, axis = 0)
data_dim = 510
# 计算类内协方差
cov_0 = np.zeros((data_dim, data_dim))
cov_1 = np.zeros((data_dim, data_dim))
for x in X_train_0:
cov_0 += np.dot(np.transpose([x - mean_0]), [x - mean_0]) / X_train_0.shape[0]
for x in X_train_1:
cov_1 += np.dot(np.transpose([x - mean_1]), [x - mean_1]) / X_train_1.shape[0]
# 假设两类对应的分布共用一个协方差矩阵
cov = (cov_0 * X_train_0.shape[0] + cov_1 * X_train_1.shape[0]) / X_train.shape[0]
# 权重矩阵与偏差向量可以直接计算出来
# 需要计算协方差矩阵的逆矩阵
# 因为协方差矩阵可能几乎是奇异的,np.linalg.inv()会产生一个大的数值误差
# 通过奇异值分解,可以高效、准确地求出矩阵的逆。
u, s, v = np.linalg.svd(cov, full_matrices=False)
inv = np.matmul(v.T * 1 / s, u.T)
w = np.dot(inv ,mean_0 - mean_1)
b = (-0.5) * np.dot(mean_0, np.dot(inv, mean_0)) + (0.5) * np.dot(mean_1, np.dot(inv, mean_1)) + np.log(float(X_train_0.shape[0]) / X_train_1.shape[0])
# 计算训练集上的准确性
# 仍然用sigmoid函数分类
Y_train_pred = _predict(X_train, w, b)
print('训练准确率: {}'.format(_arruracy(Y_train_pred, Y_train)))
# 进行预测
predictions = _predict(X_test, w, b)
with open(output_fpath.format('generative'), 'w') as f:
f.write('id,label\n')
for i, label in enumerate(predictions):
f.write('{},{}\n'.format(i, label))
# 显示出最重要的权重项
ind = np.argsort(np.abs(w))[::-1]
with open(X_test_fpath) as f:
content = f.readline().strip('\n').split(',')
features = np.array(content)
for i in ind[0:10]:
print(features[i], w[i])