SIFT特征提取与检索及地理标记图像匹配
SIFT特征提取与检索
1、SIFT简介
1.1、简介
匹配的核心问题是将同一目标在不同时间、不同分辨率、不同光照、不同方向的情况下所成的像对应起来。传统的匹配算法往往是直接提取角点或边缘,对环境的适应能力较差,需要一种鲁棒性强,能够适应不同情况的有效的目标识别的方法。
SIFT由David Lowe在1999年提出,在2004年加以完善 。SIFT在数字图像的特征描述方面当之无愧可称之为最红最火的一种,许多人对SIFT进行了改进,诞生了SIFT的一系列变种。SIFT已经申请了专利。
1.2、SIFT算法的特点
1、图像的局部特征,对旋转、尺度缩放、亮度变化保持不变,对视角变化、仿射变换、噪声也保持一定程度的稳定性。
2、独特性好,信息量丰富,适用于海量特征库进行快速、准确的匹配。
3、多量性,即使是很少几个物体也可以产生大量的SIFT特征
4、高速性,经优化的SIFT匹配算法甚至可以达到实时性
5、扩招性,可以很方便的与其他的特征向量进行联合。
1.3、SIFT算法可以解决的问题
目标的自身状态、场景所处的环境和成像器材的成像特性等因素影响图像配准/目标识别跟踪的性能,SIFT算法在一定程度上可以解决:
1、目标的旋转、缩放、平移
2、图像仿射/投影变换
3、光照影响
4、目标遮挡
5、杂物场景
6、噪声
2、实现步骤
1、**尺度空间的极值检测:**搜索所有尺度空间上的图像,通过高斯微分函数来识别潜在的对尺度和旋转不变的兴趣点。
2、**特征点定位:**在每个候选的位置上,通过一个拟合精细模型来确定位置尺度,关键点的选取依据他们的稳定程度。
3、特征方向赋值: 基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向,后续的所有操作都是对于关键点的方向、尺度和位置进行变换,从而提供这些特征的不变性。
4、特征点描述: 在每个特征点周围的邻域内,在选定的尺度上测量图像的局部梯度,这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变换。
3、实验内容
3.1、拍摄多张图片(注意要来自不同场景)构造出一个小的数据集
拍摄了3个小区的不同场景的照片,每个小区各5张,共15张作为数据集
3.2、SIFT单张图片特征提取
出现的问题
1、检测点太多 整个屏幕都是特征点
2、运行速度极慢,5-10分钟才跑完一次代码

这里以一张图作为例子
可以看出SIFI特征点与Harris角点进行比较,SIFT特征点明显多于Harris角点,但是SIFT运行时间明显长于上个实验中Harris角点检测的运行时间。
解决方法
待解决
3.3、SIFT进行两张图像匹配
分为三种情况进行实验
1、同一小区同一场景不同角度匹配
2、同一小区相似场景匹配
3、不同小区场景匹配
3.3.1、同一小区同一场景不同角度匹配

分析
图片是在天台拍摄的,第二张图片是在第一张图片左侧拍摄的,可以看到第一张图片右侧的建筑物在第二张图片有了全貌。两张图片正中央的建筑物是比较全面且清晰的,匹配结果可以看出,匹配精准,且匹配点多。
3.3.2、同一小区相似场景匹配

分析
在同一个小区,建筑风格相似,所以选取这两张图片进行匹配。虽然建筑风格相同,但是角度不同,所以匹配结果可以看出匹配不精准,唯一一个匹配点是不同的两个建筑的窗户。
3.3.3、不同小区场景匹配

分析
在不同小区的不同场景下,无匹配点
3.4 SIFT数据集匹配图片
输入:一张数据集外的图片

输出:在数据集中匹配度最高的3张图片

出现的问题
![]()
输入的图片损坏,更换图片解决
结果分析
先将输入的图片读入,再用一个循环将整个文件夹中的文件遍历,与输入图片进行匹配,存储匹配值,输出最高的三张图片。依旧选择这个建筑风格比较相似的小区的图片进行输入,匹配点较少,但是比较准确,都是建筑物顶端的灰色尖端。运行时间较长。
4、地理标记图像匹配
4.1实验需求
1、通过图像间是否具有匹配的局部描述子
2、如果匹配数高于一定值,连接图片
3、可视化图片的连接情况,输出一张结果图为了完成可视化(使用pydot)
4.2实验代码
# -*- coding: utf-8 -*-
from pylab import *
from PIL import Image
from PCV.localdescriptors import sift
from PCV.tools import imtools
import pydot
import os
os.environ['PATH'] = os.environ['PATH'] + (';c:\\Program Files (x86)\\Graphviz2.38\\bin\\')
""" This is the example graph illustration of matching images from Figure 2-10.
To download the images, see ch2_download_panoramio.py."""
#download_path = "panoimages" # set this to the path where you downloaded the panoramio images
#path = "/FULLPATH/panoimages/" # path to save thumbnails (pydot needs the full system path)
download_path = "C:/Users/Administrator/Desktop/pythonhomework/sift1" # set this to the path where you downloaded the panoramio images
path = "C:/Users/Administrator/Desktop/pythonhomework/sift1/" # path to save thumbnails (pydot needs the full system path)
# list of downloaded filenames
imlist = imtools.get_imlist(download_path)
nbr_images = len(imlist)
# extract features
featlist = [imname[:-3] + 'sift' for imname in imlist]
for i, imname in enumerate(imlist):
sift.process_image(imname, featlist[i])
matchscores = zeros((nbr_images, nbr_images))
for i in range(nbr_images):
for j in range(i, nbr_images): # only compute upper triangle
print 'comparing ', imlist[i], imlist[j]
l1, d1 = sift.read_features_from_file(featlist[i])
l2, d2 = sift.read_features_from_file(featlist[j])
matches = sift.match_twosided(d1, d2)
nbr_matches = sum(matches > 0)
print 'number of matches = ', nbr_matches
matchscores[i, j] = nbr_matches
print "The match scores is: \n", matchscores
# copy values
for i in range(nbr_images):
for j in range(i + 1, nbr_images): # no need to copy diagonal
matchscores[j, i] = matchscores[i, j]
#可视化
threshold = 2 # min number of matches needed to create link
g = pydot.Dot(graph_type='graph') # don't want the default directed graph
for i in range(nbr_images):
for j in range(i + 1, nbr_images):
if matchscores[i, j] > threshold:
# first image in pair
im = Image.open(imlist[i])
im.thumbnail((100, 100))
filename = path + str(i) + '.png'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(i), fontcolor='transparent', shape='rectangle', image=filename))
# second image in pair
im = Image.open(imlist[j])
im.thumbnail((100, 100))
filename = path + str(j) + '.png'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(j), fontcolor='transparent', shape='rectangle', image=filename))
g.add_edge(pydot.Edge(str(i), str(j)))
g.write_png('whitehouse.png')
4.3 实验过程及分析
4.3.1出现的问题
问题一:not found dot
图中的问题是找不到pydot
解决方法
安装pydot和Graphviz
一定要先安装Graphviz再安装pydot,要不然仍旧会报错
问题二:匹配时间过长

在运行过程中,在匹配第一张图的时候就执行了10分钟以上仍旧没有继续下一个匹配
解决方法
分析:运行时间过程很大可能是图的匹配点过多导致的
方法:将原图进行缩放,减少特征点
from PIL import Image
from pylab import *
pil_im=Image.open("C:/Users/Administrator/Desktop/pythonhomework/sift/15.jpg")
pil_im.thumbnail((200,200))
pil_im.save('C:/Users/Administrator/Desktop/pythonhomework/sift1/15.jpg') #保存缩略图
###### 问题
4.3.2 实验结果
1、特征点


2、匹配

3、生成可视化连线图

4.3.3 实验分析
在第一次执行代码的时候,匹配时间过长让我误以为是图片出现问题,因此我选择了更换另外一组图片(只含有简单的物体)但是最后输出结果要不就是空白(无匹配)要不就是只有一两张图片(个别匹配),经过询问同学,他们采用了将图片缩放的方式,减少特征点。在上一实验中,运行时间过长很有可能是因为特征点太多导致的。经过将图片缩放,运行速度明显增快,并且运行结果的效果也相当不错,匹配基本正确,15张图匹配了11张。匹配次数为(n*(n-1)/2)次,本实验采用数据集中图片为15张,因此匹配次数最多为105。
5、RANSAC算法剔除错配
5.1、RANSAC概述
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
1.有一个模型适应于假设的局内点,即所有的未知参数都能从假设的局内点计算得出。
2.用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
3.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
4.然后,用所有假设的局内点去重新估计模型,因为它仅仅被初始的假设局内点估计过。
5.最后,通过估计局内点与模型的错误率来评估模型。
这个过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为比现有的模型更好而被选用。
5.2、RANSAC算法原理
RANSAC通过反复选择数据中的一组随机子集,来达成目标。在OpenCV中滤除误匹配对,采用RANSAC算法寻找一个最佳单应性矩阵H,矩阵大小为3×3。RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h3×3=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。
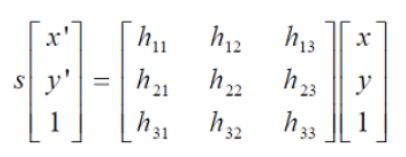
5.3、实验内容
1、针对输入图片,针对SIFT特征匹配的结果(没有RANSAC,以及经过RANSAC)进行分析,重点分析删除掉的错配,以及是否有正确匹配特征也同步被删除掉
2. 实验场景分成两种类型,一是图片景深单一。而是图片中景深丰富,平面复杂
5.3.1、实验代码
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import random
def compute_fundamental(x1, x2):
n = x1.shape[1]
if x2.shape[1] != n:
raise ValueError("Number of points don't match.")
# build matrix for equations
A = np.zeros((n, 9))
for i in range(n):
A[i] = [x1[0, i] * x2[0, i], x1[0, i] * x2[1, i], x1[0, i] * x2[2, i],
x1[1, i] * x2[0, i], x1[1, i] * x2[1, i], x1[1, i] * x2[2, i],
x1[2, i] * x2[0, i], x1[2, i] * x2[1, i], x1[2, i] * x2[2, i]]
# compute linear least square solution
U, S, V = np.linalg.svd(A)
F = V[-1].reshape(3, 3)
# constrain F
# make rank 2 by zeroing out last singular value
U, S, V = np.linalg.svd(F)
S[2] = 0
F = np.dot(U, np.dot(np.diag(S), V))
return F / F[2, 2]
def compute_fundamental_normalized(x1, x2):
""" Computes the fundamental matrix from corresponding points
(x1,x2 3*n arrays) using the normalized 8 point algorithm. """
n = x1.shape[1]
if x2.shape[1] != n:
raise ValueError("Number of points don't match.")
# normalize image coordinates
x1 = x1 / x1[2]
mean_1 = np.mean(x1[:2], axis=1)
S1 = np.sqrt(2) / np.std(x1[:2])
T1 = np.array([[S1, 0, -S1 * mean_1[0]], [0, S1, -S1 * mean_1[1]], [0, 0, 1]])
x1 = np.dot(T1, x1)
x2 = x2 / x2[2]
mean_2 = np.mean(x2[:2], axis=1)
S2 = np.sqrt(2) / np.std(x2[:2])
T2 = np.array([[S2, 0, -S2 * mean_2[0]], [0, S2, -S2 * mean_2[1]], [0, 0, 1]])
x2 = np.dot(T2, x2)
# compute F with the normalized coordinates
F = compute_fundamental(x1, x2)
# print (F)
# reverse normalization
F = np.dot(T1.T, np.dot(F, T2))
return F / F[2, 2]
def randSeed(good, num = 8):
'''
:param good: 初始的匹配点对
:param num: 选择随机选取的点对数量
:return: 8个点对list
'''
eight_point = random.sample(good, num)
return eight_point
def PointCoordinates(eight_points, keypoints1, keypoints2):
'''
:param eight_points: 随机八点
:param keypoints1: 点坐标
:param keypoints2: 点坐标
:return:8个点
'''
x1 = []
x2 = []
tuple_dim = (1.,)
for i in eight_points:
tuple_x1 = keypoints1[i[0].queryIdx].pt + tuple_dim
tuple_x2 = keypoints2[i[0].trainIdx].pt + tuple_dim
x1.append(tuple_x1)
x2.append(tuple_x2)
return np.array(x1, dtype=float), np.array(x2, dtype=float)
def ransac(good, keypoints1, keypoints2, confidence,iter_num):
Max_num = 0
good_F = np.zeros([3,3])
inlier_points = []
for i in range(iter_num):
eight_points = randSeed(good)
x1,x2 = PointCoordinates(eight_points, keypoints1, keypoints2)
F = compute_fundamental_normalized(x1.T, x2.T)
num, ransac_good = inlier(F, good, keypoints1, keypoints2, confidence)
if num > Max_num:
Max_num = num
good_F = F
inlier_points = ransac_good
print(Max_num, good_F)
return Max_num, good_F, inlier_points
def computeReprojError(x1, x2, F):
"""
计算投影误差
"""
ww = 1.0/(F[2,0]*x1[0]+F[2,1]*x1[1]+F[2,2])
dx = (F[0,0]*x1[0]+F[0,1]*x1[1]+F[0,2])*ww - x2[0]
dy = (F[1,0]*x1[0]+F[1,1]*x1[1]+F[1,2])*ww - x2[1]
return dx*dx + dy*dy
def inlier(F,good, keypoints1,keypoints2,confidence):
num = 0
ransac_good = []
x1, x2 = PointCoordinates(good, keypoints1, keypoints2)
for i in range(len(x2)):
line = F.dot(x1[i].T)
#在对极几何中极线表达式为[A B C],Ax+By+C=0, 方向向量可以表示为[-B,A]
line_v = np.array([-line[1], line[0]])
err = h = np.linalg.norm(np.cross(x2[i,:2], line_v)/np.linalg.norm(line_v))
# err = computeReprojError(x1[i], x2[i], F)
if abs(err) < confidence:
ransac_good.append(good[i])
num += 1
return num, ransac_good
if __name__ =='__main__':
im1 = '../sift1/12.jpg'
im2 = '../sift1/14.jpg'
print(cv2.__version__)
psd_img_1 = cv2.imread(im1, cv2.IMREAD_COLOR)
psd_img_2 = cv2.imread(im2, cv2.IMREAD_COLOR)
# 3) SIFT特征计算
sift = cv2.xfeatures2d.SIFT_create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(psd_img_1, None)
kp2, des2 = sift.detectAndCompute(psd_img_2, None)
# FLANN 参数设计
match = cv2.BFMatcher()
matches = match.knnMatch(des1, des2, k=2)
# Apply ratio test
# 比值测试,首先获取与 A距离最近的点 B (最近)和 C (次近),
# 只有当 B/C 小于阀值时(0.75)才被认为是匹配,
# 因为假设匹配是一一对应的,真正的匹配的理想距离为0
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
print(good[0][0])
print("number of feature points:",len(kp1), len(kp2))
print(type(kp1[good[0][0].queryIdx].pt))
print("good match num:{} good match points:".format(len(good)))
for i in good:
print(i[0].queryIdx, i[0].trainIdx)
Max_num, good_F, inlier_points = ransac(good, kp1, kp2, confidence=30, iter_num=500)
# cv2.drawMatchesKnn expects list of lists as matches.
# img3 = np.ndarray([2, 2])
# img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good[:10], img3, flags=2)
# cv2.drawMatchesKnn expects list of lists as matches.
img3 = cv2.drawMatchesKnn(psd_img_1,kp1,psd_img_2,kp2,good,None,flags=2)
img4 = cv2.drawMatchesKnn(psd_img_1,kp1,psd_img_2,kp2,inlier_points,None,flags=2)
cv2.namedWindow('image1', cv2.WINDOW_NORMAL)
cv2.namedWindow('image2', cv2.WINDOW_NORMAL)
cv2.imshow("image1",img3)
cv2.imshow("image2",img4)
cv2.waitKey(0)#等待按键按下
cv2.destroyAllWindows()#清除所有窗口
5.3.2 实验结果及分析
ransac前

ransac后

分析:

可以看到图中箭头所指的黄色线和橙色线的匹配明显是错配,在经过 ransac算法后,错配被删除。图片中大楼的窗户多而且极其相似,非常容易出现错配的情况,但是可以看到在ransac算法过后,明显的匹配错误都被剔除了。由于图片出现匹配点多而繁杂,有些剔除不容易观察出来,但是在总体上可以看到中间交错的匹配先相对少了一些。
5.3.3出现的问题
问题1:No module named cv2
原因:没有安装opencv
解决方法:因为在之前将python xy更换成了anaconda,所以opencv没有安装,命令行中输入pip install opencv-python进行安装
问题2:在安装opencv后出现报错:AttributeError: ‘module’ object has no attribute ‘xfeatures2d’
原因:安装的opencv为4.x版本,有些功能在4.x版本被删除了,需要安装3.x版本。
解决方法:卸载原版本,安装旧版本
6、总结
1、在简介中介绍了SIFT有着高速性,但是在我运行过程中,相比上个实验harris角点检测,运行速度极慢,5分钟才有输出结果。询问老师和同学,问题可能在照片的选取上,数据集中很多图片含有大量的树叶,所以SIFT才会大量的选取特征点。
2、多量性有着很好的体现,可以明显看出特征点远远大于harris角点。
3、匹配较为准确,在相同场景不同角度下的图片有着大量而且准确的匹配。
补充1:运行时间过长原因是图片像素高,特征点的数量多,导致运行速度非常慢。并且实验结果证明,并不是特征点越多,最后的匹配结果就越好。如果像素过高,可以将图片缩放,能有效的减少特征点,加快运行速度。