Python爬取微博热搜数据之炫酷可视化
可视化展示
看完记得点个赞哟
微博炫酷可视化音乐组合版来了!
项目介绍
背景
现阶段,微博、抖音、快手、哗哩哗哩、微信公众号已经成为不少年轻人必备的“生活神器”。在21世纪的今天,你又是如何获取外界的信息资源的?相信很多小伙伴应该属于下面这一种类型的:
事情要想知道快,抖音平台马上拍;
微博热搜刷一刷,聚焦热点不愁卖;
闲来发呆怎么办, B 站抖音快手来;
要是深夜无聊备,微信文章踩一踩;
哈哈哈,小小的活跃一下气氛
在这个万物互联的时代,已不再是那个“从前慢,车马慢......”的飞鸽传书三月天的时代了,数据每一天都有人在产生,也有人时刻在收集和监控数据,更是有人不断地在分析和利用数据产生潜在的价值。
项目概览
本次项目选取的是微博热搜数据,爬取加数据分析和可视化展示,基于微博热搜的娱乐项目。
本次数据是选取之前的,并不是最新的微博数据,当然可以自己去运行代码就可以爬取最新的数据了!
微博热搜数据爬取
部分代码展示
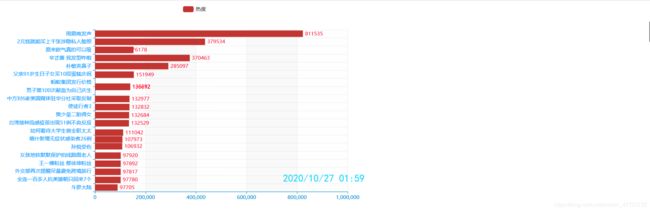
微博热度动态轮播图
部分代码展示
源码点击此处下载
微博话题定位追踪可视化
部分源码展示
源码点击此处下载
爬取微博热搜文章评论词云分析
部分源码展示
点击此处下载源码
近期微博热搜话题词云展示
点击此处下载源码
其他项目点击此处
项目代码展示
微博热搜数据爬取
选取微博热搜榜官网,网址如下:
https://s.weibo.com/top/summary?cate=realtimehot&sudaref=s.weibo.com&display=0&retcode=6102

1.通过简单对网页的解析与观察我们可以定位我们所需要的数据标签值,决定我们应该用什么解析库,可以用Xpath、正则表达式、beautifulsoup都可以实现功能,本次选取的是beautifulsoup进行对数据表的解析。
2.同时我们需要注意的是微博反爬的措施,我们需要加入自己的请求头,我们借用一个第三方库,它可以随机产生一个可用的请求头来伪装我们的软件,模拟浏览器进行数据抓取:from fake_useragent import UserAgent
3.微博热搜是每一分钟更新一次,我们需要用到定时爬取的模块,每一分钟爬取需要的数据:import schedule
4.每一分钟爬取一次,一个小时爬取60种类数据,建议爬取开启5-7小时,让电脑自动抓取数据,那么就需要用到延时模块了:import time
5.微博抓取的数据有排名、热搜标题、热度,为了我们方便展示和数据分析,我们需要给它加上时间戳,自动获取当前时间,引进:from datetime import datetime
6.数据爬取好之后我们需要存储,我们采用pandas这个强大的数据分析库,进行数据的存储:import pandas as pd
部分代码展示
from fake_useragent import UserAgent
import schedule
import pandas as pd
from datetime import datetime
import requests
from bs4 import BeautifulSoup
import time
ua = UserAgent() # 解决了我们平时自己设置伪装头的繁琐,此库自动为我们弹出一个可用的模拟浏览器
url = "https://s.weibo.com/top/summary?cate=realtimehot&sudaref=s.weibo.com&display=0&retcode=6102"
headers = {"User-Agent": ua.random}
get_info_dict = {} # 创建一个数据字典
count = 0
a = 1
def main():
global url, get_info_dict, count, a
get_info_list = []
html = requests.get(url, headers).text # 返回网页源码为txt文本
# 定时爬虫
schedule.every(1).minutes.do(main) # 根据微博每隔一分钟更新一次数据,我们就每隔一分钟爬取数据
while True:
time.sleep(2)
schedule.run_pending() # 执行可执行结构
微博热度动态轮播图
可视化基于pyecharts这个强大的库,适合做这种比较炫酷的可视化展示,轮播图是如何去实现数据迭代展示的,我们一共爬取了多少次就会有多少次迭代循环,第一次提取出数据进行可视化,第二次继续提取,如果第二次的数据与第一次的数据不一样那么动态效果也就自然显示出来了,这样不断的去展示效果,再去设置一些参数:比如播放的帧数时间间隔等,那种动态的效果就会出来了。
部分代码展示
df = pd.read_csv('夜间微博.csv', encoding='gbk')#解码,注意这里不能使用utf-8,因为CSV文件使用gbk编码
t = Timeline({"theme": ThemeType.MACARONS}) # 定制主题——动态直方图
for i in range(389):#这里的参数设置为我们总共了爬取的多少次更新动态数据
bar = (
Bar()
.add_xaxis(list(df['关键词'][i*20: i*20+20][::-1])) # x轴数据
.add_yaxis('热度', list(df['热度'][i*20: i*20+20][::-1])) # y轴数据
.reversal_axis() # 翻转
.set_global_opts( # 全局配置项
title_opts=opts.TitleOpts( # 标题配置项
title=f"{list(df['时间'])[i*20]}",
pos_right="5%", pos_bottom="15%",
title_textstyle_opts=opts.TextStyleOpts(
font_family='KaiTi', font_size=24, color='#14d8ff'#颜色配置去:https://encycolorpedia.cn/ff1493查询设置
)
),
xaxis_opts=opts.AxisOpts( # x轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),#降序排序,从大到小,默认为升序
),
yaxis_opts=opts.AxisOpts( # y轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(color='#149bff')
)
)
.set_series_opts( # 系列配置项
label_opts=opts.LabelOpts( # 标签配置
position="right", color='#ff1435')源码点击此处下载
微博话题定位追踪可视化
对爬取的数据知识简单的轮播图展示热度,显得有点单调了,选取自己喜欢的话题去追踪定位它在这一个时间段里面的热度趋势,采用pyecharts这个动态折线图的展示效果,再结合Python原生态的算法添加数据,两者结合在一起如虎添翼。

部分源码展示
c = (
Line(init_opts=opts.InitOpts(width="1400px", height="600px")) # 画布大小
.add_xaxis(x_data) # 添加x轴
.add_yaxis('周震南发声', y_1data, is_symbol_show=False, color=['red']) # 添加第一个y轴
.add_yaxis('男子第100次献血为自己庆生', y_2data, is_symbol_show=False, color=['blue'])
.add_yaxis('全明星1111起挺你', y_3data, is_symbol_show=False, color=['purple'])
.add_yaxis('辛芷蕾 我发型咋啦', y_4data, is_symbol_show=False, color=['green'])
.set_global_opts(
title_opts=opts.TitleOpts(title='微博热度走势图', subtitle="2020/10/27-凌晨1点热搜追踪图"),
# 设置x轴的label字体的走向,由于x轴过多,显示不全,在这调整旋转角度
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=90)),
# 下面这是调整是否可以缩放的
datazoom_opts=opts.DataZoomOpts(is_show=True),
)
)with open(r"热度跟踪图.txt", 'w', encoding="utf-8") as fi:
for q in ll:
fi.write('"' + q + '"' + ",")
print("恒定时间写入成功!!")
fi.write('\n热搜标题1:{}\n'.format(a))
for w in ls:
fi.write(w + ",")
print("追踪热度1号写入成功!!")
fi.write('\n热搜标题2:{}\n'.format(b))
for w in lk:
fi.write(w + ",")
print("追踪热度2号写入成功!!")
fi.write('\n热搜标题3:{}\n'.format(c))
for w in lf:
fi.write(w + ",")
print("追踪热度3号写入成功!!")
fi.write('\n热搜标题4:{}\n'.format(d))
for w in le:
fi.write(w + ",")
print("追踪热度4号写入成功!!")源码点击此处下载
爬取微博热搜文章评论词云分析
结合抓包工具和浏览器的模拟点击,爬取微博文章评论,利用这个自动输出展示词云,让我们快速理解关于该话题文章的热搜趋势和热点,来看看周震南事件到底是什么东东

部分源码展示
import requests
import json
import pprint
import re
def get_comments(url):
headers={
"cookie":"WEIBOCN_FROM=1110006030; SUB=_2A25ykBYoDeRhGeNL6VQX9SzOzz-IHXVuerpgrDV6PUJbkdANLVnxkW1NSP633HCwOYWsoKRdojJu08k0-l9OKPoi; SUHB=09P9SVp1GiU0Dz; _T_WM=46932887560; XSRF-TOKEN=f40f69; MLOGIN=1; M_WEIBOCN_PARAMS=uicode%3D20000061%26fid%3D4563689719990147%26oid%3D4563689719990147",
"Accept":"application/json, text/plain, */*",
"MWeibo-Pwa":"1",
"Referer":"https://m.weibo.cn/detail/4563874994983986",
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Mobile Safari/537.36",
"X-Requested-With":"XMLHttpRequest",
"X-XSRF-TOKEN":"50171a"
}
res=requests.get(url,headers=headers)
ids=re.findall('u524d","id":"(.*?)",',res.text)
file=open("评论.txt", "w", encoding='utf-8')
for id in ids:
s_url="https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0".format(id,id)
print(s_url)
sing_res = requests.get(url=s_url, headers=headers)
sing_data = json.loads(sing_res.text)
users = sing_data['data']['data']
age_urls = re.findall('"profile_url":"(.*?)",', res.text)with open(r"评论.txt",encoding="utf-8") as file:
a=file.read()
b=jieba.lcut(a)
for x in b:
if x in ",。、;:‘’“”【】《》?、.!…\n":
continue
else:
if len(x) == 1:
ll.append(x)
elif len(x) == 2:
lg.append(x)
elif len(x) == 3:
lk.append(x)
elif len(x)== 4:
lj.append(x)
# lp.append(x)
for i in lg:
lp.append(i)
for p in lk:
lp.append(p)
for f in lj:
lp.append(f)
点击此处下载源码
近期微博热搜话题词云展示
爬取近期一个月的微博热搜话题,看看大家最近都在聚焦什么,不多说了,这里涉及到的一些参数,首先请求头,cookies,能加的都加,我们只需要获取文字标题,可以通过Xpath来解决,源码里面是利用beautifulsoup这个一样的道理,最后输出为一个文本格式即可,抓包工具还是比较好的,一些看不到的数据我们可以通过这个神器来解决,自然动态加载还是Ajax都不是问题了。


点击此处下载源码
其他项目点击此处
基于pyecharts可视化展示,动态可视化效果,后期在专栏《数据可视化之美》里面详细介绍pyecharts的用法和展示案例
每文一语
微 言细词览无余
博 文入目皆可析
数 秒分取千万条
据 重方解图表均