李宏毅DLHLP.10.Voice Conversion.2/2. CycleGAN and starGAN
文章目录
- 介绍
- 2nd Stage Training
- Direct Transformation
-
- Cycle GAN
- starGAN
- Reference
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站
B站视频
公式输入请参考:在线Latex公式
接上节的话题,我们用AE的思想来将content和speaker的特征分开,然后再拼回去,然后再Decoder回原来输入的声音,希望输入和输出的reconstruction error最小。

但是这样训练有一个问题,整个训练过程都是用的同一个语者,模型只会顾着学习分开content和speaker的特征了,完全没考虑语音转化这个事情。在测试的时候:

我们给模型吃的内容和语者是模型没有见过的,因此,得到结果不会很好。
先给第一个解决方案:
2nd Stage Training
为了让模型知道咱们是在做VC这个事情,我们给content encoder的内容和语者的信息都是不同人的

但是这样一样我们就会没有ground truth了,例如:内容是【:富强、民主、文明、和谐】,说话人选川普,那哪里有ground truth作为learning target?那么Decoder输出就没有目标,也就没有办法train。
那么可以加一个discriminator,用来帮助Decoder生成语音接近真实声音。

还可以加入一个speaker classifier,用来使得Decoder生成的使用要接近我们的VC的目标:A的声音。

这么个复杂的模型很容易坏掉。有一个trick就是加一个patcher模块。将patcher获得的结果补充到decoder的结果上会得到比较好的结果。

到这个地方,上节课讲的VC的Unparallel Data常用两种方法,一种是Feature Disentangle,到这里就讲完,下面是另外一种方法:Direct Transformation
Direct Transformation
思想就是直接输入语音,输出转换好的语音。方法就是借鉴图像处理中的CycleGAN

Cycle GAN
先收集两个语者的声音:

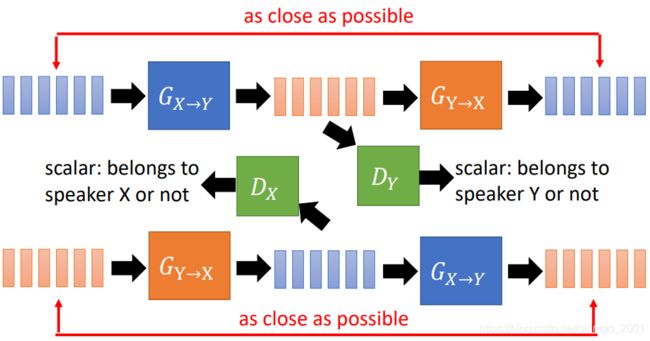
先训练一个Generator,它可以将X的声音转换为Y的声音

这个训练没有groud truth,所以加入discriminator帮助generator生成的声音越接近Y越好。我们为discriminator提供很多Y的声音,这样discriminator就可以鉴别generator生成的声音是否和Y相似。generator的目标就是要骗过discriminator。

但是这样的模型估计训练到后面就会无视X的声音,只管输出Y的最常说的话就了事,这样明显不是我们想要的。这个时候就要用到Cycle GAN,再加一个Generator,使得第一个Generator输出的声音能够转换回原来的X的声音。由于我们将声音用的vector表示,合起来就是矩阵,要使得两个矩阵相似,就是要算L1或L2弄。

这里训练蓝色的第一个Generator还有一个小trick,如图所示,在训练的过程中加入Y的声音,Generator还是要输出Y的声音,这样有利于训练的稳定。
弄明白上面蓝色、橙色,绿色模块后,我们就可以加入Cycle了,稍微解释一下上面的橙色输出为X之后,加入另外一个discriminator: D X D_X DX帮助橙色的Generator生成X的声音越像越好。
还有一个方法是starGAN
starGAN
上面的方法虽然可以行得通,但是只适用于2个或者很少的语者的情况,因为,当有N个语者的时候,我们需要 N ( N − 1 ) N(N-1) N(N−1)个Generator,因此要用starGAN,相当于CycleGAN的加强版。
要CycleGAN的Generator改一下,之前的CycleGAN的Generator只能吃X的声音,吐Y的声音(反正只能吃某一个,吐另外一个人的声音),改进后Generator变强了,吃某个人的声音,可以吐出任意一个人的声音信号,这个事情这样做:先有一个输的声音的语者: s i s_i si,在给出要转的目标语者 s j s_j sj,最后得到 s j s_j sj的声音:

s j s_j sj可以有很多种表示方式,例如:独热编码。
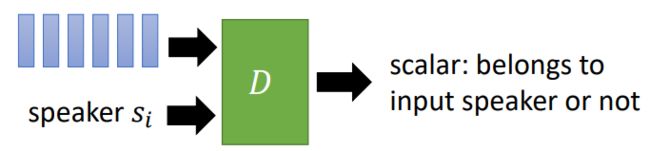
对于Discriminator而言,也有改进,之前的CycleGAN的Discriminator只能判断语音信号属于某一个特定的人,这里改进后Discriminator可以根据 s j s_j sj判断输入的语音信息是否属于 s j s_j sj。
知道了这些后,我们就可以看starGAN的结构:
其中 k ≠ i k\neq i k=i两个语者都是sample出来的。

The classifier is ignored here.要看原文,或者参考上面的CycleGAN的原理图。
还有一个更加进阶的方法叫Blow 具体没展开,之前有讲
Ref for flow-based model: https://youtu.be/uXY18nzdSsM
Reference
• [Huang, et al., arXiv’19] Wen-Chin Huang,Tomoki Hayashi,Yi-Chiao Wu,Hirokazu Kameoka,Tomoki Toda, Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining, arXiv, 2019
• [Biadsy, et al., INTERSPEECH’19] Fadi Biadsy, Ron J. Weiss, Pedro J. Moreno, Dimitri Kanevsky, Ye Jia, Parrotron: An End-to-End Speech-to-Speech Conversion Model and its Applications to Hearing-Impaired Speech and Speech Separation, INTERSPEECH, 2019
• [Nachmani, et al., INTERSPEECH’19] Eliya Nachmani, Lior Wolf, Unsupervised Singing Voice Conversion, INTERSPEECH, 2019
• [Seshadri, et al., ICASSP’19] Shreyas Seshadri, Lauri Juvela, Junichi Yamagishi, Okko Räsänen, Paavo Alku,Cycle-consistent Adversarial Networks for Non-parallel Vocal Effort Based Speaking Style Conversion, ICASSP, 2019