树专题
树专题
- 一个中心
- 两个基本点
-
- 深度优先遍历
- 广度优先遍历
- 三种题型
-
- 搜索类
-
- Offer 34.** **二叉树中和为某一值的路径
- 1372. 二叉树中的最长交错路径
- 构建类
-
- 普通二叉树的构建
- 二叉搜索树的构建
- 修改类
-
- 增加,删除节点,或者是修改节点的值或者指向。
- 四个重要概念
-
- 二叉搜索树
- 完全二叉树
- 路径
-
- 124.二叉树中的最大路径和
- 距离
一个中心
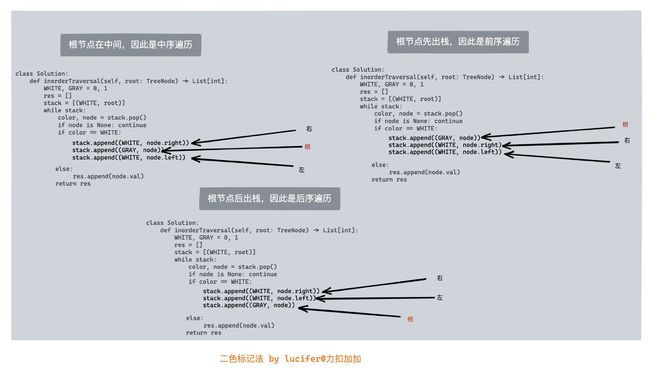
树的遍历迭代写法
其核心思想如下:
使用颜色标记节点的状态,新节点为白色,已访问的节点为灰色。
如果遇到的节点为白色,则将其标记为灰色,然后将其右子节点、自身、左子节点依次入栈。
如果遇到的节点为灰色,则将节点的值输出。
使用这种方法实现的中序遍历如下:
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
WHITE, GRAY = 0, 1
res = []
stack = [(WHITE, root)]
while stack:
color, node = stack.pop()
if node is None: continue
if color == WHITE:
stack.append((WHITE, node.right))
stack.append((GRAY, node))
stack.append((WHITE, node.left))
else:
res.append(node.val)
return res
简单总结一下,树的题目一个中心就是树的遍历。树的遍历分为两种,分别是深度优先遍历和广度优先遍历。关于树的不同深度优先遍历(前序,中序和后序遍历)的迭代写法是大多数人容易犯错的地方,因此我介绍了一种统一三种遍历的方法 - 二色标记法,这样大家以后写迭代的树的前中后序遍历就再也不用怕了。如果大家彻底熟悉了这种写法,再去记忆和练习一次入栈甚至是 Morris 遍历即可。
两个基本点
上面提到了树的遍历有两种基本方式,分别是深度优先遍历(以下简称 DFS)和广度优先遍历(以下简称 BFS),这就是两个基本点。这两种遍历方式下面又会细分几种方式。比如 DFS 细分为前中后序遍历, BFS 细分为带层的和不带层的。
而 BFS 适合求最短距离,这个和层次遍历是不一样的,很多人搞混。这里强调一下,层次遍历和 BFS 是完全不一样的东西。
层次遍历就是一层层遍历树,按照树的层次顺序进行访问。
BFS 的核心在于求最短问题时候可以提前终止,这才是它的核心价值,层次遍历是一种不需要提前终止的 BFS 的副产物。
深度优先遍历
算法流程
首先将根节点放入stack中。
从stack中取出第一个节点,并检验它是否为目标。如果找到所有的节点,则结束搜寻并回传结果。否则将它某一个尚未检验过的直接子节点加入stack中。
重复步骤 2。 如果不存在未检测过的直接子节点。将上一级节点加入stack中。 重复步骤 2。 重复步骤 4。
若stack为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。
这里的 stack可以理解为自己实现的栈,也可以理解为调用栈。如果是调用栈的时候就是递归,如果是自己实现的栈的话就是迭代。
广度优先遍历
带层信息
class Solution:
def bfs(k):
# 使用双端队列,而不是数组。因为数组从头部删除元素的时间复杂度为 N,双端队列的底层实现其实是链表。
queue = collections.deque([root])
# 记录层数
steps = 0
# 需要返回的节点
ans = []
# 队列不空,生命不止!
while queue:
size = len(queue)
# 遍历当前层的所有节点
for _ in range(size):
node = queue.popleft()
if (step == k) ans.append(node)
if node.right:
queue.append(node.right)
if node.left:
queue.append(node.left)
# 遍历完当前层所有的节点后 steps + 1
steps += 1
return ans
不带层信息
class Solution:
def bfs(k):
# 使用双端队列,而不是数组。因为数组从头部删除元素的时间复杂度为 N,双端队列的底层实现其实是链表。
queue = collections.deque([root])
# 队列不空,生命不止!
while queue:
node = queue.popleft()
# 由于没有记录 steps,因此我们肯定是不需要根据层的信息去判断的。否则就用带层的模板了。
if (node 是我们要找到的) return node
if node.right:
queue.append(node.right)
if node.left:
queue.append(node.left)
return -1
BFS 比较适合找最短距离/路径和某一个距离的目标。比如给定一个二叉树,在树的最后一行找到最左边的值。,此题是力扣 513 的原题。这不就是求距离根节点最远距离的目标么? 一个 BFS 模板就解决了
三种题型
搜索类
所有搜索类的题目只要把握三个核心点,即开始点,结束点 和 目标即可。
DFS 搜索
DFS 搜索类的基本套路就是从入口开始做 dfs,然后在 dfs
内部判断是否是结束点,这个结束点通常是叶子节点或空节点,关于结束这个话题我们放在七个技巧中的边界部分介绍,如果目标是一个基本值(比如数字)直接返回或者使用一个全局变量记录即可,如果是一个数组,则可以通过扩展参数的技巧来完成,关于扩展参数,会在七个技巧中的参数扩展部分介绍。
这基本就是搜索问题的全部了,当你读完后面的七个技巧,回头再回来看这个会更清晰。
套路模板:
# 其中 path 是树的路径, 如果需要就带上,不需要就不带
def dfs(root, path):
# 空节点
if not root: return
# 叶子节点
if not root.left and not root.right: return
path.append(root)
# 逻辑可以写这里,此时是前序遍历
dfs(root.left)
dfs(root.right)
# 需要弹出,不然会错误计算。
# 比如对于如下树:
"""
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
"""
# 如果不 pop,那么 5 -> 4 -> 11 -> 2 这条路径会变成 5 -> 4 -> 11 -> 7 -> 2,其 7 被错误地添加到了 path
path.pop()
# 逻辑也可以写这里,此时是后序遍历
return 你想返回的数据
Offer 34.** **二叉树中和为某一值的路径
比如剑指 Offer 34. 二叉树中和为某一值的路径 这道题,题目是:输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。 这不就是从根节点开始,到叶子节点结束的所有路径搜索出来,挑选出和为目标值的路径么?这里的开始点是根节点, 结束点是叶子节点,目标就是路径。
对于求这种满足特定和的题目,我们都可以方便地使用前序遍历 + 参数扩展的形式,关于这个,我会在七个技巧中的前后序部分展开。
由于需要找到所有的路径,而不仅仅是一条,因此这里适合使用回溯暴力枚举。关于回溯,可以参考我的 回溯专题
class Solution:
def pathSum(self, root: TreeNode, target: int) -> List[List[int]]:
def backtrack(nodes, path, cur, remain):
# 空节点
if not cur: return
# 叶子节点
if cur and not cur.left and not cur.right:
if remain == cur.val:
res.append((path + [cur.val]).copy())
return
# 选择
path.append(cur.val)
# 递归左右子树
backtrack(nodes, path, cur.left, remain - cur.val)
backtrack(nodes, path, cur.right, remain - cur.val)
# 撤销选择
path.pop(-1)
ans = []
# 入口,路径,目标值全部传进去,其中路径和path都是扩展的参数
backtrack(ans, [], root, target)
return ans
1372. 二叉树中的最长交错路径
再比如:**1372. 二叉树中的最长交错路径,**题目描述:
给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下:
选择二叉树中 任意 节点和一个方向(左或者右)。 如果前进方向为右,那么移动到当前节点的的右子节点,否则移动到它的左子节点。
改变前进方向:左变右或者右变左。 重复第二步和第三步,直到你在树中无法继续移动。 交错路径的长度定义为:访问过的节点数目 -
1(单个节点的路径长度为 0 )。请你返回给定树中最长 交错路径 的长度。
比如:
此时需要返回 3 解释:蓝色节点为树中最长交错路径(右 -> 左 -> 右)。
这不就是从任意节点开始,到任意节点结束的所有交错路径全部搜索出来,挑选出最长的么?这里的开始点是树中的任意节点,结束点也是任意节点,目标就是最长的交错路径。
对于入口是任意节点的题目,我们都可以方便地使用双递归来完成,关于这个,我会在七个技巧中的单/双递归部分展开。
对于这种交错类的题目,一个好用的技巧是使用 -1 和 1 来记录方向,这样我们就可以通过乘以 -1 得到另外一个方向。
886. 可能的二分法 和 785. 判断二分图 都用了这个技巧。
用代码表示就是:
next_direction = cur_direction * - 1
这里我们使用双递归即可解决。 如果题目限定了只从根节点开始,那就可以用单递归解决了。值得注意的是,这里内部递归需要 cache 一下 , 不然容易因为重复计算导致超时。
我的代码是 Python,这里的 lru_cache 就是一个缓存,大家可以使用自己语言的字典模拟实现。
class Solution:
@lru_cache(None)
def dfs(self, root, dir):
if not root:
return 0
if dir == -1:
return int(root.left != None) + self.dfs(root.left, dir * -1)
return int(root.right != None) + self.dfs(root.right, dir * -1)
def longestZigZag(self, root: TreeNode) -> int:
if not root:
return 0
return max(self.dfs(root, 1), self.dfs(root, -1), self.longestZigZag(root.left), self.longestZigZag(root.right))
BFS 搜索
这种类型相比 DFS,题目数量明显降低,套路也少很多。题目大多是求距离,套用我上面的两种 BFS 模板基本都可以轻松解决,这个不多介绍了。
构建类
除了搜索类,另外一个大头是构建类。构建类又分为两种:普通二叉树的构建和二叉搜索树的构建。
普通二叉树的构建
而普通二叉树的构建又分为三种:
- 给你两种 DFS 的遍历的结果数组,让你构建出原始的树结构。
比如根据先序遍历和后序遍历的数组,构造原始二叉树。这种题我在构造二叉树系列 系列里讲的很清楚了,大家可以去看看。
这种题目假设输入的遍历的序列中都不含重复的数字,想想这是为什么。
- 给你一个 BFS 的遍历的结果数组,让你构建出原始的树结构。
最经典的就是 剑指 Offer 37.
序列化二叉树。我们知道力扣的所有的树表示都是使用数字来表示的,而这个数组就是一棵树的层次遍历结果,部分叶子节点的子节点(空节点)也会被打印。比如:[1,2,3,null,null,4,5],就表示的是如下的一颗二叉树:
- 还有一种是给你描述一种场景,让你构造一个符合条件的二叉树
。这种题和上面的没啥区别,套路简直不要太像,比如 654. 最大二叉树,我就不多说了,大家通过这道题练习一下就知道了。
- 动态构建二叉树的 比如 894. 所有可能的满二叉树 ,对于这个题,直接 BFS 就好了。由于这种题很少,因此不做多的介绍。大家只要把最核心的掌握了,这种东西自然水到渠成。
二叉搜索树的构建
原因就在于二叉搜索树的根节点的值大于所有的左子树的值,且小于所有的右子树的值。因此我们可以根据这一特性去确定左右子树的位置,经过这样的转换就和上面的普通二叉树没有啥区别了。比如
1008. 前序遍历构造二叉搜索树
修改类
增加,删除节点,或者是修改节点的值或者指向。
修改指针的题目一般不难,比如 116. 填充每个节点的下一个右侧节点指针,这不就是 BFS 的时候顺便记录一下上一次访问的同层节点,然后增加一个指针不就行了么?关于 BFS ,套用我的带层的 BFS 模板就搞定了。
增加和删除的题目一般稍微复杂,比如 450. 删除二叉搜索树中的节点 和 669. 修剪二叉搜索树。西法我教你两个套路,面对这种问题就不带怕的。那就是后续遍历 + 虚拟节点,
实际工程中,我们也可以不删除节点,而是给节点做一个标记,表示已经被删除了,这叫做软删除。
另外一种是为了方便计算,自己加了一个指针。
比如 863. 二叉树中所有距离为 K 的结点 通过修改树的节点类,增加一个指向父节点的引用 parent,问题就转化为距离目标节点一定距离的问题了,此时可是用我上面讲的带层的 BFS 模板解决。
四个重要概念
二叉搜索树
若左子树不空,则左子树上所有节点的值均小于它的根节点的值; 若右子树不空,则右子树上所有节点的值均大于它的根节点的值;
左、右子树也分别为二叉排序树; 没有键值相等的节点。 对于一个二叉查找树,常规操作有插入,查找,删除,找父节点,求最大值,求最小值。
中序遍历是有序的
另外二叉查找树有一个性质,这个性质对于做题很多帮助,那就是: 二叉搜索树的中序遍历的结果是一个有序数组。 比如 98. 验证二叉搜索树 就可以直接中序遍历,并一边遍历一边判断遍历结果是否是单调递增的,如果不是则提前返回 False 即可。
再比如 99. 恢复二叉搜索树,官方难度为困难。题目大意是给你二叉搜索树的根节点 root ,该树中的两个节点被错误地交换。请在不改变其结构的情况下,恢复这棵树。 *我们可以先中序遍历发现不是递增的节点,他们就是被错误交换的节点,然后交换恢复即可。这道题难点就在于一点,即错误交换可能错误交换了中序遍历的相邻节点或者中序遍历的非相邻节点,这是两种 case,需要分别讨论 *。
完全二叉树
一棵深度为 k 的有 n 个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为
i(1≤i≤n)的结点与满二叉树中编号为 i 的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
直接考察完全二叉树的题目虽然不多,貌似只有一道 222. 完全二叉树的节点个数(二分可解),但是理解完全二叉树对你做题其实帮助很大。
如上图,是一颗普通的二叉树。如果我将其中的空节点补充完全,那么它就是一颗完全二叉树了。
这有什么用呢?这很有用!我总结了两个用处:
我们可以给完全二叉树编号,这样父子之间就可以通过编号轻松求出。比如我给所有节点从左到右从上到下依次从 1 开始编号。那么已知一个节点的编号是
i,那么其左子节点就是 2 i,右子节点就是 2 1 + 1,父节点就是 (i + 1) / 2。
**662. 二叉树最大宽度。**题目描述:
给定一个二叉树,编写一个函数来获取这个树的最大宽度。树的宽度是所有层中的最大宽度。这个二叉树与满二叉树(full binary tree)结构相同,但一些节点为空。
每一层的宽度被定义为两个端点(该层最左和最右的非空节点,两端点间的null节点也计入长度)之间的长度。
示例 1:
输入:
1
/ \
3 2
/ \ \
5 3 9
输出: 4
解释: 最大值出现在树的第 3 层,宽度为 4 (5,3,null,9)。
很简单,一个带层的 BFS 模板即可搞定,简直就是默写题。不过这里需要注意两点:
入队的时候除了要将普通节点入队,还要空节点入队。
出队的时候除了入队节点本身,还要将节点的位置信息入队,即下方代码的 pos。
参考代码:
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def widthOfBinaryTree(self, root: TreeNode) -> int:
q = collections.deque([(root, 0)])
steps = 0
cur_depth = leftmost = ans = 0
while q:
for _ in range(len(q)):
node, pos = q.popleft()
if node:
# 节点编号关关系是不是用上了?
q.append((node.left, pos * 2))
q.append((node.right, pos * 2 + 1))
# 逻辑开始
if cur_depth != steps:
cur_depth = steps
leftmost = pos
ans = max(ans, pos - leftmost + 1)
# 逻辑结束
steps += 1
return ans
再比如剑指 **Offer 37. 序列化二叉树。**如果我将一个二叉树的完全二叉树形式序列化,然后通过 BFS 反序列化,这不就是力扣官方序列化树的方式么?比如:
1
/
2 3
/
4 5
序列化为 “[1,2,3,null,null,4,5]”。 这不就是我刚刚画的完全二叉树么?就是将一个普通的二叉树硬生生当成完全二叉树用了。
其实这并不是序列化成了完全二叉树,下面会纠正。
将一颗普通树序列化为完全二叉树很简单,只要将空节点当成普通节点入队处理即可。代码:
class Codec:
def serialize(self, root):
q = collections.deque([root])
ans = ‘’
while q:
cur = q.popleft()
if cur:
ans += str(cur.val) + ‘,’
q.append(cur.left)
q.append(cur.right)
else:
# 除了这里不一样,其他和普通的不记录层的 BFS 没区别
ans += ‘null,’
# 末尾会多一个逗号,我们去掉它。
return ans[:-1]
细心的同学可能会发现,我上面的代码其实并不是将树序列化成了完全二叉树,这个我们稍后就会讲到。另外后面多余的空节点也一并序列化了。这其实是可以优化的,优化的方式也很简单,那就是去除末尾的 null 即可。
你只要彻底理解我刚才讲的我们可以给完全二叉树编号,这样父子之间就可以通过编号轻松求出。比如我给所有节点从左到右从上到下依次从 1 开始编号。那么已知一个节点的编号是 i,那么其左子节点就是 2 * i,右子节点就是 2 * 1 + 1,父节点就是 (i + 1) / 2。 这句话,那么反序列化对你就不是难事。
如果我用一个箭头表示节点的父子关系,箭头指向节点的两个子节点,那么大概是这样的:
我们刚才提到了:
1 号节点的两个子节点的 2 号 和 3 号。
2 号节点的两个子节点的 4 号 和 5 号。
。。。
i 号节点的两个子节点的 2 * i 号 和 2 * 1 + 1 号。
此时你可能会写出类似这样的代码:
def deserialize(self, data):
if data == ‘null’: return None
nodes = data.split(’,’)
root = TreeNode(nodes[0])
# 从一号开始编号,编号信息一起入队
q = collections.deque([(root, 1)])
while q:
cur, i = q.popleft()
# 2 * i 是左节点,而 2 * i 编号对应的其实是索引为 2 * i - 1 的元素, 右节点同理。
if 2 * i - 1 < len(nodes): lv = nodes[2 * i - 1]
if 2 * i < len(nodes): rv = nodes[2 * i]
if lv != ‘null’:
l = TreeNode(lv)
# 将左节点和 它的编号 2 * i 入队
q.append((l, 2 * i))
cur.left = l
if rv != ‘null’:
r = TreeNode(rv)
# 将右节点和 它的编号 2 * i + 1 入队
q.append((r, 2 * i + 1))
cur.right = r
return root
但是上面的代码是不对的,因为我们序列化的时候其实不是完全二叉树,这也是上面我埋下的伏笔。因此遇到类似这样的 case 就会挂:
这也是我前面说”上面代码的序列化并不是一颗完全二叉树“的原因。
其实这个很好解决, 核心还是上面我画的那种图:
其实我们可以:
用三个指针分别指向数组第一项,第二项和第三项(如果存在的话),这里用 p1,p2,p3
来标记,分别表示当前处理的节点,当前处理的节点的左子节点和当前处理的节点的右子节点。 p1 每次移动一位,p2 和 p3 每次移动两位。
p1.left = p2; p1.right = p3。 持续上面的步骤直到 p1 移动到最后。
因此代码就不难写出了。反序列化代码如下:
def deserialize(self, data):
if data == 'null': return None
nodes = data.split(',')
root = TreeNode(nodes[0])
q = collections.deque([root])
i = 0
while q and i < len(nodes) - 2:
cur = q.popleft()
lv = nodes[i + 1]
rv = nodes[i + 2]
i += 2
if lv != 'null':
l = TreeNode(lv)
q.append(l)
cur.left = l
if rv != 'null':
r = TreeNode(rv)
q.append(r)
cur.right = r
return root
这个题目虽然并不是完全二叉树的题目,但是却和完全二叉树很像,有借鉴完全二叉树的地方。
路径
124.二叉树中的最大路径和
虽然是困难难度,但是搞清楚概念的话,和简单难度没啥区别。 接下来,我们就以这道题讲解一下。
这道题的题目是
给定一个非空二叉树,返回其最大路径和。路径的概念是:一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。该路径至少包含一个节点,且不一定经过根节点个描述我会想到大概率是要么全局记录最大值,要么双递归。 如果使用双递归,那么复杂度就是
,实际上,子树的路径和计算出来了,可以推导出父节点的最大路径和,因此如果使用双递归会有重复计算。一个可行的方式是记忆化递归。
如果使用全局记录最大值,只需要在递归的时候 return
当前的一条边(上面提了不能拐),并在函数内部计算以当前节点出发的最大路径和,并更新全局最大值即可。 这里的核心其实是 return
较大的一条边,因为较小的边不可能是答案。
这里我选择使用第二种方法。
代码:
class Solution:
ans = float('-inf')
def maxPathSum(self, root: TreeNode) -> int:
def dfs(node):
if not node: return 0
l = dfs(node.left)
r = dfs(node.right)
# 选择当前的节点,并选择左右两边,当然左右两边也可以不选。必要时更新全局最大值
self.ans = max(self.ans, max(l,0) + max(r, 0) + node.val)
# 只返回一边,因此我们挑大的返回。当然左右两边也可以不选
return max(l, r, 0) + node.val
dfs(root)
return self.ans
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def maxPathSum(self, root):
"""
:type root: TreeNode
:rtype: int
"""
# 思路:递归求解,递归求解以某一个结点为起始结点的最大路径和,
# 它等于当前结点的值+max(以左子结点为起始结点的最大路径和,以右子结点为起始结点的最大路径和);
# 在递归的过程中,更新最大的路径和的值,它等于当前结点的值+左子结点的最大路径和+右子结点的最大路径和
self.res = float('-inf')
self.dfs(root)
return self.res
def dfs(self, root):
if not root:
return 0
left = self.dfs(root.left)
right = self.dfs(root.right)
left = left if left > 0 else 0
right = right if right > 0 else 0
self.res = max(self.res, left + root.val + right)
return max(left, right) + root.val
类似题目 113. 路径总和 I
距离
和路径类似,距离也是一个相似且频繁出现的一个考点,并且二者都是搜索类题目的考点。原因就在于最短路径就是距离,而树的最短路径就是边的数目。
这两个题练习一下,碰到距离的题目基本就稳了。
834.树中距离之和
863.二叉树中所有距离为 K 的结点