Ubuntu20.04安装Hadoop和Hive
Ubuntu20.04安装Hadoop和Hive
-
-
- 一、安装Mysql
- 二、安装Hadoop
-
- 1.1创建Hadoop用户(如果需要将本机的账户与Hadoop分开,可以新建一个新用户)
- 2.1安装SSH
- 2.2安装JDK1.8.0_251
- 3.1下载Hadoop-3.2.1
- 3.2伪分布式配置
- 3.3查看安装是否成功
- 三、安装Hive
-
- 1.1下载Hive-3.1.2
- 1.2解压Hive到/opt目录下
- 2.1配置Hive环境变量
- 2.2创建hive-site.xml
- 2.3配置hive-env.sh文件
- 3.1将JDBC的jar包拷贝在/opt/hive/lib目录下
- 3.2在/opt/hive-3.2.1/bin目录下执行以下命令
- 程序错误类型
-
- 1.1com.google.common.base.Preconditions.checkArgument
- 1.2hive启动jdk报错
- 1.3数据库没有连接成功
-
一、安装Mysql
在安装hive时需要安装mysql,并设置权限,(把包放在系统目录下,如/usr或/opt此类目录下,需要使用chmod命令修改权限,否则很有可能出现权限不足无法执行的情况)
没有安装的可以参考Ubuntu20.04安装Mysql
二、安装Hadoop
1.1创建Hadoop用户(如果需要将本机的账户与Hadoop分开,可以新建一个新用户)
sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
sudo passwd hadoop #为hadoop用户设置密码
sudo adduser hadoop sudo #为hadoop用户增加管理员权限
su - hadoop #切换当前用户为用户hadoop
sudo apt-get update #更新hadoop用户
2.1安装SSH
sudo apt-get install openssh-server #安装SSH server
ssh localhost #登陆SSH,第一次登陆输入yes
exit #退出登录的ssh localhost
cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
ssh-keygen -t rsa
在输入完 $ ssh-keygen -t rsa 命令时,需要连续敲击回车三次
其中,第一次回车是让KEY存于默认位置,以方便后续的命令输入。第二次和第三次是确定passphrase,相关性不大。两次回车输入完毕以后,如果出现类似于下图所示的输出,即成功:
图片描述
之后输入
cd .ssh
#创建authorized_keys文件并修改权限为600
touch authorized_keys
chmod 600 authorized_keys
cat ./id_rsa.pub >> ./authorized_keys #加入授权
ssh localhost #此时已不需密码即可登录localhost,并可见下图。如果失败则可以搜索SSH免密码登录来寻求答案

2.2安装JDK1.8.0_251
首先在oracle官网下载JDK1.8.0_251
https://www.oracle.com/java/technologies/javase-downloads.html
选择1.8.不要用14版本要不然会出现版本不兼容的错误
mkdir /usr/lib/jvm #创建jvm文件夹
sudo tar zxvf 你的jdk文件名 -C /usr/lib/jvm #/解压到/usr/lib/jvm目录下
cd /usr/lib/jvm #进入该目录
mv jdk1.8.0_251 java #重命名为java
vi ~/.bashrc #给JDK配置环境变量
其中如果权限不够,无法在相关目录下创建jvm文件夹,那么可以使用 $ sudo -i 语句进入root账户来创建文件夹。
vim ~/.bashrc
若没有vim可以用gedit代替或使用sudo apt安装vim
在 ~/.bashrc 文件中添加如下代码
#Java Environment
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
修改完成后,使用如下命令
source ~/.bashrc #使新配置的环境变量生效
java -version #检测是否安装成功,查看java版本

3.1下载Hadoop-3.2.1
https://archive.apache.org/dist/hadoop/common/
切换到下载文件的位置/Downloads,找到下载的文件进行安装
sudo tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local #解压到/usr/local目录下
cd /usr/local
#sudo mv hadoop-3.2.1 hadoop #重命名为hadoop,可改可不改,如果修改下边的名字也要对应
sudo chown -R hadoop ./hadoop-3.2.1 #修改文件权限
给hadoop配置环境变量,将下面代码添加到.bashrc文件:
#Hadoop Environment
export HADOOP_HOME=/usr/local/hadoop-3.2.1
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
同样,执行source ~./bashrc使设置生效,并查看hadoop version是否安装成功,若出现hadoop版本即为安装成功
![]()
3.2伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 /usr/local/hadoop-3.2.1/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。首先将jdk1.8的路径添(export JAVA_HOME=/usr/lib/jvm/java )加到hadoop-env.sh文件
接下来修改core-site.xml文件:
hadoop.tmp.dir
file:/usr/local/hadoop-3.2.1/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
修改hdfs-site.xml文件:
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop-3.2.1/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop-3.2.1/tmp/dfs/data
dfs.http.address
0.0.0.0:50070
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(可参考官方教程),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化
这个路径是在**/usr/local/hadoop-3.2.1/bin**
cd /usr/local/hadoop-3.2.1/bin
hdfs namenode -format
注意:
不能一直格式化NameNode,格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
启动namenode和datanode进程,并查看启动结果
路径:/usr/local/hadoop-3.2.1/sbin
cd /usr/local/hadoop-3.2.1/sbin
start-dfs.sh
jps
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”
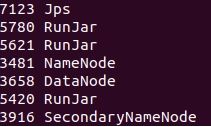
图中只需有四个进程"JPS" “NameNode” “DateNode” "SecondaryNameNode"即可
此时也有可能出现要求输入localhost密码的情况 ,如果此时明明输入的是正确的密码却仍无法登入,其原因是由于如果不输入用户名的时候默认的是root用户,但是安全期间ssh服务默认没有开root用户的ssh权限
输入代码:
sudo vi /etc/ssh/sshd_config
3.3查看安装是否成功
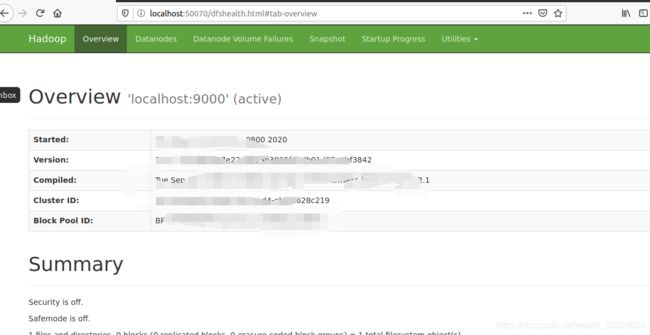
成功启动后,在浏览器中输入localhost:50070会出现以下页面
三、安装Hive
1.1下载Hive-3.1.2
http://mirror.bit.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
1.2解压Hive到/opt目录下
tar zxf apache-hive-3.1.2-bin.tar.gz
sudo mv apache-hive-3.1.2-bin /opt/hive-3.2.1
2.1配置Hive环境变量
使用修改vim,需要用户权限
sudo vi ~/.bashrc
在bashrc文件中添加如下代码,如需修改权限请使用chmod命令
#Hive Enviroment
export HIVE_HOME=/opt/hive-3.2.1
export PATH=$PATH:$HIVE_HOME/bin
2.2创建hive-site.xml
在/opt/hive-3.2.1/conf目录下,创建hive-site.xml,并添加以下代码在文件中
touch hive-site.xml #创建文件
sudo vi hive-site.xml #修改编辑
hive.metastore.schema.verification
false
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
hive.metastore.warehouse.dir
/user/hive/warehouse
location of default database for the warehouse
hive.exec.scratchdir
/tmp/hive
HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/myhive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.cj.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
数据库密码
password to use against metastore database
可选配置,该配置信息用来指定 Hive 数据仓库的数据存储在 HDFS 上的目录
在hive-site.xml 中如下HDFS相关设置,因此我们需要现在HDFS中创建对应的目录:
hive.metastore.warehouse.dir
/user/hive/warehouse
location of default database for the warehouse
hive.exec.scratchdir
/tmp/hive
HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.
创建两个对应的目录并赋予读写权限:
$hadoop fs -mkdir -p /user/hive/warehouse
$ hadoop fs -mkdir -p /tmp/hive
$ hadoop fs -chmod -R 777 /user/hive/warehouse
$ hadoop fs -chmod -R 777 /tmp/hive
$ hadoop fs -ls /
注意不同版本的数据库对应不同数据库的驱动类名称
新版本8.0版本的驱动为com.mysql.cj.jdbc.Driver
旧版本5.x版本的驱动为com.mysql.jdbc.Driver
2.3配置hive-env.sh文件
在/opt/hive-3.2.1/conf下执行该命令
cp hive-env.sh.template hive-env.sh
将a、b两个配置添加到hive-env.sh
(a)配置HADOOP_HOME路径
export HADOOP_HOME=/opt/module/hadoop-2.7.2
(b)配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/module/hive/conf
3.1将JDBC的jar包拷贝在/opt/hive/lib目录下
https://dev.mysql.com/downloads/file/?id=494887
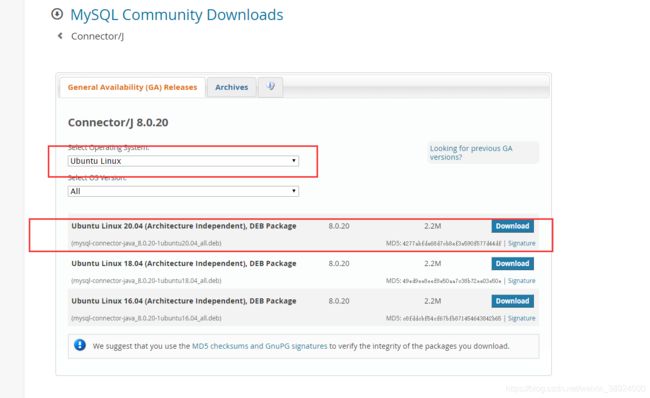
解压文件,将文件中的mysql-connector-java-8.0.15.jar复制到/opt/hive-3.2.1/lib中
sudo tar zxvf mysql-connector-java-8.0.15.zip
cd /Downloads/mysql-connector-java-8.0.15
sudo mv mysql-connector-java-8.0.15.jar /opt/hive-3.1.2/lib
3.2在/opt/hive-3.2.1/bin目录下执行以下命令
schematool -dbType mysql -initSchema
schematool -dbType mysql -info
hive

程序错误类型
1.1com.google.common.base.Preconditions.checkArgument
如果出现这类报错:

com.google.common.base.Preconditions.checkArgument 这是因为hive内依赖的guava.jar和hadoop内的版本不一致造成的。 检验方法:
1.查看hadoop安装目录下/usr/local/hadoop-3.2.1/share/hadoop/common/lib内guava.jar版本
2.查看hive安装目录下/opt/hive-3.1.2/lib内guava.jar的版本 如果两者不一致,删除版本低的,并拷贝高版本的 问题解决!
1.2hive启动jdk报错
错误:
Exception in thread "main" java.lang.ClassCastException: class jdk.internal.loader.ClassLoaders$AppClassLoader cannot be cast to class java.net.URLClassLoader (jdk.internal.loader.ClassLoaders$AppClassLoader and java.net.URLClassLoader are in module java.base of loader 'bootstrap')
.....
.....
这是因为JDK的版本与hive不兼容,所以出现报错,我之前使用的是最新版的JDK14,我们只需要将JDK的版本跟换为JDK1.8的版本就可以解决问题。
1.3数据库没有连接成功
错误:
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: com.mysql.cj.jdbc.exceptions.CommunicationsException : Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
SQL Error code: 0
Use --verbose for detailed stacktrace.
*** schemaTool failed ***
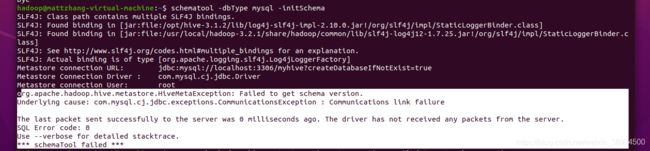
检查mysql是否密码正确 ,一般情况都是自己的MySQL出现了问题。