推荐系统之矩阵分解模型原理及Python实现
一、矩阵算法概述
原本在使用各种APP的时候觉得推荐算法是一个神奇的东西,恰巧要做手厅用户的前人千面,所以利用协同过滤做了手厅的基于产品的推荐模型,发现出来的产品推荐很接近,更充满好奇心,所以有了接下来各种推荐算法的学习。在各种资料中,发现了基于矩阵分解的推荐系统,学习了它的原理之后,发现矩阵算法对于推荐的效果更好且更好运用。接下来介绍矩阵分解的原理。
矩阵分解(Matrix Factorization, MF),下面简称MF,矩阵算法就是,将用户和产品矩阵中的数据,分解成两个矩阵(用User矩阵和Item矩阵),两个矩阵相乘得到的结果就是预测评分。当我们要计算第i 个用户对第j 个item的预测评分时),我们就可以用User矩阵的第i行和Item矩阵的第j 列做内积,这个内积的值就是预测评分了。对于某个用户进行推荐时,我们把他的用户向量和所有item向量做内积,然后按内积从大到小排序,取出前K 个item,过滤掉历史item后推荐给用户。
那MF是如何从评分矩阵中分解出User矩阵和Item矩阵的呢?简单来说,MF把User矩阵和Item矩阵作为未知量,用它们表示出每个用户对每个item的预测评分,然后通过最小化预测评分跟已知实际评分的差异,学习出User矩阵和Item矩阵。

二、矩阵算法推导公式
矩阵分解是指一个矩阵分解成两个或者多个矩阵的乘积。对于评分矩阵记为R(m×n),分解成两个矩阵P(m×k)和Q(k×n),我们要使得矩阵P(m×k)和Q(k×n)的乘积能够还原原始的矩阵R(m×n)。
![]()
其中,矩阵P(m×k)表示的是m个用户与k个主题之间的关系,而矩阵Q(k×n)表示的是k个主题与n个商品之间的关系。
那么接下来的问题是如何求解矩阵Pm×kPm×k和Qk×nQk×n的每一个元素,可以将这个问题转化成机器学习中的回归问题进行求解。
损失函数
可以使用原始的评分矩阵Rm×nRm×n与重新构建的评分矩阵Rm×nRm×n之间的误差的平方作为损失函数,即:

最终,求解所有有评分项的损失值和的最小值。

损失函数的求解,可以通过梯度下降法求解,求解损失函数的负梯度:
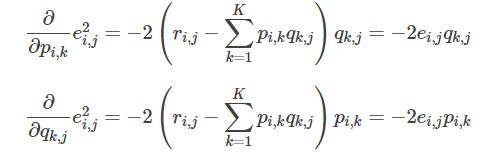
根据负梯度的方向更新变量:

通过迭代,直到算法最终收敛。
为了能够有较好的泛化能力,为了防止过拟合,会在损失函数中加入正则项,以对参数进行约束,加入L2正则的损失函数为:
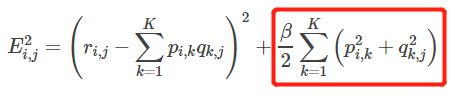
求解损失函数的负梯度:

根据负梯度的方向更新变量:
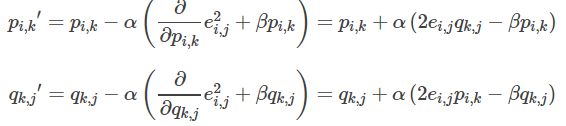
通过迭代,直到算法最终收敛。
预测
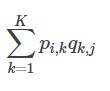
三、Python实现
1、下面利用用户观看的电影数据来实现矩阵分解的推荐。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
movies_df = pd.read_csv("C:\\Users\\data\\movies.csv")
ratings_df = pd.read_csv("C:\\Users\\data\\real_ratings.csv")


2、创建定影评分表
userNo=max(ratings_df['userId']+1) #用户数量
movieNo=max(ratings_df['movieRow'])+1#电影数量
rating = np.zeros((userNo,movieNo)) #生成零矩阵
for index,row in ratings_df.iterrows(): #评分
rating[int(row['userId']),int(row['movieRow'])]=row['rating'] #填充得分

def matrix_factorization(data,K,steps=100,alpha=0.0002,beta=0.02):
#获取用户数和电影数
M,N = data.shape
#初始化参数
P=np.random.rand(M,K)#随机生成一个矩阵
Q=np.random.rand(K,N)
result=[]
for step in range(steps):
for i in range(len(data)):
for j in range(len(data[i])):
if data[i][j]>0:
eij=data[i][j]-np.dot(P[i,:],Q[:,j]) # .dot(P,Q) 表示矩阵内积
for k in range(K):
P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k])#负梯度方向跟新变量
Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j])
eR=np.dot(P,Q)
e=0
for i in range(len(data)):
for j in range(len(data[i])):
if data[i][j]>0:
e=e+pow(data[i][j]-np.dot(P[i,:],Q[:,j]),2) #损失函数
for k in range(K):
e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2))#加入正则项的损失函数
result.append(e)
if e<0.001: #损失函数小于阈值,算法收敛
break
return P,Q,result
def save_file(file_name, source):#保存结果
f = open(file_name, "w")
m, n = np.shape(source)
for i in range(m):
tmp = []
for j in range(n):
tmp.append(str(source[i, j]))
f.write("\t".join(tmp) + "\n")
f.close()
def prediction(dataMatrix, p, q, user):#预测为用户user未互动的项打分
n = np.shape(dataMatrix)[1]
predict = {}
for j in range(n):
if dataMatrix[user, j] == 0:
predict[j] = np.dot(p[user,], q[:, j])
return sorted(predict.items(), key=lambda d: d[1], reverse=True)
def top_k(predict, k):#为用户推荐前k个商品
top_recom = []
len_result = len(predict)
if k >= len_result:
top_recom = predict
else:
for i in range(k):
top_recom.append(predict[i])
return top_recom
if __name__ == "__main__":
nP,nQ,result=matrix_factorization(rating,20)
save_file("p", nP)
save_file("q", nQ)
predict = prediction(rating, nP, nQ, 7)
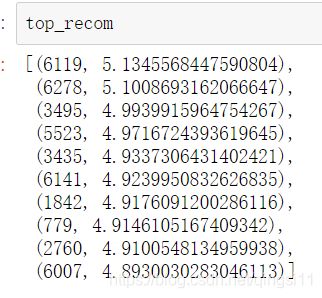
top_recom = top_k(predict, 10)
#-------------损失函数的收敛曲线图---------------
n=len(result)
x=range(n)
plt.plot(x,result,color='r',linewidth=3)
plt.title("Covergence curve")
plt.xlabel("generation")
plt.ylabel("loss")
plt.show()
其中,利用梯度下降法进行矩阵分解的过程中的收敛曲线如下所示:
推荐的前10部电影及得分