bert模型源码详细解读
一.bert配置参数解读 bert_config.json
{
"attention_probs_dropout_prob": 0.1, #乘法attention时,softmax后dropout概率
"directionality": "bidi",
"hidden_act": "gelu", # 激活函数
"hidden_dropout_prob": 0.1, #隐藏层dropout概率
"hidden_size": 768, # 词向量的维度
"initializer_range": 0.02, # 初始化范围
"intermediate_size": 3072, # 升维维度
"max_position_embeddings": 512, # 最大的
"num_attention_heads": 12, # 总的头数
"num_hidden_layers": 12, #隐藏层数 ,也就是transformer的encode运行的次数
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2, #segment_ids类别 [0,1]
"vocab_size": 21128 #词典中词数
}
二. bert模型的输入:
1.config : bert预训练模型的配置文件路径
2. input_ids :[batch_size,max_seq_length]
3. input_mask: 是否有掩码 [batch_size, seq_length] 全是1
4. token_type_ids:是否有上下文信息 [batch_size, seq_length] 全是0
class BertModel(object):
def __init__(self,
config,
is_training,
input_ids,
input_mask=None,
token_type_ids=None,
use_one_hot_embeddings=False,
scope=None):
config = copy.deepcopy(config)
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0]
seq_length = input_shape[1]
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
with tf.variable_scope("embeddings"):
# Perform embedding lookup on the word ids.
# embedding_output = [batch_size, max_seq_length, embedding_size].
# embedding_table = [vocab_size, embedding_size]
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# Add positional embeddings and token type embeddings, then layer
# normalize and perform dropout.
# 将矩阵加入位置信息,再经过nl和dropout
# 位置信息就是一个大矩阵,是需要训练的,并不是transformer里面那样加的
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# This converts a 2D mask of shape [batch_size, seq_length] to a 3D
# mask of shape [batch_size, seq_length, seq_length] which is used
# for the attention scores.
# [batch_size, seq_length, seq_length]
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# Run the stacked transformer.
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
self.sequence_output = self.all_encoder_layers[-1]
# The "pooler" converts the encoded sequence tensor of shape
# [batch_size, seq_length, hidden_size] to a tensor of shape
# [batch_size, hidden_size]. This is necessary for segment-level
# (or segment-pair-level) classification tasks where we need a fixed
# dimensional representation of the segment.
with tf.variable_scope("pooler"):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. We assume that this has been pre-trained
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
三.embedding_lookup层
得到的输出shape是 :
embedding_output = [batch_size,max_seq_length, embedding_size].
embedding_table = [vocab_size, embedding_size]
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
def embedding_lookup(input_ids,
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
# If the input is a 2D tensor of shape [batch_size, seq_length], we
# reshape to [batch_size, seq_length, 1].
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
# 将所有的数据推开
flat_input_ids = tf.reshape(input_ids, [-1])
if use_one_hot_embeddings:
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else:
# go here
# output = [batch_size, embedding_dim]
output = tf.gather(embedding_table, flat_input_ids)
# 得到 input_ids的具体维度(batch_size,max_seq_length)
input_shape = get_shape_list(input_ids)
# outputs = (batch_size, max_seq_length ,embendding_size)
output = tf.reshape(output, input_shape[0:-1] + [input_shape[-1] * embedding_size])
return (output, embedding_table)
四.embedding_postprocessor层,segment上下文信息,加入位置信息,再经过nl和dropout
就是完成下面这一步骤:

但此代码中Position Embeddings部分与之前提出的Transformer不同,此代码中Position Embeddings是训练出来的,而传统的Transformer(如下)是固定值
在这里插入图片描述
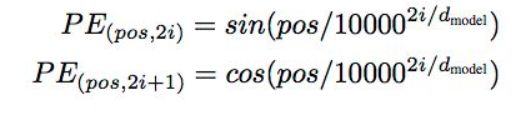
embedding_output 输出结果shape依然是[batch_size, max_seq_length,embedding_size],只是在原有的基础上加了上下文信息,位置信息,以及nl+droupout()
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
"""Performs various post-processing on a word embedding tensor.
Args:
input_tensor: float Tensor of shape [batch_size, seq_length,
embedding_size].
use_token_type: bool. Whether to add embeddings for `token_type_ids`.
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
Must be specified if `use_token_type` is True.
token_type_vocab_size: int. The vocabulary size of `token_type_ids`.
token_type_embedding_name: string. The name of the embedding table variable
for token type ids.
use_position_embeddings: bool. Whether to add position embeddings for the
position of each token in the sequence.
position_embedding_name: string. The name of the embedding table variable
for positional embeddings.
initializer_range: float. Range of the weight initialization.
max_position_embeddings: int. Maximum sequence length that might ever be
used with this model. This can be longer than the sequence length of
input_tensor, but cannot be shorter.
dropout_prob: float. Dropout probability applied to the final output tensor.
Returns:
float tensor with same shape as `input_tensor`.
Raises:
ValueError: One of the tensor shapes or input values is invalid.
"""
# input_tensor = [batch_size, max_seq_length, embedding_size].
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2]
output = input_tensor
# 加入上下句之间的信息关系,EA,EB
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
# bert配置文件配置的是[2,embedding_size]
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# This vocab will be small so we always do one-hot here, since it is always
# faster for a small vocabulary.
# 将其全部展开
# token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
# one_hot_ids = [batch_size*max_seq_length, token_type_vocab_size=2]
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
output += token_type_embeddings
if use_position_embeddings:
# 如果x>y就抛出异常
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings)
with tf.control_dependencies([assert_op]):
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# Since the position embedding table is a learned variable, we create it
# using a (long) sequence length `max_position_embeddings`. The actual
# sequence length might be shorter than this, for faster training of
# tasks that do not have long sequences.
#
# So `full_position_embeddings` is effectively an embedding table
# for position [0, 1, 2, ..., max_position_embeddings-1], and the current
# sequence has positions [0, 1, 2, ... seq_length-1], so we can just
# perform a slice.
# position_embeddings = (max_seq_length, embeding_dim)
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1])
# num_dims = 3 有多少维度结果就是多少
num_dims = len(output.shape.as_list())
# Only the last two dimensions are relevant (`seq_length` and `width`), so
# we broadcast among the first dimensions, which is typically just
# the batch size.
# 下面操作也就是多加一个维度,使其可以用reshape()转换为output维度,才能相加
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
return output
五.create_attention_mask_from_input_mask()层,在输入的句子上加入掩码
输出的结构是 [batch_size, max_seq_length, max_seq_length]
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
def create_attention_mask_from_input_mask(from_tensor, to_mask):
"""Create 3D attention mask from a 2D tensor mask.
Args:
from_tensor: 2D or 3D Tensor of shape [batch_size, from_seq_length, ...].
to_mask: int32 Tensor of shape [batch_size, to_seq_length].
Returns:
float Tensor of shape [batch_size, from_seq_length, to_seq_length].
"""
# from_shape = [batch_size, max_seq_length]
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
batch_size = from_shape[0]
from_seq_length = from_shape[1]
# input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
to_shape = get_shape_list(to_mask, expected_rank=2)
to_seq_length = to_shape[1]
to_mask = tf.cast(
tf.reshape(to_mask, [batch_size, 1, to_seq_length]), tf.float32)
# We don't assume that `from_tensor` is a mask (although it could be). We
# don't actually care if we attend *from* padding tokens (only *to* padding)
# tokens so we create a tensor of all ones.
# `broadcast_ones` = [batch_size, from_seq_length, 1]
broadcast_ones = tf.ones(
shape=[batch_size, from_seq_length, 1], dtype=tf.float32)
# Here we broadcast along two dimensions to create the mask.
mask = broadcast_ones * to_mask
return mask
六. transformer_model()层
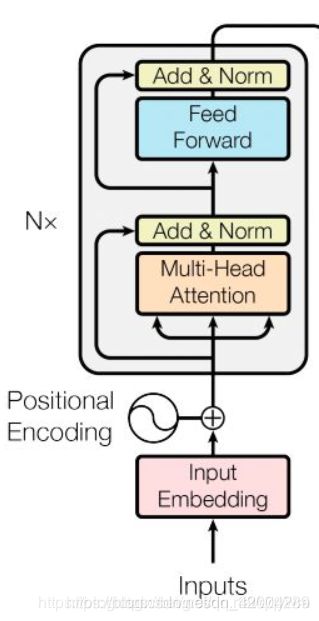
输入数据,进入这个transformer encode模型,走12遍
首先对embedding进行multi-head attention,对输入进行残差和layer_norm。后传入feed forward,再进行残差和layer_norm。
本块代码中与原论文中不一样的地方为:在进行multi-head attention后先链接了一个全连接层,再进行的残差和layer_norm。而原论文中貌似没有那个全连接层。下面也说明只有encoder部分
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
"""Multi-headed, multi-layer Transformer from "Attention is All You Need".
This is almost an exact implementation of the original Transformer encoder.
See the original paper:
https://arxiv.org/abs/1706.03762
Also see:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Args:
input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size].
attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length,
seq_length], with 1 for positions that can be attended to and 0 in
positions that should not be.
hidden_size: int. Hidden size of the Transformer.
num_hidden_layers: int. Number of layers (blocks) in the Transformer.
num_attention_heads: int. Number of attention heads in the Transformer.
intermediate_size: int. The size of the "intermediate" (a.k.a., feed
forward) layer.
intermediate_act_fn: function. The non-linear activation function to apply
to the output of the intermediate/feed-forward layer.
hidden_dropout_prob: float. Dropout probability for the hidden layers.
attention_probs_dropout_prob: float. Dropout probability of the attention
probabilities.
initializer_range: float. Range of the initializer (stddev of truncated
normal).
do_return_all_layers: Whether to also return all layers or just the final
layer.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size], the final
hidden layer of the Transformer.
Raises:
ValueError: A Tensor shape or parameter is invalid.
"""
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads)
# input_tensor=[batch_size, max_seq_length, embedding_size].
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# The Transformer performs sum residuals on all layers so the input needs
# to be the same as the hidden size.
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and
# forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on
# the GPU/CPU but may not be free on the TPU, so we want to minimize them to
# help the optimizer.
# prev_output = [batch_size*max_seq_length, embedding_dim]
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
with tf.variable_scope("attention"):
attention_heads = []
with tf.variable_scope("self"):
# attention_head = [batch_size * from_seq_length, num_attention_heads * size_per_head]
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1)
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input)
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
六.self_attention自注意力机制

首先将输入的key和value,reshape成[batch_size,num_head,seq_length,size_per_head]。在对这些head进行乘法注意力运算。经过softmax后乘以value。最后返回tensor with shape [batch_size*seq_length,hidden_size]
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
This is an implementation of multi-headed attention based on "Attention
is all you Need". If `from_tensor` and `to_tensor` are the same, then
this is self-attention. Each timestep in `from_tensor` attends to the
corresponding sequence in `to_tensor`, and returns a fixed-with vector.
This function first projects `from_tensor` into a "query" tensor and
`to_tensor` into "key" and "value" tensors. These are (effectively) a list
of tensors of length `num_attention_heads`, where each tensor is of shape
[batch_size, seq_length, size_per_head].
Then, the query and key tensors are dot-producted and scaled. These are
softmaxed to obtain attention probabilities. The value tensors are then
interpolated by these probabilities, then concatenated back to a single
tensor and returned.
In practice, the multi-headed attention are done with transposes and
reshapes rather than actual separate tensors.
Args:
from_tensor: float Tensor of shape [batch_size, from_seq_length,
from_width].
to_tensor: float Tensor of shape [batch_size, to_seq_length, to_width].
attention_mask: (optional) int32 Tensor of shape [batch_size,
from_seq_length, to_seq_length]. The values should be 1 or 0. The
attention scores will effectively be set to -infinity for any positions in
the mask that are 0, and will be unchanged for positions that are 1.
num_attention_heads: int. Number of attention heads.
size_per_head: int. Size of each attention head.
query_act: (optional) Activation function for the query transform.
key_act: (optional) Activation function for the key transform.
value_act: (optional) Activation function for the value transform.
attention_probs_dropout_prob: (optional) float. Dropout probability of the
attention probabilities.
initializer_range: float. Range of the weight initializer.
do_return_2d_tensor: bool. If True, the output will be of shape [batch_size
* from_seq_length, num_attention_heads * size_per_head]. If False, the
output will be of shape [batch_size, from_seq_length, num_attention_heads
* size_per_head].
batch_size: (Optional) int. If the input is 2D, this might be the batch size
of the 3D version of the `from_tensor` and `to_tensor`.
from_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `from_tensor`.
to_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `to_tensor`.
Returns:
float Tensor of shape [batch_size, from_seq_length,
num_attention_heads * size_per_head]. (If `do_return_2d_tensor` is
true, this will be of shape [batch_size * from_seq_length,
num_attention_heads * size_per_head]).
Raises:
ValueError: Any of the arguments or tensor shapes are invalid.
"""
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
# width = 768/12 每一个头的维度
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
# from_tensor = to_tensor = [batch_size * max_seq_length, embedding_dim]
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# Scalar dimensions referenced here:
# B = batch size (number of sequences)
# F = `from_tensor` sequence length
# T = `to_tensor` sequence length
# N = `num_attention_heads`
# H = `size_per_head`
from_tensor_2d = reshape_to_matrix(from_tensor)
to_tensor_2d = reshape_to_matrix(to_tensor)
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# `query_layer` = [B, N, F, H]
# query_layer = [batch_size, num_attention_heads, seq_length, width = 768/12]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# `key_layer` = [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# Take the dot product between "query" and "key" to get the raw
# attention scores.
# `attention_scores` = [B, N, F, T]
# 这个是矩阵相乘
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
# 两个元素级别的相乘,不是矩阵相乘
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T] # 值为1
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# 不需要掩盖的词是 0,需要掩盖的是 -10000
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_scores += adder
# Normalize the attention scores to probabilities.
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer