回归模型的score得分为负_如何评价模型的好坏?

学习目标:
数据拆分:训练数据集&测试数据集
评价分类结果:精准度、混淆矩阵、精准率、召回率、F1 Score、ROC曲线,AUC值等
评价回归结果:MSE、RMSE、MAE、R Squared,调整 R Squared
OX00 训练&测试数据集
我们已经兴致勃勃的训练好了一个模型了,问题是:它能直接拿到生产环境正确使用么?
- 我们现在只是能拿到一个预测结果,还不知道这个模型效果怎么样?
预测的结果准不准 - 如果拿到真实环境,其实是没有label的,我们怎么对结果进行验证呢?
实际上,从训练好模型到真实使用,还差着远呢。我们要做的第一步就是:
将原始数据中的一部分作为训练数据、另一部分作为测试数据。使用训练数据训练模型,再用测试数据看好坏。即通过测试数据判断模型好坏,然后再不断对模型进行修改。
具体代码实现参考附录1;
OX01 评价分类结果
混淆矩阵:
对于二分类问题来说,所有的问题被分为0和1两类,混淆矩阵是2*2的矩阵:

- TN:真实值是0,预测值也是0,即我们预测是negative,预测正确了。
- FP:真实值是0,预测值是1,即我们预测是positive,但是预测错误了。
- FN:真实值是1,预测值是0,即我们预测是negative,但预测错误了。
- TP:真实值是1,预测值是1,即我们预测是positive,预测正确了。
accuracy_score=(TP+TN)/(TP+TN+FP+FN):函数计算分类准确率,返回被正确分类的样本比例(default)或者是数量(normalize=False)。
在多标签分类问题中,该函数返回子集的准确率,对于一个给定的多标签样本,如果预测得到的标签集合与该样本真正的标签集合严格吻合,则subset accuracy =1.0否则是0.0。
精准率(查准率)和召回率(查全率)等指标对衡量机器学习的模型性能在某些场合下要比accuracy更好。

查准率(精度):Precision=TP/(TP+FP)。即精准率为8/(8+12)=40%。所谓的精准率是:分母为所有预测为1的个数,分子是其中预测对了的个数,即预测为正的样本中,实际为正的比例。
为什么管它叫精准率呢?在有偏的数据中,我们 通常更关注值为1的特征,比如“患病”,比如“有风险”。在100次结果为患病的预测,平均有40次预测是对的。即 精准率为我们关注的那个事件,预测的有多准。
召回率:Recall=TP/(TP+FN)。即精准率为8/(8+2)=80%。所谓召回率是:所有真实值为1的数据中,预测对了的个数。每当有100个癌症患者,算法可以成功的预测出8个 。也就是我们关注的那个事件真实的发生情况下,我们成功预测的比例是多少。
具体代码实现参考附录2
思考:
1、是否只关注accuracy?
虽然准确率可以判断总的正确率,但是如果存在样本不均衡的情况下,就不能使用accuracy来进行衡量了。比如,一个总样本中,正样本占90%,负样本占10%,那么只需要将所有样本预测为正,就可以拿到90%的准确率,而这显然是无意义的。正因为如此,我们就需要精准率和召回率了。
2、那么精准率和召回率这两个指标如何解读?如果对于一个模型来说,两个指标一个低一个高该如何取舍呢?
精准率的应用场景:预测癌症。医生预测为癌症,患者确实患癌症的比例。
召回率的应用场景:网贷违约率,相对好用户,我们更关心坏用户。召回率越高,代表实际坏用户中被预测出来的概率越高。
至于两个指标如何使用,需要看具体场景,实际上这两个指标是互斥的,一个高,必有另一个低。接下来的分享或许可以解决这个坑。
F1 score=2P*R/(P+R)。P为查准率,R为查全率。F1score就是在查准率与查全率之间寻找一个平衡点。
ROC曲线:横轴假正率(FP率),纵轴为真正率(TP率)。
再次把混淆矩阵拿出来,
TP率=召回率=灵敏度=TP/(TP+FN)
FP率=FP/(FP+TN)
TP率与FP率分别从实际正样本,实际负样本的角度出发来观察概率问题,这样就可以解决样本不均衡问题了。比如,一个90%正样本的总样本中,只用准确率度量是没有意义的。但如果引入TP率,就只关注90%的正样本,引入FP率就只关注10%的负样本,如此一来,正负样本不均衡的问题就可以得到解决了。
ROC曲线是通过遍历所有阈值来描述整条曲线的。如果我们不断遍历所有阈值,预测的正样本与负样本数就在不断变化,相应的就会在ROC曲线移动。注意,此时ROC曲线本身的形状不会变化。
思考:
改变阈值并不会影响ROC曲线本身,那么如何判断ROC曲线的好坏?
重新回归到曲线本身,横轴是假正率,纵轴是真正率,我们希望在FP率低的情况下,TP率高。也就是说,ROC曲越陡越好!
AUC值:ROC曲线与横轴之间围的面积。
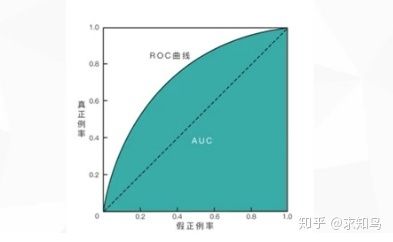
那么如何通过AUC值来判断模型的好坏了?

F1score,ROC曲线,AUC值具体参考附录3
OX02 线性回归的评价指标
2.1 均方误差MSE
测试集中的数据量m不同,因为有累加操作,所以随着数据的增加 ,误差会逐渐积累;因此衡量标准和m相关。为了抵消掉数据量的形象,可以除去数据量,抵消误差。通过这种处理方式得到的结果叫做均方误差MSE(Mean Squared Error):
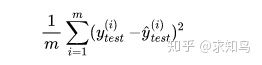
2.2 均方根误差RMSE
但是使用均方误差MSE收到量纲的影响。例如在衡量房产时,y的单位是(万元),那么衡量标准得到的结果是(万元平方)。为了解决量纲的问题,可以将其开方(为了解决方差的量纲问题,将其开方得到平方差)得到均方根误差RMSE(Root Mean Squarde Error):
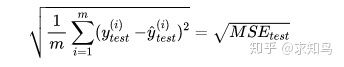
2.3 平均绝对误差MAE
对于线性回归算法还有另外一种非常朴素评测标准。要求真实值 与 预测结果 之间的距离最小,可以直接相减做绝对值,加m次再除以m,即可求出平均距离,被称作平均绝对误差MAE(Mean Absolute Error):
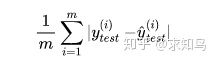
参考附录4
2.4 R square
我们在介绍分类模型评价指标时,依赖于分类准确率(=(TP+TN)/(TP+TN+FP+FN) ),该指标是没有单位的,因此便于不同模型之间进行比较。在统计学中,标准差,协方差有量纲,变异系数,相关系数无量纲。
思考:
回归分析依赖于最小误差平方和来让预测结果得到收敛,所以不能用分类准确率来评价回归结果。RMSE,MAE等指标皆有量纲,那么回归分析的无量纲评价指标是?
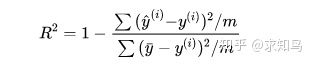
此时分子分母同时除以m,我们会发现,分子就是之前介绍过的均方误差,分母实际上是y这组数据对应的方差:
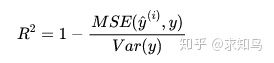
如此,R square 便是无量纲的评价指标。
思考:
R square 为啥好了?
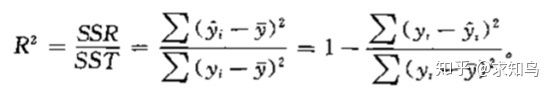
SST 总平方和=SSR 回归平方和+SSE 残差平方和。那么,回归平方和越大,或残差平方和越小,回归预测效果就越好。也就是说,R square 在【0,1】之间,越趋向1越好。
思考:
R square 是不是越大越好?
事实上,新增加一个变量,
2.5 调整 R square

由此可见,R方总是小于调整R方的且调整R方可能为负;并且只有R方趋近1时,调整R方才有出马的意义!
参考附录5
附录
1、网页链接
2、网页链接
3、路远:【机器学习笔记】:一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC
4、模型之母:线性回归的评价指标
5、求知鸟:关于统计学的思考(2)
最后,欢迎关注我的“数据分析”专栏,目前已经超过1200+好友关注啦。
数据分析zhuanlan.zhihu.com