yolov3总结
这个文章写的不错

BBOX和Anchor box
先解释之前云里雾里的锚框:
首先,YOLOV3得到了三个特征图的输出:

网络输出的是tx,ty,tw,th,to 注意,这里得到的tx,ty,tw,th并不是真实的边界框的中心和宽高,而是特征图中的参数量。再通过下面的转换公式转换得到。**Cx,Cy是feature map中grid cell的左上角坐标,在yolov3中每个grid cell在feature map中的宽和高均为1。**如下图的情形时,这个bbox边界框的中心属于第二行第二列的grid cell,它的左上角坐标为(1,1),故Cx=1,Cy=1.tx 和 ty是相对于 格子左上角的偏移量,并且偏移量在0~1之间,因为格子的大小是1.—偏移之后就得到物体的中心。 tw和th是尺度的变换量。
Pw、Ph是预设的anchor box映射到feature map中的宽和高(anchor box原本设定是相对于416*416坐标系下的坐标,在yolov3.cfg文件中写明了,代码中是把cfg中读取的坐标除以stride如32映射到feature map坐标系中)。三种特征图都分别对应了三种anchor box。



anchor box 指的是先验框,作用是直接给后面的预测提供一个先验框的尺寸,而不像V1一样直接预测。直接给定一组框的尺寸作为备选比网络自己学习得到更好。
anchor box来源于训练集,通过对训练集采用K-means聚类,来得到九个先验框(3*3)。为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。小特征图主要还是语义信息,用大的先验框,较大的特征图用较小的先验框,适合检测较小的对象。。
![]()
这点与v2基本接近。
COCO上得到的九个先验框:

三种特征图,越深越后的特征图肯定是越小的。因为小目标物体肯定是随着卷积的增加,信息逐渐丢失,所以大特征图上检测小物体,anchor box选择的也是小的(小物体自然选小的)。
三种特征图 5252, 2626, 13*13其实映射回去就得到了许多边界框,那么使用NMS。NMS讲白了就是把最好的(与真实框的IOU最大的)挑出来,然后与最好的有关系(IOU大于阈值的进行剔除),剩下的就是有效的预测信息。
创新点:
1.加入先验框,通过在训练集中K-means聚类得到九个先验框的尺寸。
2.多尺度,采用金字塔网络FPN 上采样 和 融合 的思想,在三个不同尺度的特征层有相对应的输出。
3.使用逻辑回归替代softmax作为分类器,实现多标签分类。
4.Darknet-53, 加入了跳跃连接的思想,使用降采样代替池化,提高了精度和速度。
 上采样与特征融合
上采样与特征融合

共有13×13×3+ 26× 26×3 + 52 ×52 × 3个预测 。每个预测对应85维,分别是4(坐标值)、1(置信度分数)、80(coco类别数)。
输出的tensor是NN(3*4(4+1+80))。 N指的是最后特征图的大小。

结构
Yolo_v3使用了darknet-53的前面的52层(没有全连接层),yolo_v3这个网络是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了POOLing,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。
/2指的是stride为2。


基本思想
通过特征提取网络对输入的图像提取特征,得到一定大小的feature map 比如 13X13,然后将输入的图像分为13X13个grid cell,然后如果groundtruth中的某个物体的中心坐标落到那个grid cell中就由该grid cell预测该物体,每个grid cell 都会预测固定数量的bounding box (v1 :2个,V2 :5个,V3 : 3个)这几个bounding box的初始size是不一样的),最终,这几个bounding box中只有和ground truth的IOU最大的bounding box才是用来预测该物体。
为了加强算法对小目标检测的精确度,YOLO v3中采用类似FPN的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测。

深层的主要代表语义信息,浅层的是代表图像的特征。
使用up-sample(上采样)的原因:网络越深的特征表达效果越好,比如在进行16倍降采样检测,如果直接使用第四次下采样的特征来检测,这样就使用了浅层特征,这样效果一般并不好。如果想使用32倍降采样后的特征,但深层特征的大小太小,因此yolo_v3使用了步长为2的up-sample(上采样),把32倍降采样得到的feature
map的大小提升一倍,也就成了16倍降采样后的维度。同理8倍采样也是对16倍降采样的特征进行步长为2的上采样,这样就可以使用深层特征进行detection。
后面上采样之后进行融合之前,为了保持channel的一致,还需要经过一系列的11和33的卷积操作,来提高非线性程度增加泛化性能提高网络精度,又能减少参数提高实时性。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
逻辑回归
逻辑回归虽写着回归,其实是分类
其实就是sigmoid函数。用于对anchor包围的部分进行一个目标性评分(objectnessscore),(用于NMS),即这块位置是目标的可能性有多大。
逻辑回归代替softmax进行分类,作用是多标签分类。这样就可以实现一个实体有多个标签可以表示。支持多标签对象(比如一个人有Woman和Person两个标签)。
YOLO v3使用逻辑回归预测每个边界框的分数。 如果先验边界框与真实框的重叠度比之前的任何其他边界框都要好,则该值应该为1。 如果先验边界框不是最好的,但确实与真实对象的重叠超过某个阈值(这里是0.5),那么就忽略这次预测。YOLO v3只为每个真实对象分配一个边界框,如果先验边界框与真实对象不吻合,则不会产生坐标或类别预测损失,只会产生物体预测损失。
yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模。
K-means聚类
!!K-means中的距离的度量是采用IOU来决定的,不是往常的欧式距离
1.使用的聚类原始数据是只有标注框的检测数据集,YOLOv2、v3都会生成一个包含标注框位置和类别的TXT文件,其中每行都包含![]() ,即ground truth boxes相对于原图的坐标,
,即ground truth boxes相对于原图的坐标,![]() 是框的中心点,
是框的中心点,![]() 是框的宽和高,N是所有标注框的个数;
是框的宽和高,N是所有标注框的个数;
2.首先给定k个聚类中心点,这里的是anchor boxes的宽和高尺寸,由于anchor boxes位置不固定,所以没有(x,y)的坐标,只有宽和高;
3.计算每个标注框和每个聚类中心点的距离 d=1-IOU(标注框,聚类中心),计算时每个标注框的中心点都与聚类中心重合,这样才能计算IOU值,即。将标注框分配给“距离”最近的聚类中心;
4.所有标注框分配完毕以后,对每个簇重新计算聚类中心点,计算方式为,是第i个簇的标注框个数,就是求该簇中所有标注框的宽和高的平均值。
5.重复第3、4步,直到聚类中心改变量很小。
预测的输出
v3输出的tensor是NN(34(4+1+80))。 N指的是最后特征图的大小。
v1输出的tensor是NN*(B*5+80),一个单元格只预测一个类别。
一个框输出仍然是5个坐标信息加分类信息: tx,ty,tw,th,pc,C=…
这里与v1有所不同,v1的tx和ty就是中心点的位置。而v3是相对于左上角的距离。 并且,v3的tw和th是相对于先验框的比值,不是基于整幅图像。
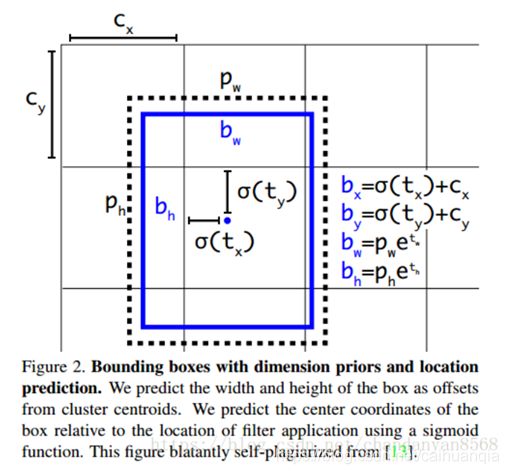
上面的pw和ph是先验框的尺寸,所以预测的tensor只是预测了相对于先验框的比值。Cx,Cy是相对于左上角的偏移量。
使用 sigmoid 函数进行中心坐标预测。这使得输出值在 0 和 1 之间。正常情况下,YOLO 不会预测边界框中心的确切坐标。它预测的是:与预测目标的网格单元左上角相关的偏移;并且使用feature map中的cell大小进行归一化。
LOSS
所以使用锚框之后的损失就直接是锚框相对应的预测值
框中心相对于左上角的距离于真实框相对于左上角的距离的loss,以及宽高比值的loss

结果
Amazing

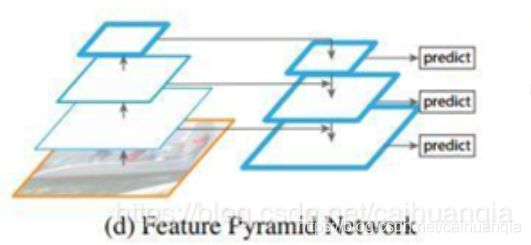
FPN的思路
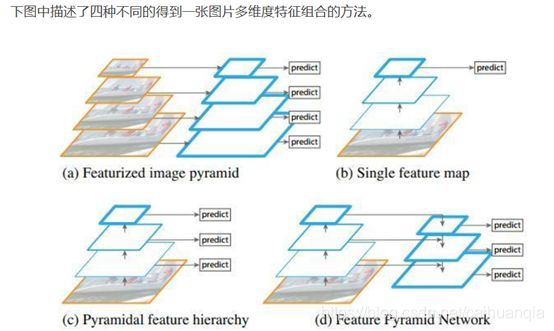
上图(a)中的方法即为常规的生成一张图片的多维度特征组合的经典方法。即对某一输入图片我们通过压缩或放大从而形成不同维度的图片作为模型输入,使用同一模型对这些不同维度的图片分别处理后,最终再将这些分别得到的特征(feature maps)组合起来就得到了我们想要的可反映多维度信息的特征集。此种方法缺点在于需要对同一图片在更改维度后输入处理多次,因此对计算机的算力及内存大小都有较高要求。
图(b)中的方法则只拿单一维度的图片做为输入,然后经CNN模型处理后,拿最终一层的feature maps作为最终的特征集。显然此种方法只能得到单一维度的信息。优点是计算简单,对计算机算力及内存大小都无过高需求。此方法为大多数R-CNN系列目标检测方法所用像R-CNN/Fast-RCNN/Faster-RCNN等。因此最终这些模型对小维度的目标检测性能不是很好。
图©中的方法同样是拿单一维度的图片做为输入,不过最终选取用于接下来分类或检测任务时的特征组合时,此方法不只选用了最后一层的high level feature maps,同样也会选用稍靠下的反映图片low level 信息的feature maps。然后将这些不同层次(反映不同level的图片信息)的特征简单合并起来(一般为concat处理),用于最终的特征组合输出。此方法可见于SSD当中。不过SSD在选取层特征时都选用了较高层次的网络。比如在它以VGG16作为主干网络的检测模型里面所选用的最低的Convolution的层为Conv4,这样一些具有更低级别信息的层特征像Conv2/Conv3就被它给漏掉了,于是它对更小维度的目标检测效果就不大好。
图(d)中的方法同图©中的方法有些类似,也是拿单一维度的图片作为输入,然后它会选取所有层的特征来处理然后再联合起来做为最终的特征输出组合。(作者在论文中拿Resnet为实例时并没选用Conv1层,那是为了算力及内存上的考虑,毕竟Conv1层的size还是比较大的,所包含的特征跟直接的图片像素信息也过于接近)。另外还对这些反映不同级别图片信息的各层自上向下进行了再处理以能更好地组合从而形成较好的特征表达, 而此方法正是我们本文中要讲的FPN CNN特征提取方法。
——————做法:上采样和融合
实战链接:
https://blog.paperspace.com/tag/series-yolo/
参考:
https://blog.csdn.net/yanzi6969/article/details/80505421
https://blog.csdn.net/kun_csdn/article/details/88876524
https://www.cnblogs.com/ywheunji/p/10809695.html