全球人工智能技术创新大赛【热身赛一】布匹疵点智能识别 笔记
主要代码参考了https://github.com/datawhalechina/team-learning-cv/tree/master/DefectDetection的baseline,使用的YOLOv5系列模型,关于源码的注释在YOLOV5训练代码train.py注释与解析
记录一下遇到的问题:
1、数据预处理问题
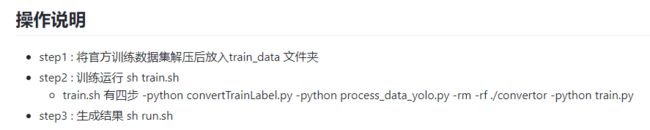
train.sh文件中,第二步使用了process_data_yolo.py,源码中关于数据集存放位置存在问题,只写了val的处理,没写train的处理,所以生成的process_data文件夹中, 只有val而没有train,训练时会报错。
所以不能直接用train.sh脚本,要顺序运行里面的命令,到第二步的时候,先执行一遍,如下图做修改后再执行一遍,从而把训练集和验证集都准备好。
2、 预训练权重问题
使用如下命令训练
python train.py --weights weights/yolov5x.pt --cfg models/yolov5x.yaml --batch-size 3
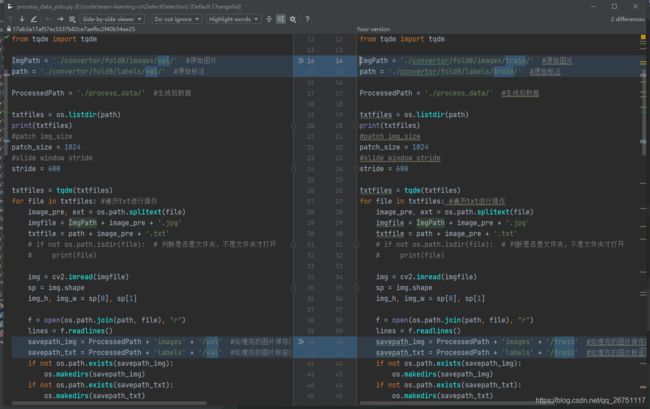
加载YOLOv5的官方预训练权重,结果报错
KeyError: "weights/yolov5m.pt is not compatible with models/yolov5m.yaml. This may be due to model differences or weights/yolov5x.pt may be out of date. Please delete or update weights/yolov5x.pt and try again, or use --weights '' to train from scratch."谷歌后找到的官方源码的issue,https://github.com/ultralytics/yolov5/issues/222#issuecomment-650999053
在源码的120行做如下修改,就能正常加载权重了。
3、docker构建
3.1 本地训练
首先在本地训练几个epoch,生成best.pt权重文件,训练的方式随便,Windows环境、Linux环境、docker训练都可以。然后使用把用得上的文件拷贝到要构建docker的文件夹中。
但要注意docker教程中拉取的Pytorch镜像为1.4版本(registry.cn-shanghai.aliyuncs.com/tcc-public/pytorch:1.4-cuda10.1-py3),我们现在常用的pytorch环境为1.7,在保存权重的时候会使用新版本的序列化方式,导致docker测试时权重读取序列化失败,所以新建个Python脚本,把best.pt重新保存下。
ckpt = torch.load('best.pt', map_location=device) # 读取best.pt权重
torch.save(ckpt, 'new.pt', _use_new_zipfile_serialization=False) # 使用旧的方式保存3.2 构建docker
baseline的源码中,run.sh中为空,改为
python detect.py --source ./tcdata/guangdong1_round2_testB_20191024
然后使用 docker build 命令构建镜像。
通过 docker run 进入容器。
注意点:
根据https://github.com/datawhalechina/team-learning-cv/blob/master/DefectDetection/docker%E6%8F%90%E4%BA%A4%E6%95%99%E7%A8%8B.pdf构建完镜像后,
进入容器后安装额外依赖
pip install opencv-python
pip install matplotlib
pip install scipy
注意安装完后检查opencv能否正常运行,直接在终端打开Python,然后 import cv2,如果报错的话,
# 解决方法:
apt update
apt install libgl1-mesa-glx
apt-get install -y libglib2.0-0注意此时不要关闭容器,因为如果关掉的话,刚才安装的依赖不会被更新到刚才的镜像中!
要想使镜像也实现这些改动,需要把当前容器另存为一个新的镜像。

所以教程里让退出但不关闭容器。
使用 docker commit 将当前容器提交为镜像,然后使用 docker images 列出所有镜像,最新的一条就是刚才另存为的新镜像,可以看到imageID和刚才构建出的那个镜像是不同的。
然后就可以
docker run your_image(自己替换) sh run.sh运行自己的镜像,看是否报错,因为现在目录里没有tcdata这个测试文件夹,如果报文件相关的错误就是正常的,或者可以自己建个文件夹试一下。
过程中,如果报错的话,一般就是run.sh有问题,可以在容器内修改完再另存为镜像一次(同上),这样比较省时间。或者参考修改已有docker容器中的内容,操作规范一些。
4 推送镜像
直接 docker push 到自己的镜像仓库。
由于我是训练完构建的镜像,基础环境加上权重,镜像一共9.44G,非常大,推送很慢,估计在600k左右,过程中如果因为网络问题想中断重试的话,可以Ctrl+C打断,已经推送成功的layer会保存,不需要重新传(不知道保存多久),但是传到一半的会重新开始,要注意。
5 提交
这里注意账号密码不要填错,我一开始填错了密码,导出出现了 ImagePullBackOff 错误。
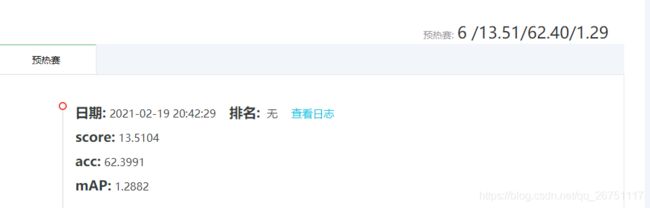
训练了50个epoch的结果如下,确实挺差的。。。
6 更新
多训练几个epoch后,生成新的权重文件best.pt,使用docker cp命令将其拷贝到容器中,然后docker commit保存为新的镜像,重新docker push
可以看到只需要重新上传权重文件就可以了,其他层都已存在,比第一次上传9个G快很多