12_spark_core_累加器_自定义累加器
12_spark_core_累加器_自定义累加器
- 自定义累加器
- 总结
自定义累加器
自定义累加器类型的功能在1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。
1)自定义累加器步骤
(1)继承AccumulatorV2,设定输入、输出泛型
(2)重写6个抽象方法
(3)使用自定义累加器需要注册::sc.register(累加器,“累加器名字”)
2)需求:自定义累加器,统计RDD中首字母为“H”的单词以及出现的次数。
List(“Hello”, “Hello”, “Hello”, “Hello”, “Hello”, “Spark”, “Spark”)
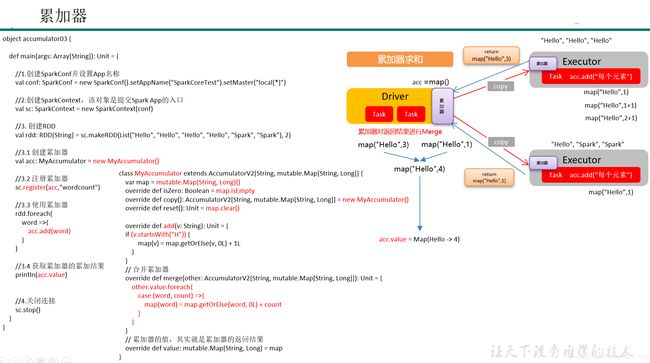
3)代码实现
package com.atguigu.accumulator
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{
SparkConf, SparkContext}
import scala.collection.mutable
/**
* @author dxy
* @date 2021/2/24 16:00
*/
/**
* 需求:自定义累加器,统计RDD中首字母为“H”的单词以及出现的次数。
*/
object accumulator03_define {
def main(args: Array[String]): Unit = {
//TODO 1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//TODO 2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//1.创建RDD
val rdd: RDD[String] = sc.makeRDD(List("Hello", "Hello", "Hello", "Hello", "Spark", "Spark"), 2)
//1.1创建累加器
val myAcc = new MyAccumulator
//1.2注册累加器
sc.register(myAcc,"acc")
//1.3使用累加器
rdd.foreach(
word=>myAcc.add(word)
)
//1.4获取累加器的累加结果
val accMap: mutable.Map[String, Long] = myAcc.value
println(accMap)
//TODO 3.关闭连接
sc.stop()
}
}
/**
* 自定义累加器步骤
* 1.继承AccumulatorV2,并且制定输入输出泛型
* 输入 String hello
* 输出 可变Map (hello,1)
*
* 2.实现6个抽象方法
*/
class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]] {
//0.将最终要输出的map提前创建出来
var map: mutable.Map[String, Long] = mutable.Map[String,Long]()
//判断累加器是否初始化的方法
override def isZero: Boolean = map.isEmpty
//累加器复制方法
override def copy(): AccumulatorV2[String, mutable.Map[String,Long]] = new MyAccumulator
//累加器重置方法
override def reset(): Unit = map.clear()
//累加器在分区内,(单个executor内)的聚合方法 map + hello
override def add(word: String): Unit = {
if (word.startsWith("H")){
map(word) = map.getOrElse(word,0L)+1
}
}
//多个累加器在driver端的聚合方法
override def merge(other: AccumulatorV2[String, mutable.Map[String,Long]]): Unit = {
//1.先获取传进来的这个otherd的累加器的值
val map2: mutable.Map[String, Long] = other.value
map2.foreach{
case (word,cnt)=>{
map(word)=map.getOrElse(word,0L)+cnt
}
}
}
override def value: mutable.Map[String,Long] = map
}
运行结果:
Map(Hello -> 4)
总结
1.为什么要使用自定义累加器?
因为spark自带的累加器不满足我们使用,另外我们想实现一些特殊功能时也需要自定义累加器。
sc.longAccumulator("sum")
点击源码:发现spark自带累加器最终实现AccumulatorV2抽象类,这个抽象父类实现类只有三个CollectionAccumulator、DoubleAccumulator和LongAccumulator
因此不满足我们使用
2.自定义累加器步骤
(1)继承AccumulatorV2,设定输入、输出泛型
(2)重写6个抽象方法
(3)使用自定义累加器需要注册::sc.register(累加器,"累加器名字")
例如:
/**
* 自定义累加器步骤
* 1.继承AccumulatorV2,并且制定输入输出泛型
* 输入 String hello
* 输出 可变Map (hello,1)
*
* 2.实现6个抽象方法
*/
class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]] {
//0.将最终要输出的map提前创建出来
var map: mutable.Map[String, Long] = mutable.Map[String,Long]()
//判断累加器是否初始化的方法
override def isZero: Boolean = map.isEmpty
//累加器复制方法
override def copy(): AccumulatorV2[String, mutable.Map[String,Long]] = new MyAccumulator
//累加器重置方法
override def reset(): Unit = map.clear()
//累加器在分区内,(单个executor内)的聚合方法 map + hello
override def add(word: String): Unit = {
if (word.startsWith("H")){
map(word) = map.getOrElse(word,0L)+1
}
}
//多个累加器在driver端的聚合方法
override def merge(other: AccumulatorV2[String, mutable.Map[String,Long]]): Unit = {
//1.先获取传进来的这个otherd的累加器的值
val map2: mutable.Map[String, Long] = other.value
map2.foreach{
case (word,cnt)=>{
map(word)=map.getOrElse(word,0L)+cnt
}
}
}
override def value: mutable.Map[String,Long] = map
}
map(word)=map.getOrElse(word,0L)+cnt这段代码是scala中知识,比如这题,就是对相同单词次数判断,有+已经存在单词次数,没有就+1,因为遍历到一个
map(word)其实就是拿到对应V的值
今后可以模仿这种方式写
在自定义中,最重要是要明确输入和输出泛型
3.怎样使用自定义累加器
(1)创建自定义累加器
(2)注册累加器--源码也是这种方式把自定义累加器注册一下
(3)使用自定义累加器
(4)获取自定义累加器结果
这里跟spark自带累加器原理类似
注意!!!!!!!!!!!!!!!!!
使用累加器最好要在行动算子中使用,因为行动算子只会执行一次,而转换算子的执行次数不确定!