dataframe 提取月数据_pandas数据分析入门
知识点概述


数据分析基础
一维数据结构
导入numpy、pandas

- numpy
使用numpy定义一个一维数组

查询元素
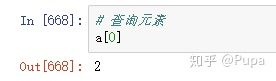
array类型的数据可以使用类似列表的切片形式查看数据

可以使用for循环来逐个查询元素

通过dtype可以查看数组中元素的类型

数组中的元素可以进行统计计算如平均值、标准差等

数组中的元素是可以进行向量化的计算

- pandas
pandas中的一位数组结构是用Series来实现的

获取数据的描述性统计信息

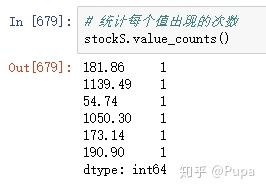
查看Series中每个元素出现的次数
获取Series中的元素,有两种方式

Series的向量化计算

图中的NaN为缺失值,因为s1和s2的索引不同,当进行向量相加时,只有索引相同的项可以相加,索引不同时,使用缺失值,也就是NaN代替。
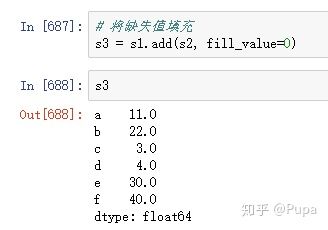
对Series中的缺失值进行处理有两种方式,一种是直接删除;另一种是向量相加时,默认当索引不匹配时,使用0来代替缺失的数据。
直接删除缺失值。

当dropna()的()中没有任何值时,不会替换原数据。

当dropna(inplace=True)时,会替换原数据。

使用函数在向量相加时,用0填充缺失的数据。
二维数据结构
- numpy
numpy中二维数据的获取与一维数据相似。

numpy中的数轴,用axis=1表示横轴,用axis=0表示纵轴。

- pandas
pandas的二维数据结构是用DataFrame来实现的。
定义一个字典,并转化为DataFrame格式。

得到如下形式的数据:

字典是无序的,因此想要让输出的数据能够根据输入是的顺序显示,就需要用到排序字典。

输出的DataFrame的数据顺序与输入时一致。
DataFrame的计算功能。
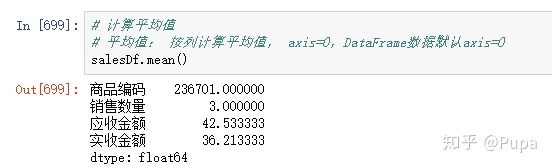
计算平均值
pandas中的数据获取:
pandas中获取数据的形式有两种:一种是通过数据的位置获取数据,使用iloc;
另一种是通过数据的索引获取数据,使用loc
通过数据的位置获取数据,使用iloc。
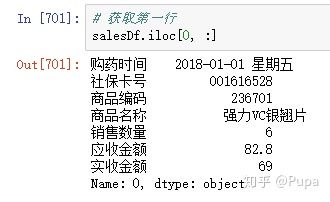
查询某个位置的数据,以查询第1行,第2列的数据为例
因为pandas中的数据索引是以0开始的,因此查询数据的方式如下:

获取第一行的数据:

获取第一列的数据:
获取列的时候还有其他的方式,dataframe的数据可以用columns查看都有哪些行,这些行的名字会以列表的形式返回,因此可以利用这一点,获取某一列的数据:

通过索引获取数据,使用loc。
查询元素:

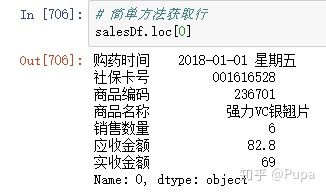
获取第一行:

这里获取行的时候,可以简化代码:
获取第一列:

获取列的时候也有简单的方式:

上面的方法都是获取单行获单列的数据,那么如何获取多行多列的数据?
使用列的名称获取数据:

使用列的索引获取数据:

使用切片的方式获取数据:

注意:如果使用:,就不能将列名放在列表中。

通过条件判断筛选:

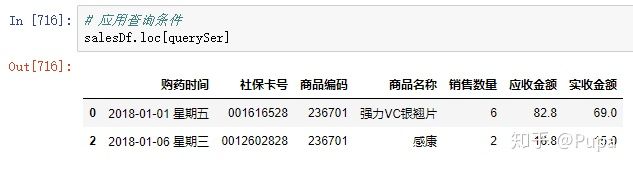
符合条件的数据会显示True,不符合的会显示False
将查询条件应用的dataframe中,可以快速筛选出符合条件的数据。
数据分析步骤
提出问题
月均消费次数是多少?
月均消费金额是多少?
客单价是多少?
理解数据
使用pandas读取excel文件的数据:

查看数据,为了避免数据量大,并且能够快速查看数据的情况,通常使用head()来显示前5行的数据,head()默认显示前5行,也可以在()填写数字,来显示相应的行。

查看数据的类型,明确每个字段:

查看数据有多少行、多少列:

查看每一列的统计数:

数据清洗
选择子集,有的时候因为数据集较大或者有的列是用不到的,此时为了计算方便,可以选择需要的数据进行研究:

列重命名,有的时候列的名字是全英文的或者列名比较不容易理解时,可以将列重命名,方便阅读:

这种情况修改后的列名是不会影响原数据的,

如果想要在原数据的基础上修改,需要用到inplace参数:

缺失值处理,处理数据的时候,经常会遇到缺失值的情况,pandas可以很方便的处理缺失的数据:

其中any表示只要有空值就删除,how也可以使用all参数,当所有的值都是空值的时候才会删除。
数据类型转化,有的时候读取的数据类型并不是我们希望得到的数据类型,因此需要将原数据的类型转换成我们需要的数据类型。
查看数据类型:

修改数据类型:
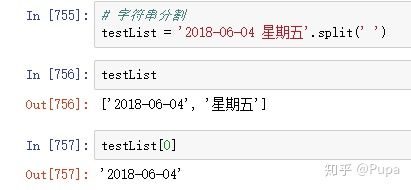
字符串分割,excel表格中的数据有的时候会出现带有-或者,或者空格等的数据,如‘2018-01-01 星期五’、‘11k-20k’等,为了计算方便,需要将这些字符分开,此时就需要用到字符串分割的操作。
首先我们来看下,字符串是如何被分割的。
然后将这种方式运用到Series中的每一个数据上:

获取销售时间列的数据,并将其作为参数传递到函数中,获取处理后的时间数据。

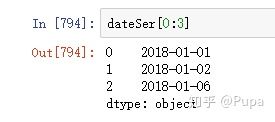
查看结果处理后的时间数据,前3行:
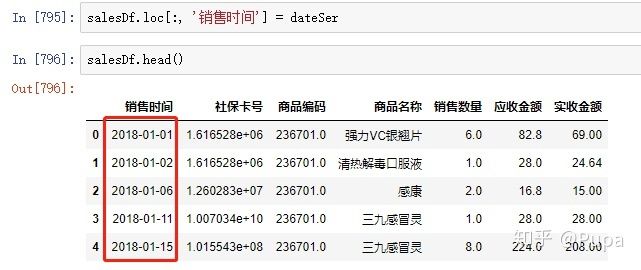
将经过处理后的时间数据,复制给销售时间列,覆盖原来的数据。
其实处理dataframe中的字符串分割问题有更简单的方式:
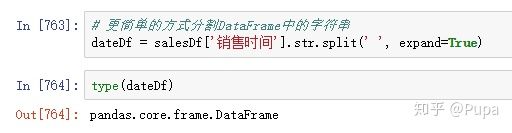
使用这种方式获取的数据是dataframe类型的,其中expand参数表示当数据分割后的形状不规则时,用none来填充数据,我们将dateDf中的数据打印出来:

接下来就可以根据dataframe中的提取数据的方式,将日期提取出来:
前面我们提到过expand参数,如果不使用expand参数,获取的数据是什么样的呢?

不使用expand时,我们获取的数据是一个Series,其中每一行都是一个列表,我们将Series转换成DataFrame格式获取日期数据:

接下来就是获取日期数据了,由于跟前面的方式一致,这里就不在重复操作了。
字符串格式转化为日期格式:

销售时间已经转变为datetime格式了。
其中format表示转换日期的时间,errors表示报错时的处理方式:

查看数据:

前面我们使用的是coerce的格式转换数据,因此当日期数据无效是显示NaT,我们需要将缺失的数据删除。


排序,为了使数据更方便被查看,我们需要将数据进行排序。

其中ascending=True表示升序,ascending=False表示降序,默认是等于false,也就是降序。
排序之后,行的索引被打乱的顺序,因此,需要重新对行的索引设置。

异常值处理:

对数据进行描述性统计时,发现销售数量,应收金额、实收金额等数据存在负值,这明显与实际情况不符,因此需要对这些值进行处理。
通过条件判断筛选中有效的值,并剔除异常值:

计算指标
月均消费次数
删除重复值,数据中销售时间和社保卡号相同的值被视位重复值:

删除重复值后,数据的行数即为总的消费次数:

总消费时间,现将数据按时间顺序升序排列,之后用最后的时间减去最开始的时间即为消费时间,然后除以30天即为总的月份数:

月均消费次数:

月均消费金额

客单价
根据社保卡号确定总的消费人数,首先删除社保卡中的重复值,删除后等到的数据的行数即为总的消费人数:

客单价:
