物体检测和分割轻松上手:从detectron2开始(上篇)
AI编辑:我是小将
物体检测和分割应该算是计算机视觉中常用的而且也比较酷的任务。但相比图像分类,物体检测和分割任务难度更大,另外一点是就是代码实现也更复杂。对于物体检测和分割,目前有以下几个通用的开源项目:
Detectron:FAIR出品,基于caffe2;
maskrcnn-benchmark:FAIR出品,基于PyTorch,可以看成Detectron的PyTorch升级版;
MMDetection:商汤MMLab出品,基于PyTorch,Model zoo相当完备;
SimpleDet:图森出品,基于MxNet;
Tensorflow Object Detection:Google出品,基于TensorFlow 1.x;
每个开源项目都包含了R-CNN系列(Faster R-CNN和Mask R-CNN等)的实现,当然大家都有自己独特的优势,这里不做讨论。今天要介绍的FAIR新出品的detectron2,这个新的项目是maskrcnn-benchmark的替代者,detectron2的优势主要体现在以下三点:
R-CNN系列最强实现,毕竟R-CNN系列大佬在FAIR,另外也支持新的特性,如全景分割(panoptic segmentation)和旋转框(rotated bounding boxes);
高度模块化,扩展性好,具体讲detectron2可以看成一个基础库,当实现新的模型时是去import而不是modify;
训练速度更快(目前mmdetV2.0速度已经和detectron2相当)
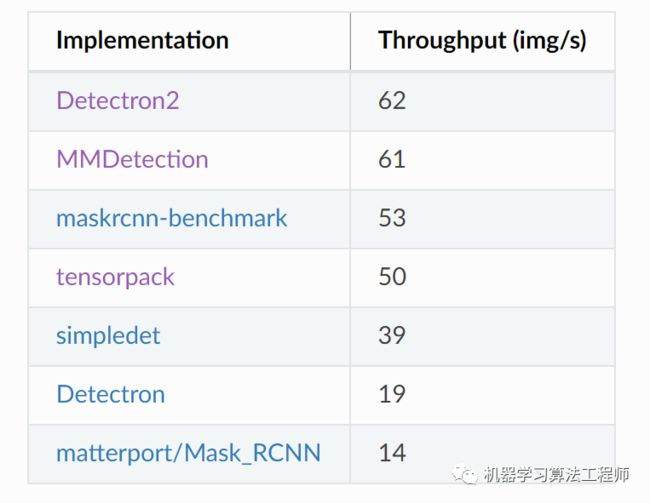
虽然detectron2的model zoo并不如MMDetection,但是这符合detectron2的设计理念,只把最核心和通用的放在框架中,其它的定制化项目只需要依赖它就好,这点可以看一下detectron2下的projects。

这篇文章算是简单的入门介绍,这里会介绍detectron背后的一些主要逻辑,也包括官方的一个实例。文末有QQ交流群,希望共同交流和学习。
detectron2的安装
detectron2的安装是非常简单的,也没有太多坑,直接参考官方安装说明即可。首先安装1.3+版本的PyTorch和对应的torchvision:
pip install -U torch==1.5 torchvision==0.6
然后安装cpython和pycocotools:
pip install cython; pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
然后直接从source安装最新的detectron2就可以,注意需要gcc & g++ >=5:
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
detectron2总览
要整体了解detectron2,可以直接看一下engine里的DefaultTrainer,这里贴一下其核心部分:
model = self.build_model(cfg) # 模型构建
optimizer = self.build_optimizer(cfg, model) # 优化器构建
data_loader = self.build_train_loader(cfg) # 训练dataloader
# For training, wrap with DDP. But don't need this for inference.
if comm.get_world_size() > 1:
model = DistributedDataParallel(
model, device_ids=[comm.get_local_rank()], broadcast_buffers=False
)
super().__init__(model, data_loader, optimizer)
self.scheduler = self.build_lr_scheduler(cfg, optimizer) # 学习速率调度器
# checkpointer,用于模型保存
# Assume no other objects need to be checkpointed.
# We can later make it checkpoint the stateful hooks
self.checkpointer = DetectionCheckpointer(
# Assume you want to save checkpoints together with logs/statistics
model,
cfg.OUTPUT_DIR,
optimizer=optimizer,
scheduler=self.scheduler,
)
self.start_iter = 0
self.max_iter = cfg.SOLVER.MAX_ITER
self.cfg = cfg
# hook注册,hook主要用于实现一些回调,和keras里的callbacks很类似
self.register_hooks(self.build_hooks())
首先说一下detectron2的参数配置是基于yaml和yacs,整个代码中会有一个全局变量cfg,这样的好处是代码比较整洁,而且我们通过配置文件可以很方便地修改所有参数配置。
模型的构建接口就是build_model,这一部分的实现在modeling子模块,在detectron2中,当要加入一个model,就需要注册一个meta_arch(注册指的是在model zoo中加入模型,背后就是维护一个模型字典),比如加入RetinaNet模型:
@META_ARCH_REGISTRY.register()
class RetinaNet(nn.Module):
pass
子模块solver包含了build_optimizer和build_lr_scheduler的实现,目前框架里的optimizer是momentum SGD,而lr调度器有两个:WarmupMultiStepLR和WarmupCosineLR,这是最常用的两种lr调度方式:
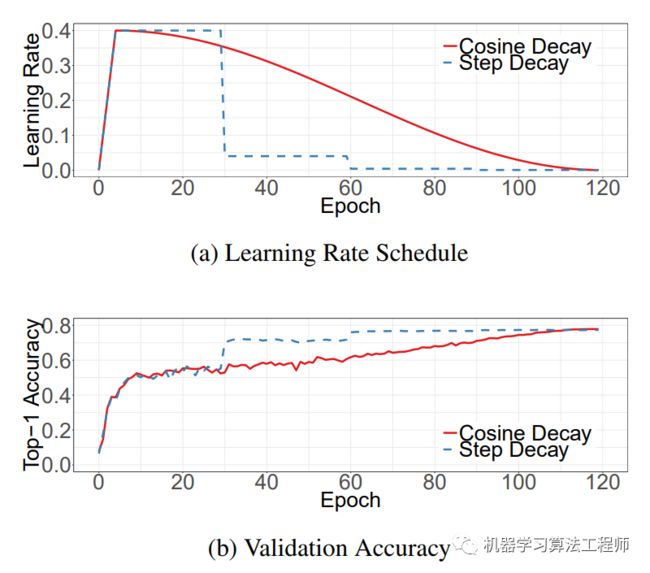
数据集构建以及dataloader的实现包含在data子模块中,这里面也包含了常用的transform。目前detectron2包含了常用的物体检测和分割数据集,如VOC和COCO,下面可以查看支持的数据集:
from detectron2.data import MetadataCatalog
MetadataCatalog.list()
不过想使用这些数据集,还需要下载并按结构要求配置,具体可以参考文档。
detectron2也是采用hook来实现一些训练时的控制逻辑,比如模型保存,学习速率调节;hook和keras的callback很类似。
除了上面这些,detectron2的一个重要子模块是structures子模块,这里面主要包含检测和分割常用的基础结构,如box,instance以及mask等等,这些组件是通用的。
自定义数据集
一个通用的框架必然要支持自定义数据集,在detectron2中你可以很容易新增自己的数据集:只需要按照数据格式提供图片路径以及标注就可以,然后注册数据集的元信息。detectron2通过下面的方式去注册数据集:
def get_dicts():
...
return list[dict]
from detectron2.data import DatasetCatalog
DatasetCatalog.register("my_dataset", get_dicts)
上面一个dict就是一个图像以及标注,要按照标注格式提供,主要包含以下几个字段(详细可参考Standard Dataset Dicts):
file_name:图片所在的绝对路径;
height, width:图片的长和宽;
image_id (str or int):图片唯一id;
annotations (list[dict]):每个dict就是一个instance的标注信息,如box和mask;
对于instance,主要需要包含以下几个字段:
bbox (list[float]):物体标注框,4个浮点数,要不然是xyxy,或是xywh;
bbox_mode (int):bbox的格式,BoxMode.XYXY_ABS或者BoxMode.XYWH_ABS;
category_id (int): 类别标签,在[0, num_categories)范围内的整数,一般情况下detectron2会把num_categories这个数设置为背景类;
segmentation (list[list[float]] or dict):实例分割所需要的mask标注,如果是If list[list[float]], 那就是一系列多边形点集,如果是dict, 那就是COCO's RLE 格式的像素级分割mask;
如果你的数据格式是COCO格式,那么实际上是可以通过detectron2的内置函数快速注册:
from detectron2.data.datasets import register_coco_instances
register_coco_instances("my_dataset_train", {}, "json_annotation_train.json", "path/to/image/dir")
register_coco_instances("my_dataset_val", {}, "json_annotation_val.json", "path/to/image/dir")
当然我们也可以按照上述格式要求自己实现,这里以balloon实例分割数据集为例,这个只有balloon一个类别,具体实现如下:
from detectron2.structures import BoxMode
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x] # 这里分割mask用多边形点集表示
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
"iscrowd": 0
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
from detectron2.data import DatasetCatalog, MetadataCatalog
for d in ["train", "val"]:
# 注册数据集
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
# 数据集添加元信息,主要是类别名,用于可视化
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
# 添加数据集评估指标,采用coco评测准则
MetadataCatalog.get("balloon_" + d).evaluator_type = "coco"
balloon_metadata = MetadataCatalog.get("balloon_train")
这里一共添加了两个数据集:balloon_train和balloon_val,分别用于训练和验证。借助detectron2中的可视化工具,可以可视化数据集中样本:
dataset_dicts = get_balloon_dicts("balloon/train")
for d in random.sample(dataset_dicts, 1):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=balloon_metadata, scale=0.5)
vis = visualizer.draw_dataset_dict(d)
cv2_imshow(vis.get_image()[:, :, ::-1])
自定义Dataloader
一旦添加了数据集,我们可以采用detectron2的默认dataloader来实现数据加载,detectron2.data模块中包含了build_detection_train_loader和build_detection_test_loader两个方法来分别加载训练和测试数据集。下面是构建训练数据的dataloader:
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
from detectron2.data import build_detection_train_loader
cfg = get_cfg()
# 这里用COCO数据集的mask rcnn R50_FPN模型参数
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.DATASETS.TRAIN = ("balloon_train",)
train_loader = build_detection_train_loader(cfg, mapper=None)
## 以下是打印信息,会输出关于数据集的基本统计信息,以及dataloader所采用的数据处理方式以及抽样方法
[04/20 15:26:26 d2.data.build]: Removed 0 images with no usable annotations. 61 images left.
[04/20 15:26:26 d2.data.build]: Distribution of instances among all 1 categories:
| category | #instances |
|:----------:|:-------------|
| balloon | 255 |
| | |
[04/20 15:26:26 d2.data.common]: Serializing 61 elements to byte tensors and concatenating them all ...
[04/20 15:26:26 d2.data.common]: Serialized dataset takes 0.17 MiB
[04/20 15:26:26 d2.data.detection_utils]: TransformGens used in training: [ResizeShortestEdge(short_edge_length=(640, 672, 704, 736, 768, 800), max_size=1333, sample_style='choice'), RandomFlip()]
[04/20 15:26:26 d2.data.build]: Using training sampler TrainingSampler
更进一步地,你可以看一下dataloader加载的batch数据格式:
for batch_data in train_loader:
print(batch_data[0])
break
file_name': 'balloon/train/4543126482_92254ef046_b.jpg', 'image_id': 34, 'height': 1024, 'width': 679, 'image': $tensor, instances': Instances(num_instances=11, image_height=1062, image_width=704, fields=[gt_boxes: Boxes(tensor([[111., 352., 204., 456.], gt_boxes, gt_classes, gt_masks
这个输出格式正是模型输入所要求的格式,后面会细讲。
其实对于dataloader我们更关注的是数据的预处理和数据增强,detectron2在这方面支持性非常好,你只需要自定义DatasetMapper就好,然后送入build_loader的mapper字段,下面是一个mapper例子:
from detectron2.data import build_detection_train_loader
from detectron2.data import transforms as T
from detectron2.data import detection_utils as utils
def mapper(dataset_dict):
# 自定义mapper
dataset_dict = copy.deepcopy(dataset_dict) # 后面要改变这个dict,所以先复制
image = utils.read_image(dataset_dict["file_name"], format="BGR") # 读取图片,numpy array
image, transforms = T.apply_transform_gens([T.Resize((800, 800))], image) # 数组增强
dataset_dict["image"] = torch.as_tensor(image.transpose(2, 0, 1).astype("float32")) # 转成Tensor
annos = [
utils.transform_instance_annotations(obj, transforms, image.shape[:2])
for obj in dataset_dict.pop("annotations")
if obj.get("iscrowd", 0) == 0
] # 数据增强要同步标注
instances = utils.annotations_to_instances(annos, image.shape[:2]) # 将标注转成Instance(Tensor)
dataset_dict["instances"] = utils.filter_empty_instances(instances) # 去除空的
return dataset_dict
data_loader = build_detection_train_loader(cfg, mapper=mapper)
# 构建dataloader时送入mapper
其实mapper简单来说就是将前面dataset中的原始dict转换成特定格式的输出,作为模型的输入。这个过程可以进行一定的数组增强,由于操作的numpy数组,所以你也可以用很多的数据增强库来处理。注意的是一点是如果你构建dataloader时没有送入mapper,那么会采用默认的mapper,具体见dataset_mapper,所以采用默认的mapper时候要确认一下这个mapper是否符合自己的数据集。另外一点是,detectron2对image的normalize是在Model中完成的,所以mapper中只需要转成float32的Tensor就可以。
如果你需要检查自己的dataloader是否符合预期,可以使用tools/visualize_data.py这个脚本对加载的数据进行可视化,这算是一个不错的debug工具。
参考
facebookresearch/detectron2 https://github.com/facebookresearch/detectron2
Detectron2 Beginner's Tutorial https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5
如果觉得不错,请关注一下公众号,也请为小编点个在看,期待下篇!
推荐阅读
VoVNet:实时目标检测的新backbone网络
想读懂YOLOV4,你需要先了解下列技术(一)
想读懂YOLOV4,你需要先了解下列技术(二)
PyTorch分布式训练简明教程
机器学习算法工程师
一个用心的公众号