百度飞桨图像分类------第四天(实现柠檬图像分类-日本竞赛题)
任务描述
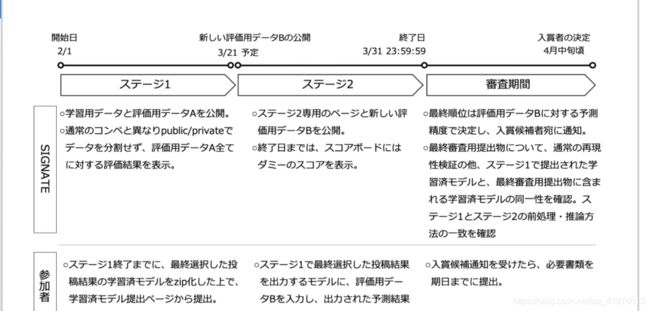
来源为:日本广岛Quest2020:柠檬外观分类竞赛部署实践
比赛链接:https://signate.jp/competitions/431
3-31比赛截止,大佬们可以去试试,我这个必然拿不住奖,仅做练习。
数据集:可以在百度ai studio找到。
如何根据据图像的视觉内容为图像赋予一个语义类别是图像分类的目标,也是图像检索、图像内容分析和目标识别等问题的基础。
本实践旨在通过一个美食分类的案列,让大家理解和掌握如何使用飞桨2.0搭建一个卷积神经网络。
特别提示:本实践所用数据集均来自互联网,请勿用于商务用途。
解压文件,使用train.csv训练,测试使用val.csv。最后以在val上的准确率作为最终分数。
✓调优
思考并动手进行调优,以在验证集上的准确率为评价指标,验证集上准确率越高,得分越高!模型大家可以更换,调参技巧任选,代码需要大家自己调通。
!cd data $$/
!unzip -oq /home/aistudio/data/data72793/lemon_homework.zip
!unzip -oq /home/aistudio/lemon_homework/lemon_lesson.zip -d /home/aistudio/lemon_homework/
!unzip -oq /home/aistudio/lemon_homework/lemon_lesson/test_images.zip -d /home/aistudio/lemon_homework/
!unzip -oq /home/aistudio/lemon_homework/lemon_lesson/train_images.zip -d /home/aistudio/lemon_homework/
解压后如图:

# 导入所需要的库
from sklearn.utils import shuffle
import os
import pandas as pd
import numpy as np
from PIL import Image
import paddle
import paddle.nn as nn
from paddle.io import Dataset
import paddle.vision.transforms as T
import paddle.nn.functional as F
from paddle.metric import Accuracy
import warnings
warnings.filterwarnings("ignore")
# 读取数据
train_images = pd.read_csv('lemon_homework/train.csv', usecols=['id','class_num'])
# labelshuffling
def labelShuffling(dataFrame, groupByName = 'class_num'):
groupDataFrame = dataFrame.groupby(by=[groupByName])
labels = groupDataFrame.size()
print("length of label is ", len(labels))
maxNum = max(labels)
lst = pd.DataFrame()
for i in range(len(labels)):
print("Processing label :", i)
tmpGroupBy = groupDataFrame.get_group(i)
createdShuffleLabels = np.random.permutation(np.array(range(maxNum))) % labels[i]
print("Num of the label is : ", labels[i])
lst=lst.append(tmpGroupBy.iloc[createdShuffleLabels], ignore_index=True)
print("Done" )
# lst.to_csv('test1.csv', index=False)
return lst
# 划分训练集和校验集
all_size = len(train_images)
# print(all_size)
train_size = int(all_size * 0.8)
train_image_list = train_images[:train_size]
val_image_list = train_images[train_size:]
# 数据打乱
df = labelShuffling(train_image_list)
df = shuffle(df)
train_image_path_list = df['id'].values
label_list = df['class_num'].values
label_list = paddle.to_tensor(label_list, dtype='int64')
train_label_list = paddle.nn.functional.one_hot(label_list, num_classes=4)
val_image_path_list = val_image_list['id'].values
val_label_list = val_image_list['class_num'].values
val_label_list = paddle.to_tensor(val_label_list, dtype='int64')
val_label_list = paddle.nn.functional.one_hot(val_label_list, num_classes=4)
# 定义数据预处理 数据增强
data_transforms = T.Compose([
T.Resize(size=(224, 224)),
T.RandomHorizontalFlip(224),
T.RandomVerticalFlip(224),
T.ColorJitter(0.4,0.4,0.4,0.4),
T.RandomRotation(90),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean=[0, 0, 0], # 归一化
std=[255, 255, 255],
to_rgb=True)
])
length of label is 4
Processing label : 0
Num of the label is : 234
Done
Processing label : 1
Num of the label is : 156
Done
Processing label : 2
Num of the label is : 136
Done
Processing label : 3
Num of the label is : 123
Done
# 构建Dataset
class MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
self.img = []
self.label = []
# 借助pandas读csv的库
self.train_images = train_img_list
self.test_images = val_img_list
self.train_label = train_label_list
self.test_label = val_label_list
if mode == 'train':
# 读train_images的数据
for img,la in zip(self.train_images, self.train_label):
self.img.append('lemon_homework/train_images/'+img)
self.label.append(la)
else:
# 读test_images的数据
for img,la in zip(self.test_images, self.test_label):
self.img.append('lemon_homework/train_images/'+img)
self.label.append(la)
def load_img(self, image_path):
# 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟
image = Image.open(image_path).convert('RGB')
return image
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
image = self.load_img(self.img[index])
label = self.label[index]
# label = paddle.to_tensor(label)
return data_transforms(image).astype("float32"), paddle.nn.functional.label_smooth(label)
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)
#train_loader
train_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train')
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=32, shuffle=True, num_workers=0)
#val_loader
val_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test')
val_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=32, shuffle=True, num_workers=0)
from work.mobilenet import MobileNetV2
# import paddle
# from paddle.vision.models import MobileNetV2
#定义输入
input_define = paddle.static.InputSpec(shape=[-1,3,224,224], dtype="float32", name="img")
label_define = paddle.static.InputSpec(shape=[-1,1], dtype="int64", name="label")
# 模型封装
# model_res = MobileNetV2(scale=1.0,num_classes=1000,with_pool=True)
model_res = MobileNetV2(class_dim=4)
model = paddle.Model(model_res,inputs=input_define,labels=label_define)
# 定义优化器
scheduler = paddle.optimizer.lr.LinearWarmup(
learning_rate=0.5, warmup_steps=20, start_lr=0, end_lr=0.5, verbose=True)
optim = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model.parameters())
# optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 配置模型
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(soft_label=True),
Accuracy()
)
# 模型训练与评估
model.fit(
train_loader,
val_loader,
log_freq=100,
epochs=35,
# callbacks=Callbk(write=write, iters=iters),
verbose=1,
save_dir="/home/aistudio/iterhui/", #把模型参数、优化器参数保存至自定义的文件夹
save_freq=1 #设定每隔多少个epoch保存模型参数及优化器参数
)
save checkpoint at /home/aistudio/iterhui/final
result = model.evaluate(val_loader,batch_size=32,log_freq=100, verbose=1, num_workers=0, callbacks=None)
print(result)
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 30/30 [==============================] - loss: 0.4650 - acc: 0.8526 - 482ms/step
Eval samples: 936
{'loss': [0.4650363], 'acc': 0.8525641025641025}
本模型仅仅达到了85%左右的准确率,想拿奖估计需要95+吧(本人揣测而已)