面向深层Transformer模型的轻量化压缩方法
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
深度模型在神经机器翻译(Neural Machine Translation,NMT)中取得突破性进展,但其计算量大且占用大量内存。基于此,讲者提出一种基于群体置换的知识蒸馏方法(Group-Permutation based Knowledge Distillation,GPKD), 将深层的Transformer模型压缩为浅层模型;为了进一步增强teacher模型的性能,提出了子层跳跃的方法(Skipping Sub-Layer),通过在三个数据集上的实验,验证了该两种方法的有效性。

李北:东北大学自然语言处理实验室博士二年级学生,导师是肖桐教授和朱靖波教授。研究方向主要包括深层网络建模,篇章级机器翻译,模型结构优化等话题。目前以第一作者在ACL、EMNLP、AAAI等会议发表多篇论文。
![]()
一、研究背景与动机
在自然语言处理的各项任务中均取得突破性进展的Transformer模型,采用自注意力网络与前馈神经网络的结构,具有高效的并行计算能力。尽管Transformer十分强大,但应用场景与需求不同,可进一步完善。讲者列举了部分针对Transformer进行改进的工作:
(1)引入相对位置信息,能够有效弥补自注意力机制本身缺乏对相对信息捕捉的能力,其中比较有代表性的工作是RPR以及Transformer-XL;
(2)从语言学角度来说,周围词与当前词可能蕴含更直接的联系,基于此可采用卷积的思想进行自注意力机制的计算;
(3)在处理长文本时提高网络的计算效率,比如Linformer;
(4)更复杂的层级连接,也是近年受关注的一个研究方向。
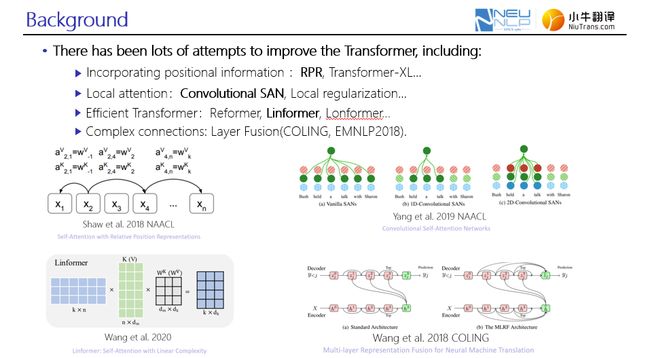
图1. 针对Transformer模型改进工作介绍
上述工作均是在受限模型理论下进行研究,然而神经网络本身是通过构造复杂函数来拟合数据,进而求解目标问题,因此模型容量对最终性能有很大的影响。这说明更大模型容量,能更好地利用数据来解决更复杂的问题。
常用的增大网络容量的方式大致可分为两种:
第一种是增大模型的宽度,这也是早期Transformer-Big模型的一种设计的思路,利用更大的隐藏层维度和词嵌入维度以及FFN中的一个映射维度来提高模型的表示能力;
第二种是增大模型的深度,其优势在于通过更多的非线性与线性函数组合来构造更复杂的函数,进而利用这种复杂函数来拟合目标问题。
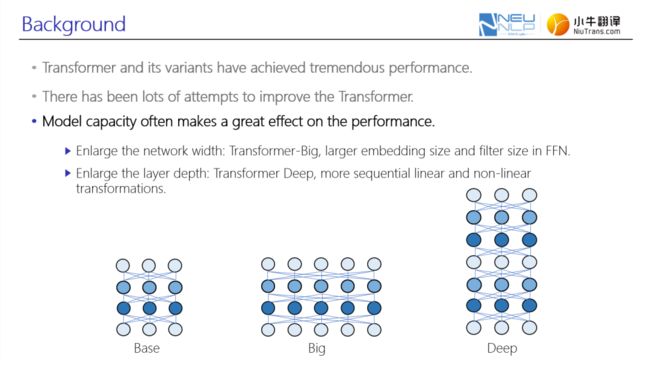
图2. 增大网络容量常用的两种方式
基于Transformer的研究,在机器翻译任务上也取得了广泛的关注,大致可分为两类工作:第一类是通过结构优化的方式,让网络中信息的传递效率变得更高效;第二类主要针对深层网络中的参数初始化进一步改进。
众所周知,目前 Transformer采用均匀初始化的方式得到w矩阵,该设计的核心思想是保证输入输出的方差一致性,最终得到了如图3所示的边界。然而伴随网络深度的增加,对方差一致性的约束也变得更加薄弱,图3中讲者列举的工作大部分针对如何在深层网络条件下保证方差一致性约束问题展开研究。

图3. 在机器翻译任务上深层Transformer的研究
综上,深层Transformer模型具有显著的性能优势,但随着网络深度增加(即模型越复杂),其计算量越大,占用计算资源越多,难以直接应用于小设备。那么如何在保证性能的前提下,将复杂的深层网络压缩至轻量级的网络?
知识蒸馏是解决上述问题的一种有效的技术手段,主要包括三种知识蒸馏方法:
第一种是基于词级的方法,相当于在训练student网络时,不仅能学习到ground truth,同时,通过增加teacher网络最顶层的表示与student表示之间的约束,以学习 teacher模型中的知识;
第二种区别于词级方法,采用一种基于序列的方式,即在进行student网络的学习中,不学习ground truth而是学习给定原语的teacher模型输出分布。简单来说将原语和teacher模型翻译的译文作为一个双语句对,以供student模型学习;这种方式可以弥补student模型由于本身容量受限,对真实数据分布加工能力不足的问题。
第三种是基于上述两种方法的融合。

图4. 常用知识蒸馏方法概述
图5中的两项工作致力于将BERT模型压缩至一个轻量化的网络,其核心思想是选取 teacher模型和student模型中的attention分布、词嵌入表示、中间隐藏层状态等,采用 MSE的方法构造损失函数。其弊端在于,在训练过程中,要求同步计算student模型和teacher模型的分布,消耗大量计算资源。因此,讲者首先围绕在机器翻译任务上如何压缩Transformer模型展开讨论。
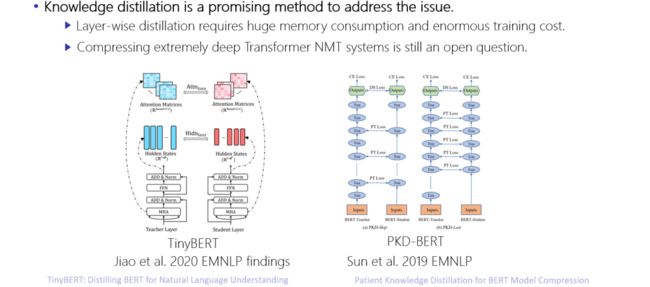
图5. 关于压缩BERT模型的相关工作
另一方面,在训练student模型时,更好的teacher模型能够提供更丰富的知识,通常采用增大teacher模型的深度来提高teacher模型的性能。但随着网络深度的增加,模型更易陷入过拟合。
导致该现象的主要原因是:由于不同子层之间的残差连接,丰富网络输出的同时,也在一定程度上限制了网络的泛化能力,致使其陷入过拟合。因此,讲者进一步针对是否可以在训练的过程中随机丢弃一部分分支以达到鲁棒性训练目的展开讨论。
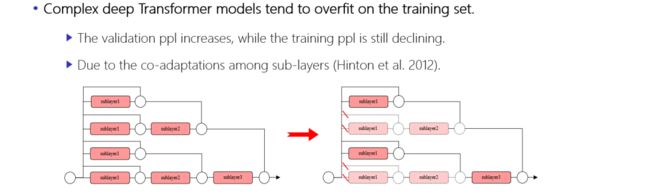
图6. 模型深度增加导致过拟合现象
二、GPKD及子层跳跃方法介绍
针对第一个问题,如何更高效地学习轻量化的student模型?讲者提出GPKD方法。相当于采用一种组内扰乱teacher的方法来训练后,用teacher模型隐藏层状态初始化student模型;然后通过序列化的知识蒸馏方法充分训练student模型。
整个方法可以大致包括三个部分:
第一,进行组内扰乱的teacher训练。首先,假设teacher有m层网络,student有n层网络,为将m层teacher的性能或知识迁移到 n层student模型上,用m除以n得到的数值,作为每个group内的层数;之后在训练teacher模型时,每个group内的层计算顺序可随机打乱,且不同group间的顺序扰乱是无关的;同时在不同batch的训练过程中,不同batch间的扰乱也是独立。该方式目的在于,让每一个group内的每一个子层都能模仿整个group的输出,便于后续student模型的训练。
第二,采用标准的基于序列级的知识蒸馏方法。即在给定Src和Tgt双语句对时,首先将得到的teacher模型进行 inference;然后将得到的SKD-Tgt以及Src作为 student模型的训练数据。
第三,在训练student的过程,随机挑选每一个group内的一层网络参数来初始化student模型,该方法不仅能加快student模型的训练,还能进一步逼近teacher性能,甚至达到和teacher相当性能。
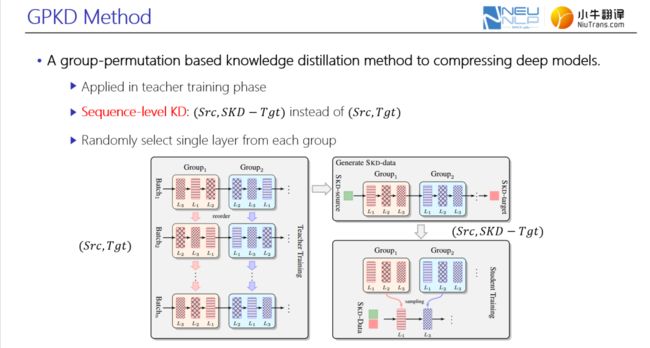
图7. GPKD方法介绍
针对第二个问题,如何解决模型过拟合?讲者提出了子层跳跃的正则化训练方法,即在进行网络前向计算时,采用dropout的思想对每一个子层进行控制,决定子层保留或丢弃。不同于常见dropout思路,在构造子层训练方法时,采用自适应权重来区分不同深度子层被dropout的概率。该方式使得底层的子层更易被保留,而顶层的子层更易被丢弃,主要是由于,在层级连接网络中,底层网络的计算较顶层更加重要。在推断阶段,同样基于dropout的思想,激活所有分支,同时采用一种rescale方式,将每一个子层的输出进行缩放。
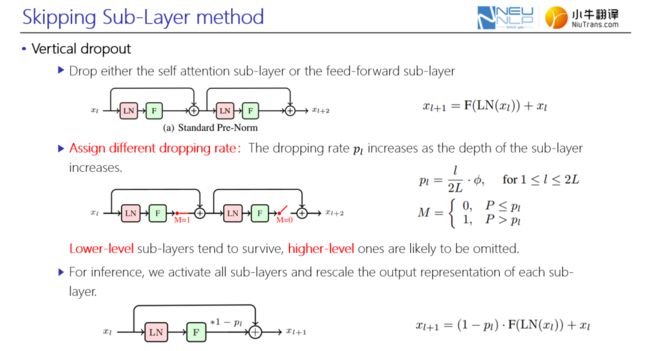
图8. 子层跳跃方法介绍
三、实验
1.数据集介绍
实验主要在WMT En-De,NIST Zh-En,WMT19 Zh-En三个任务上进行,其中训练集、验证集和测试集如表1所示。

表1. 实验数据集介绍
2.训练细则
训练过程中采用Pre-Norm作为基线模型,分别对标准的Transformer模型以及加入相对位置编码的RPR模型进行实验。采用multi-bleu和sacrebleu分别作为NIST Zh-En和WMT19 Zh-En两个任务上的评测指标。
3.GPKD在编码端的实验效果
图a)蓝色表示深层模型的性能,粉色表示6层基线模型的性能,由结果知:随着网络深度增加,模型的性能显著提升;绿色表示使用序列化知识蒸馏方法的性能,结果表明其能减小student模型与teacher模型之间的性能差距,但依旧存在较大的gap;黄色表示使用GPKD方法得到的student模型性能,结果表明在不同参数规模下, GPKD方法使student模型性能接近teacher模型,尤其从24层压缩到6层时,几乎没有任何的性能损失。此外 GPKD方法较标准的序列化知识蒸馏方法有将近0.5-0.8幅度的性能提升。
图b)结果表明,在NIST Zh-En数据集上,GPKD方法较SKD同样有显著的性能优势。
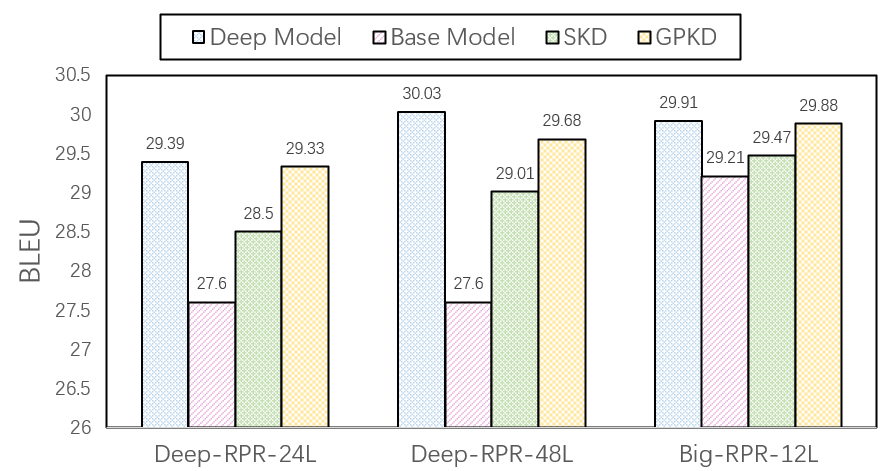
a)WMT En-De
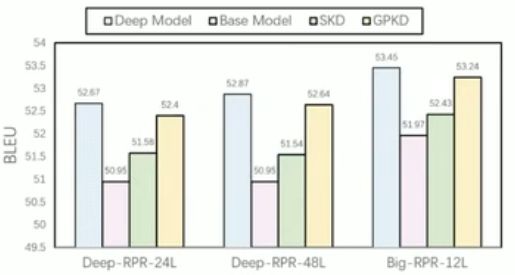
b) NIST Zh-En
图9. GPKD在编码端的性能对比实验
4.GPKD在解码端的实验效果
进一步将该方法用于解码端,分别衡量了随着解码端深度的增加,浅层和深层网络的BLUE性能以及推断速度。图中蓝色的曲线表示深层网络,红色曲线表示浅层的6层网络。由图可知,随着解码端深度的增加,并没有显著的性能增益;反而在可接受性能范围内,适度减小深层网络解码层深度时,解码端推断速度可大幅度提高。讲者将这类深层编码器-浅层解码器的组合称之为异构网络,在一些工业应用上表现突出,既能保证翻译的准确度,同时满足工业生产的推断时延需求。
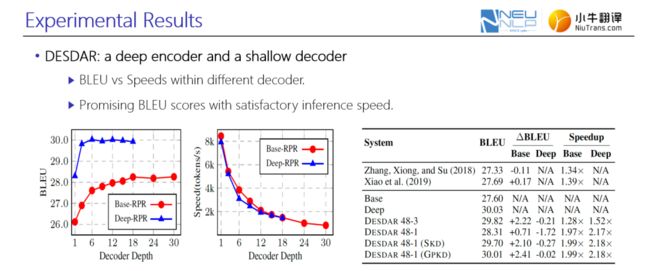
图10. GPKD在解码端的性能对比实验
5.子层跳跃方法的实验效果
引入子层跳跃之后,模型在三个数据集上的校验集PPL稳定下降,说明加入该方法后,有效提高了模型泛化能力,缓解过拟合现象。此外,在三个数据集上,网络性能也出现一定的提升,在WMT En-De数据集上,引入子层跳跃后较48层深度网络,BLUE性能提升了0.6。
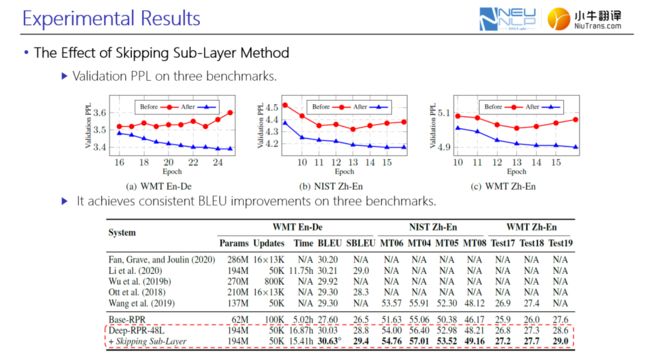
图11. 加入子层跳跃后的实验验证
图12左图表明,当在校验集上呈现收敛趋势后引入子层跳跃方法的网络,对比从头训练就使用子层跳跃方法的网络,具有显著的性能优势;同时与另外两项工作相比,子层训练方法较其在BLUE性能上存在较大竞争优势。
针对如何选取子层跳跃的力度,进行了消融实验。右图结果表明,直接跳跃整层网络的计算,其性能略低于基线模型;随机丢弃任何一个自注意机制网络或是前馈神经网络,其性能较基线模型有一定性能提升;同时丢弃自注意机制网络和前馈神经网络具有最好的性能。
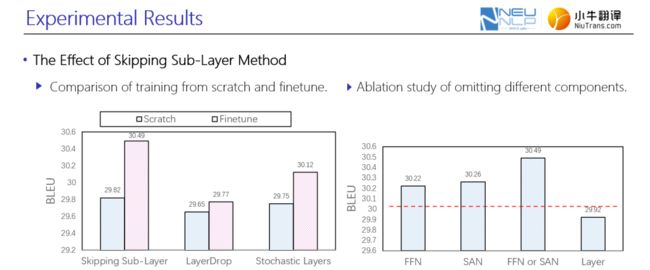
图12. 加入子层跳跃后的实验验证
四、总结
讲者针对深层网络训练中的两个问题——如何更高效地学习轻量化的student模型以及如何缓解过拟合现象,分别提出了GPKD方法以及子层跳跃方法,结合两种方法来增强teacher模型的训练,进而得到一个更强的student模型。
相关资料
论文链接:
https://arxiv.org/pdf/2012.13866.pdf
Github地址:
https://github.com/libeineu/GPKD
整理:刘美珍
审稿:李 北
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/cwjt8W)
(点击“阅读原文”下载本次报告ppt)