注:本文翻译自 CreateMoMo 个人博客,暂未取得作者授权,仅做学习交流使用,如若侵权,立即删除。点击底部阅读原文可直达原博客。
目录
该系列文章将会涉及以下几个方面:
Idea 概述 - 在命名实体识别任务中,为什么要在 BiLSTM模型上添加CRF层?
案例解读 - 通过一个简单的实现来揭示:CRF 层是怎样工作的?
Chainer 实现 BiLSTM+CRF 模型(翻译者会努力用 TensorFlow or PyTorch 来实现一番!)
谁适合阅读本系列文章?
本系列文章适合 NLP 或其他 AI 相关领域的初学者或者在校学生,希望你们在我的文章中能有所收获。期待有建设性的意见和建议!
前置知识
如果你不知道神经网络、CRF 或者其他相关的知识,别担心,我会尽量从直觉上来帮助你来理解它们。唯一需要你知道的是命名实体识别的概念!
1 简介
对于命名实体识别任务来说,基于神经网络和深度学习的方法越来越流行了。比如在这篇Paper中,作者就提出了 BiLSTM-CRF 模型用于命名实体识别任务,文中使用了 word level 和 character level 的 embedding。我将使用这篇文章中的模型来解释模型中 CRF层 是如何工作的 :) 。
如果你还不了解有关 BiLSTM 和 CRF 的细节的话,只要记住它们不过是命名实体识别模型中两种不同的 Layer 罢了!
1.1 开始之前
首先,假设我们的数据集中有两种不同的实体类型:Person(人物) 和 Organization(组织)。那么,实际上,我们便有了五种实体的类别 Label :
- B-Person
- I-Person
- B-Organization
- I-Organization
- O
这样的话,假如我们使用 代表包含五个单词的句子,。那么,在句子 中, 是一个 Person 实体, 是一个 Organization 实体,其他的单词我们用 表示。
1.2 BiLSTM-CRF model
在这里我会简要介绍一下 BiLSTM-CRF 模型。
如下图所示:
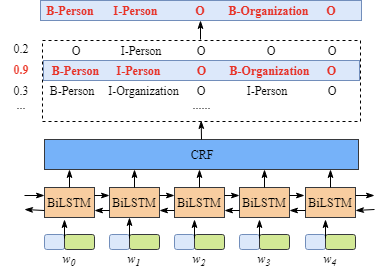
首先,在句子 中的每一个词 都对应着一个向量表示,这个向量由字符级别的词嵌入(character embedding)和单词级别的词嵌入(word embedding)共同组成(concat 操作?)。其中,字符级别的词嵌入(character embedding)由随机初始化得到,而单词级别的词嵌入(word embedding)一般来自于预先训练好的 word embedding 文件(word2vec 或者 GloVe)。所有的 embeddings 在训练过程中将会被 fine-tuned。
其次,BiLSTM-CRF 模型的输入便是这些词向量,模型的输出是对句子 中单词对应的标签类别的预测。尽管了解 BiLSTM 层的细节对于我们来说并不必要,但是为了更加容易的理解 CRF 层,还是有必要知道一下 BiLSTM 层输出结果表示什么意思。
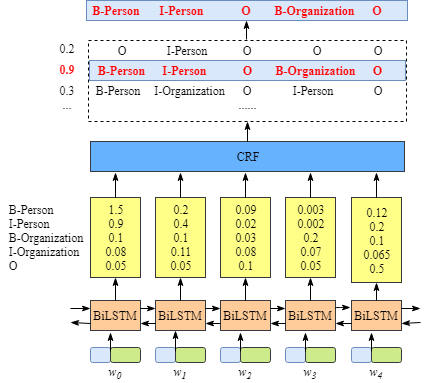
如上所示, BiLSTM 层的输出是每个类别的预测分数值。譬如,对于词 来说,BiLSTM 层的输出为:1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) 和 0.05 (O)。这些分数值将会作为 CRF 层的输入。
之后,在所有由 BiLSTM 层预测的分数值输入到 CRF 层之后,CRF 便会选择具有最高预测分数值的类别标记序列作为最佳的答案。
1.3 如果没有 CRF 层会怎么样?
你可能已经注意到了,假使没有 CRF 层,我们一样可以只训练 LSTM 来进行命名实体识别,流程如下:

因为 BiLSTM 层输出的正是每个单词的在各个类标上的分数值,我们完全可以选择具有最高分数的类标作为单词的命名实体类别标注。
譬如,对于 来说, “B-Person” 具有最高的得分(1.5),因而我们可以选择 “B-Person”作为最佳的预测。同理,对于,我们可以选择 “I-Person”;对于 ,我们可以选择 “O”;对于 ,我们可以选择 “B-Org”;对于 ,我们可以选择 “O”。
在这个例子中,尽管我们可以得到句子中各个单词的正确类别标记。但是,有些情况下并不总是如此,看一看这个例子:

很显然,沿用上面的方法,我们得到的输出(“I-Organization I-Person” 和 “B-Organization I-Person” )便显得非常的不合理了,I-Organization 之后竟然会出现 I-Person 的标注!
1.4 CRF 层能够从训练数据中学习到标注序列的一些“约束”
The CRF layer could add some constrains to the final predicted labels to ensure they are valid. These constrains can be learned by the CRF layer automatically from the training dataset during the training process.
CRF 层能够给最终的预测 Labels 添加一些约束来确保其合理有效。在训练过程中,这些约束会被 CRF 层自动学习到。
这些约束可以是:
句子中首个单词的 Label 应该是 “B-“ or “O”, 而不会是 “I-“
“B-label1 I-label2 I-label3 I-…”,在这个模式中, label1, label2, label3 … 应该是同一实体的 Label。譬如,“B-Person I-Person” 是合理有效的,但是 “B-Person I-Organization” 便是无效的。
“O I-label” 是无效的。命名实体的第一个起始标注应该是 “B-“ 开头的,而不是 “I-“。换一句话说,合理有效的模式应该是 “O B-label”
有了这些必要的约束,出现不合理标注序列的数量将会显著下降!
后续
接下来,我将通过分析 CRF 的 Loss Function 来解释 CRF 层如何从训练数据集中学习到上述约束,以及为什么 CRF 能够学习到它们。
别走开,后续更加精彩!
参考文献
[1] CRF_Layer_on_the_Top_of_BiLSTM_1
[2] Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K. and Dyer, C., 2016. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360.