时间序列分析——python
经典方法
移动平均法
移动平均(英语:moving average,MA),又称“移动平均线”简称均线,是技术分析中一种分析时间序列数据的工具。
1.一次移动平均法
简单例题

方式一:等量加权策略
import numpy as np
#y0 = np.array([423,358,434,445,527,429,426,502,480,384,427,446])
y = np.array([423,358,434,445,527,429,426,502,480,384,427,446])
def MoveAverage(y,N):
Mt = ['*']*N
for i in range(N,len(y)):
M = y[i-N:i].mean()
Mt.append(round(M))
return Mt
yt3 = MoveAverage(y,3)#计算3个月
s3 = np.sqrt(((y[3:]-yt3[3:])**2).mean())#计算误差
yt5 = MoveAverage(y,5)#计算5个月
s5 = np.sqrt(((y[5:]-yt3[5:])**2).mean())#计算误差
原实际数据波动较大,经移动平均后,随机波动明显减少了,N越大,波动也越小。同时误差较大,对于实际波动较大的序列,一般较少采用此方法预测。
方式二:将等量加权策略改为卷积(滑动平均滤波法)
#卷积形式
y = np.array([423,358,434,445,527,429,426,502,480,384,427,446])
n1 = 3
yt1 = np.convolve(np.ones(n1)/n1,y)[n1-1:-n1+1]
s1 = np.sqrt(((y[n1:]-yt1[:-1])**2).mean())#计算误差
n2 = 5
yt2 = np.convolve(np.ones(n2)/n2,y)[n2-1:-n2+1]
s2 = np.sqrt(((y[n2:]-yt2[:-1])**2).mean())#计算误差
print('N = 3时,卷积预测值:',yt1,',预测的标准误差:',s1)
print('N = 5时,卷积预测值:',yt2,',预测的标准误差:',s2)
2.二次移动平均法
二次移动平均法,是对一次移动平均数再进行第二次移动平均。
如上所述,运用一次移动平均法求得的移动平均值,存在滞后偏差。特别是在时间序列数据呈现线性趋势时,移动平均值总是落后于观察值数据的变化。二次移动平均法,正是要纠正这一滞后偏差,建立预测目标的线性时间关系数学模型,求得预测值。二次移动平均预测法解决了预测值滞后于实际观察值的矛盾,适用于有明显趋势变动的市场现象时间序列的预测, 同时它还保留了一次移动平均法的优点。二次移动平均法适用于时间序列呈现线性趋势变化的预测。
'''
二次移动平均法
'''
import numpy as np
y0 = np.array([423,358,434,445,527,429,426,502,480,384,427,446])
y = np.array([423,358,434,445,527,429,426,502,480,384,427,446])
#滑动平均函数
def MoveAverage(y,N):
Mt = ['*']*N
for i in range(N,len(y)):
M = y[i-N:i].mean()
y[i] = M
Mt.append(round(M))
return Mt
yt3 = MoveAverage(y,3)#计算3个月
s30 = np.sqrt(((y0[3:]-yt3[3:])**2).mean())#计算与真实数据误差
s3 = np.sqrt(((y[3:]-yt3[3:])**2).mean())#计算与预测所用样本的误差
yt5 = MoveAverage(y,5)#计算5个月
s5 = np.sqrt(((y[5:]-yt3[5:])**2).mean())#计算误差
指数平滑法
指数平滑法是生产预测中常用的一种方法。也用于中短期经济发展趋势预测,所有预测方法中,指数平滑是用得最多的一种。简单的全期平均法是对时间数列的过去数据一个不漏地全部加以同等利用;移动平均法则不考虑较远期的数据,并在加权移动平均法中给予近期资料更大的权重;而指数平滑法则兼容了全期平均和移动平均所长,不舍弃过去的数据,但是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数。
也就是说指数平滑法是在移动平均法基础上发展起来的一种时间序列分析预测法,它是通过计算指数平滑值,配合一定的时间序列预测模型对现象的未来进行预测。其原理是任一期的指数平滑值都是本期实际观察值与前一期指数平滑值的加权平均。
1.一次指数平滑法

'''
指数平滑法
'''
import numpy as np
import pandas as pd
y = np.array([4.81,4.8,4.73,4.7,4.7,4.73,4.75,4.75,5.43,5.78,5.85])
def ExpMove(y,a):
n = len(y)
M = np.zeros(n)
M[0] = (y[0]+y[1])/2
for i in range(1,len(y)):
M[i] = a*y[i-1]+(1-a)*M[i-1]
return M
#预测
yt1 = ExpMove(y,0.2)
yt2 = ExpMove(y,0.5)
yt3 = ExpMove(y,0.8)
#计算误差
s1 = np.sqrt(((y-yt1)**2).mean())
s2 = np.sqrt(((y-yt2)**2).mean())
s3 = np.sqrt(((y-yt3)**2).mean())
d = pd.DataFrame(np.c_[yt1,yt2,yt3])#np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等
f = pd.ExcelWriter('Pdata.xlsx')
d.to_excel(f)
f.close()#数据写入excel文件
print('预测的标准误差分别为:',s1,s2,s3)#输出预测的标准误差
yh = 0.8*y[-1]+0.2*yt3[-1]
print('下一周期预测值为:',yh)
2.二次指数平滑法
二次指数平滑是对一次指数平滑的再平滑。它适用于具线性趋势的时间数列。
计算公式
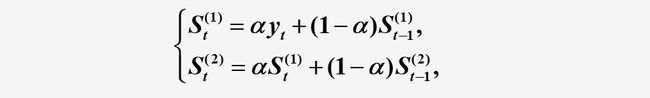

#二次指数平滑
import numpy as np
import pandas as pd
y = np.loadtxt('Pdata18_3.txt')
n = len(y)
alpha = 0.3
yh = np.zeros(n)
s1 = np.zeros(n)
s2 = np.zeros(n)
s1[0] = y[0]
s2[0] = y[0]
for i in range(1,n):
s1[i] = alpha*y[i]+(1-alpha)*s1[i-1]
s2[i] = alpha*s1[i]+(1-alpha)*s2[i-1]
yh[i] = 2*s1[i-1]-s2[i-1]+alpha/(1-alpha)*(s1[i-1]-s2[i-1])
at = 2 * s1[-1] - s2[-1]
bt = alpha / (1 - alpha) * (s1[-1] - s2[-1])
m = np.array([1, 2])
yh2 = at + bt * m
print('预测值为:', yh2)
d = pd.DataFrame(np.c_[s1, s2, yh])
f = pd.ExcelWriter('Padata18_3.xlsx')
d.to_excel(f)
f.close()
具有季节性时间序列的预测
季节趋势预测法根据经济事物每年重复出现的周期性季节变动指数,预测其季节性变动趋势。推算季节性指数可采用不同的方法,常用的方法有季(月)别平均法和移动平均法两种:a.季(月)别平均法。就是把各年度的数值分季(或月)加以平均,除以各年季(或月)的总平均数,得出各季(月)指数。这种方法可以用来分析生产、销售、原材料储备、预计资金周转需要量等方面的经济事物的季节性变动;b.移动平均法。即应用移动平均数计算比例求典型季节指数。下面介绍第一种,即季别平均法。
方法步骤:


举例说明:

'''
具有季节性的时间序列预测
'''
import numpy as np
a = np.loadtxt('Pdata18_4.txt')
m,n = a.shape
amean = a.mean()#计算所有数据的平均值
cmean = a.mean(axis = 0)#逐列求平均值
r = cmean/amean #计算季节系数
w = np.arange(1,m+1)
yh = w.dot(a.sum(axis=1))/w.sum()#计算下一年的预测值
yj = yh/n #计算预测年度的平均值
yjh = yj*r #计算季度预测值
print('下一年度个季度的预测值:',yjh)
LSTM
导入工具包
'''
LSTM
'''
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
加载数据
#load the dataset
data = pd.read_csv('AirPassengers.csv',)
data['Month'] = pd.to_datetime(data['Month'])
#时间数据处理
data['year'] = data.Month.dt.year
data['month'] = data.Month.dt.month
#data['day'] = data.Month.dt.day
data.drop(columns = ['Month'],inplace=True)
# 将整型变为float
data = data.astype('float32')
图像建模(来一波好看的生图)
#10年来的时间序列图
plt.plot(data['#Passengers'])
plt.show()
每个周期的波形基本一致,可以直观看出波动幅度是越来越大的。
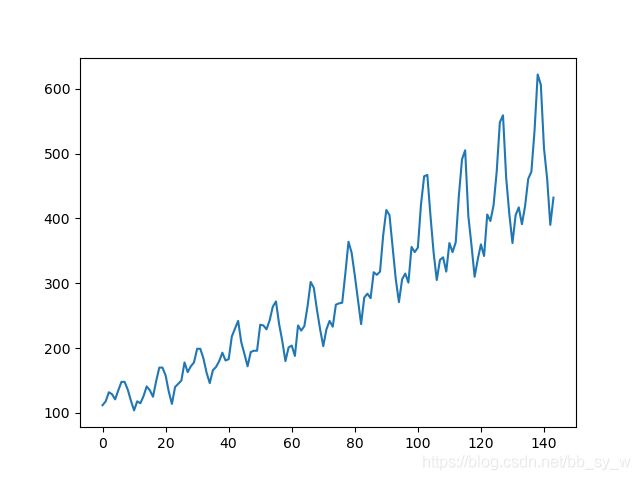
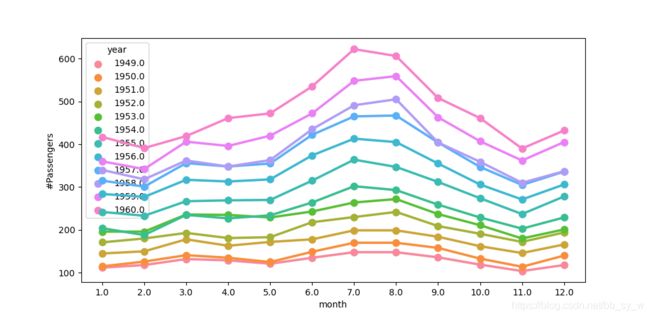
sns.violinplot(x='year',y='#Passengers',data=data)
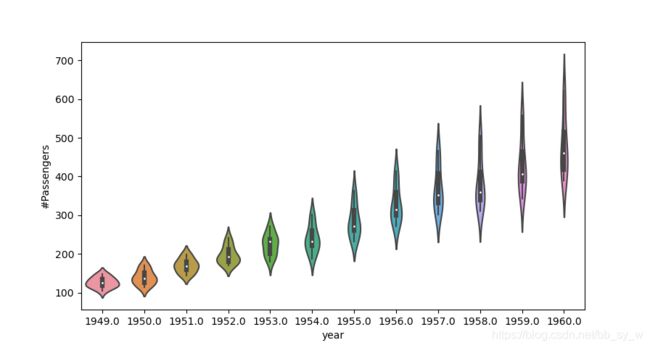
每年夏季出游航班数最多,随着year的增加,夏季的峰值更加明显。
sns.barplot(x = 'year',y = '#Passengers',hue = 'month',data = data)
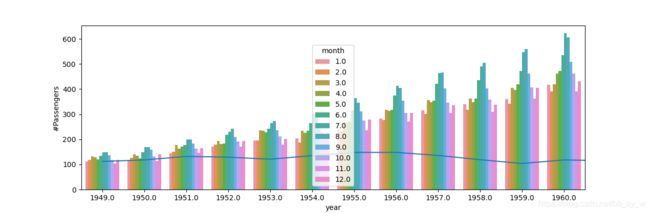
每年总乘客数趋势
year_grp = pd.DataFrame()
year_grp['year_'] = year_group.index
year_grp['Passengers_'] = year_group.values
#点图
sns.pointplot(x ='year_' ,y ='Passengers_',data=year_grp)
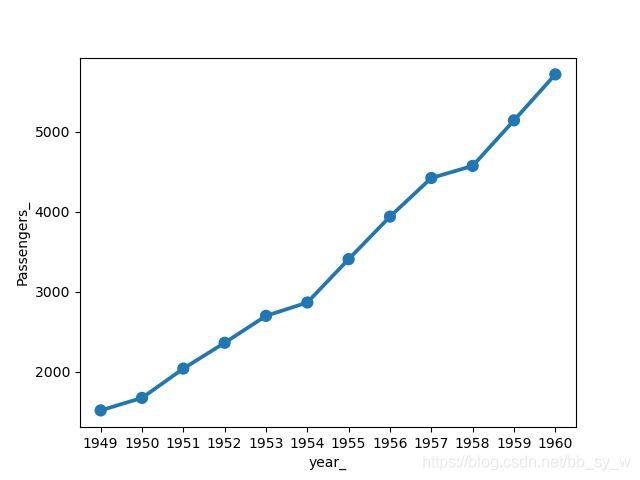
每一年的变化趋势
sns.pointplot(x ='year_' ,y ='Passengers_',data=year_grp)
在进行任何操作之前,最好先固定随机数种子,以确保我们的结果可重复。
# fix random seed for reproducibility
numpy.random.seed(7)
从数据集中提取NumPy数组,并将整数值转换为浮点值,这更适合使用神经网络进行建模。
dataset = dataframe.values
dataset = dataset.astype('float32')
LSTM对输入数据的大小敏感,特别是在使用S型(默认)或tanh激活函数时。将数据重新缩放到0到1的范围(也称为归一化)可能是一个好习惯。
# normalize the dataset
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
对于时间序列数据,值的顺序很重要。我们可以使用的一种简单方法是将有序数据集拆分为训练数据集和测试数据集。下面的代码计算分割点的索引,并使用67%的观测值将数据分离到训练数据集中,这些观测值可用于训练模型,剩下的33%用于测试模型。
#在不打乱顺寻的前提下划分数据集
# split into train and test sets
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
print(len(train), len(test))
数据集配置
现在,如上所述,我们可以定义一个函数来创建新的数据集。
该函数有两个参数:dataset和我们要转换为数据集的NumPy数组,look_back是用作输入变量以预测下一个时间段的上一个时间步数(在这种情况下)默认为1。
此默认值将创建一个数据集,其中X是给定时间(t)的乘客数量,Y是下一次(t + 1)的乘客数量。
可以对其进行配置,我们将在下一部分中构造一个形状不同的数据集。
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)
如果将前5行与上一节中列出的原始数据集样本进行比较,则可以在数字中看到X = t和Y = t + 1模式。
| X | Y |
|---|---|
| 112 | 118 |
| 118 | 132 |
| 132 | 129 |
| 129 | 121 |
让我们使用此功能来准备训练和测试数据集以进行建模。
# reshape into X=t and Y=t+1
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
LSTM网络期望输入数据(X)具有以下形式的特定数组结构:[样本,时间步长,特征]。
目前,我们的数据格式为:[ 样本,特征 ],并且我们将问题定为每个样本的一步。我们可以用numpy.reshape()将准备好的训练和测试输入数据转换为预期的结构,如下所示:
# reshape input to be [samples, time steps, features]
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
模型训练、评估、预测
我们现在准备设计和适合我们的LSTM网络以解决此问题。
该网络具有一个带有1个输入的输入层,一个带有4个LSTM神经元的隐藏层以及一个进行单个值预测的输出层,模块中使用sigmoid激活函数。该网络训练了100次,数据批量大小为1。
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
模型评估、预测
#make predictions
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
#invert Predictions(反归一化)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# calculate root mean squared error
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
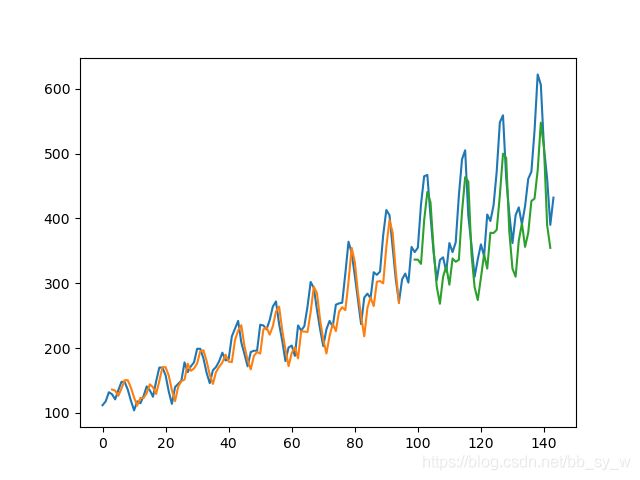
最后,我们可以使用模型为训练和测试数据集生成预测,以直观地了解模型的表现。
由于数据集的构造方式,我们必须移动预测值,以使它们在x轴上与原始数据集对齐。准备好之后,将数据绘制出来,以蓝色显示原始数据集,以绿色显示训练数据集的预测,以红色显示模型未见过的测试数据集的预测。
# shift train predictions for plotting
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:,:] = np.nan
trainPredictPlot[look_back:len(trainPredict)+look_back,:] = trainPredict
# shift test predictions for plotting
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
#这个切片要注意
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
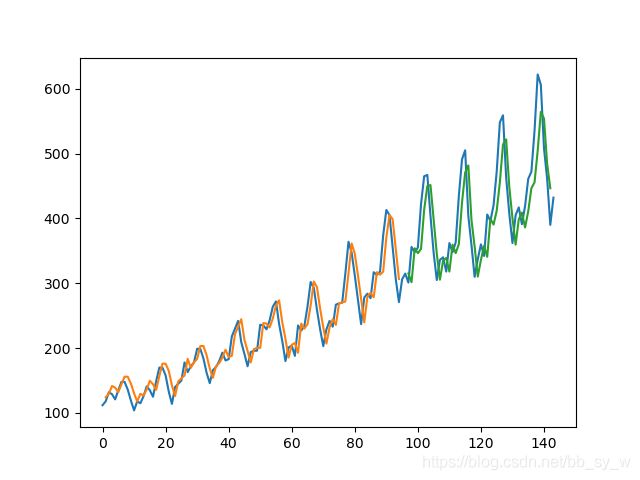
调整数据集时间步长
| X1 | X2 | X3 | Y |
|---|---|---|---|
| 112 | 118 | 132 | 129 |
| 118 | 132 | 129 | 121 |
| 132 | 129 | 121 | 135 |
'''
改变步长
'''
#increasing the look_back argument from 1 to 3.
# LSTM for international airline passengers problem with window regression framing
import numpy as np
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
# convert an array of values into a dataset matrix
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return np.array(dataX), np.array(dataY)
# fix random seed for reproducibility
np.random.seed(7)
# load the dataset
dataframe = read_csv('AirPassengers.csv', usecols=[1], engine='python')
dataset = dataframe.values
dataset = dataset.astype('float32')
# normalize the dataset
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# split into train and test sets
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
# reshape into X=t and Y=t+1
look_back = 3
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# reshape input to be [samples, time steps, features]
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# make predictions
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# invert predictions
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# calculate root mean squared error
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# shift train predictions for plotting
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()