前言
目前主流的搜索引擎实时性一般都不是很高。对于一般的网站内容,延迟一段时间问题不大,但对于 twitter 这种网站,热点信息会被迅速地发布和传播,对于搜索的实时性要求会更高,因此需要设计一种实时的搜索架构来解决这一问题。
需求分析
首先,需要保证搜索的实时性,能让一条 tweet 在发布后的几秒或几十秒内就能被搜索到。其次,每秒钟都有成千上万条 tweet 被发布,所以要求搜索引擎有大的吞吐量。最后,每个时刻都会有许多用户进行搜索,需要搜索引擎在高并发的环境下正常工作。
现有的解决方案
- Solr/ElasticSearch:使用 Lucene 的 Near-Realtime Search 机制可以实现近实时的搜索。缺点:实时性不够高,且不适合大规模高并发的同时读写。
- LinkedIn Zoie:将索引分成内存跟磁盘两块,写全在内存索引上,读同时读内存索引和磁盘索引,内存块到一定大小合并到磁盘。缺点:磁盘上的索引会按一定的合并策略进行合并,如果数据写入很多且频繁,磁盘索引的合并也会频繁,在性能上可能达不到要求。
Twitter 解决方案
为了达到实时、高吞吐量、高并发的要求,twitter 从架构、索引结构、并发策略上做了很多巧妙的设计,我们依次展开介绍。
整体架构
首先我们可以分析一下一条 tweet 的组成,搜索引擎用到的大致有以下几部分:文本内容、转发数、评论数、点赞数。其中,文本内容在作者发布后就不会再改变,而转发数、评论数、点赞数等信息(主要用于后期排序)会实时快速的变化。因此,twitter 将这两块内容分开处理,见下图:
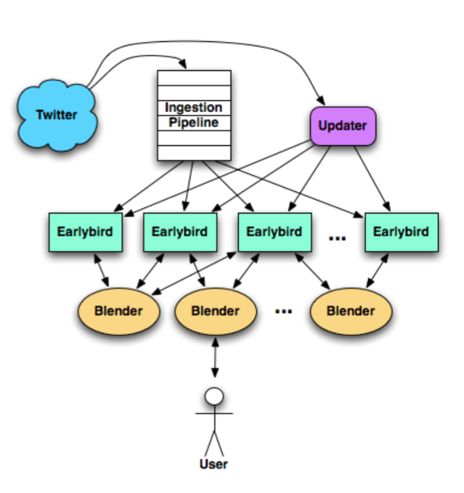
对于静态文本内容,通过队列缓冲,然后进入 earlybird 写索引;对于动态信息,通过一个单独的 Updater 组件进行更新。
earlybird 是提供索引读写的服务单元,一个 earlybird 服务部署在一台服务器,整个搜索引擎由若干台 earlybird 组成,tweet 根据 id partition 到某台 earlybird 服务器。在搜索时,同时搜索所有 earlybird 服务器,然后在搜索前端组件 Blender 进行组合、排序,最后返回搜索结果给用户。
索引结构
为了实时性以及性能,earlybird 将所有索引存放在内存中。一个 earlybird 服务的索引分成多个(目前是12)索引段,每段存放223 条 tweet。在同一时刻,所有的索引段中只有一段是可同时读写的,其他的所有索引段都是只读的。写索引时,先在可读写索引段上写,等写的 tweet 数量到达阈值 223 后,就停止写,转化成只读索引段,同时新启一个可同时读写的索引段。
由于 earlybird 将所有索引存放在内存中,如何减少内存开销以及减少 java 的 GC 时间将会是设计的一个核心工作。
搜索引擎的索引是倒排索引,即 <词,包含该词的文档信息列表> 的对应关系。其中记录词的结构称为词典,记录文档信息列表的结构称为 Postings List,下面依次展开介绍:
词典
earlybird 将词典简化为一个 HashMap 的结构,而不是常见的跳跃表(skip list)或 FST,由于 HashMap 是无序的,因此他不支持一些高级搜索功能(如模糊查询)。
针对 HashMap,java 的默认实现需要大量的对象结构,内存不友好,earlybird 用内存更友好的数组来实现(用开放寻址法处理哈希冲突),并且,它通过两个并行数组(数组相同 index 的值一一对应)存储了 Posting List 的尾部指针以及 Postings List 中的文档数。这样,对于词典来说,全部都是数组,省内存且 GC 的性能消耗也很少。
Postings List
Postings List 存储这个词对应的所有文档信息,一条信息成为 posting,一般 posting 由文档 id 和一些利于快速排序的元信息组成。earlybird 的 posting 是一个 32 位的 int,24 位存储 docid,8位存储该词在文档中出现的位置(因为一条 tweet 最多140字符,所以这里只要留 8 位就足够,一个紧贴需求的巧妙设计)。这样一来,一个 Postings List 就可以也可以简化为一个 int 数组,省内存且 GC 友好。
对于每条 tweet,每个 earlybird 服务内部维护了一个自增的 docid,建索引时,每个 docid 以 append 的形式添加到 Postings List,因此 Postings List 的数组是按 docid 从小到大有序排列的,所以可以使用二分查找高性能地进行查询而不需要其他复杂的数据结构。
由于我们使用数组存储 Postings List,数组是定长的,由于索引会被实时写入,且每个词对应的 Postings List 长度千差万别,如果我们采取申请一大块数组慢慢添加的策略,会有很多的内存空间被浪费;如果我们采取申请小数组,针对每次 posting 添加,通过数组拷贝的方式动态加大,将会有很多数组拷贝和 GC 的开销。
为了平衡内存空间和写索引效率,earlybird 采取了以下策略:
- 定义四种类型的数组,长度分别是21,2^4,27,211。每一种类型长度的数组放在一个「池(pool)」中,每个池中有 N 个相同长度的数组,一个数组成为一个 slice。
- 在写 Postings List 时,先从 pool1 中申请 21 长度的数组,写满后再从 pool2 申请 2^4 长度的数组,数组第一位保留上一个存储块的地址,以此类推,211 长度块后都接 211长度。
- 由于采取这种策略,一个 逻辑上由多个 slice 组成(每个 slice 是一个 int 数组),因此需要有个指针(int 类型)将这些逻辑块连接在一起,earlybird 将 32 位的 int 指针拆成了三部分:2 位表示pool 号(只有4种 pool,2位足够),10 位表示 slice 号(在指定 pool 中定位具体哪个 slice),11 位表示在 slice 中的 offset。因此,一个用一个 int 定位到 Postings List 中的任何位置,词典中并行数组存储 Postings List 尾部指针,slice 块第一位存储上一逻辑块的地址,都是采用这个 int 指针。
当一个索引段写的 tweet 数到达阈值后,就从可写的索引段转化为只读索引段。此时已经知道每个词的 Postings List 的长度,因此可以重新申请定长的数组,不会造成空间浪费。同事,对只读索引段可以进行压缩,进一步节省内存的使用,earlybird 采用 PForDelta 算法进行压缩,具体算法在这里就不展开了。
并发读写优化
首先,并发问题只会存在于可写的索引段中。由于索引的写入和读取都非常频繁,在面临高并发时,如果使用显示锁,对性能会是一个不小的开销。earlybird 通过 java volatile 的内存屏障特性,使读写过程无锁化,进而提高并发性能。
关于 volatile,网上有很多文章,这里简单说一点,被 volatile 修饰的变量可以保证所有线程都对其最新值可见,但存在本地线程空间里的该变量值不能保证与最新值同步,因此,采用此策略只能是一个线程写,多个线程读的场景。
earlybird 用一个线程写索引,通过 volatile 修饰的 maxDoc 变量来进行一致性保障。写索引时,会遍历一条 tweet 中的所有词进行建索引,待这条 tweet 建索引完毕后,maxDoc++;读索引时,先读取 maxDoc,然后根据查询条件查询所有结果,查询结束后,只要丢弃结果中 docid 大于之前读取的 maxDoc 的结果,就能保证一致性。
总结
虽然大部分读者可能不会遇到像 twitter 这样的搜索场景,但是在其设计思维上还是有很多可以借鉴的东西,个人总结它的优点主要有三方面:
- 深入的需求分析:针对静态文本以及动态的信息,进行拆分处理;由于 tweet 都是短文本,只要 8 位就能存储其词出现的位置。
- 利用数组以及数组池减少空间使用提升性能:在其索引结构的设计上,用数组存储其所有的数据,节省内存且 GC 友好;为了平衡好时间和空间,采用不同大小的数组池来实现 Postings List 的存储。
- 利用内存屏障(java volatile 修饰符)来实现高效并发。
另外,出于学习的目的,本人尝试实现了部分功能,代码在这里,欢迎批评指正。
最后,文中大部分信息来自 twitter 的论文,有兴趣的同学可以仔细看看论文,对于我翻译的不正确的地方,也欢迎指正。