【ICCV2019】全卷积一阶段检测器FCOS
FCOS的关键词是全卷积、Anchor-free,是近两年比较哇塞的检测器之一,它结构简单,运行速度快,不需要乱七八糟的前后设定,并且在COCO的mAP表现能超过一众anchor-based检测器。
至于为何在前沿检测器里热度一般,我认为主要是被名字给拉胯了,如果作者有YOLO作者一半的取名水平,FCOS的热度也不至于低于Center-Net。按国际惯例,先给出标题链接:
| Title | accepted to | link | |
| 1 | FCOS: Fully Convolutional One-Stage Object Detction | ICCV2019 | https://arxiv.org/abs/1904.0135 |
| 2 | FCOS: A Simple and Strong Anchor-Free Object Detector | TPAMI2020 | https://arxiv.org/abs/2006.09214 |
对于FCOS的代码实现,本人在原代码的基础上做了一些删减,看起来更纯粹,更利于对算法的理解。
链接:https://github.com/leviome/fcos_pure
1. 前言
近两年学术界的目标检测算法已经完成了anchor-based(YOLOv3,Faster R-CNN等)到anchor-free(如CenterNet、FCOS等)的过渡。以现在的视角回头看,会发现anchor-based检测方法有诸多不合理之处,似乎是一个经典的“人工耽误机器”的例子。相信随着检测算法的步步精进,anchor-based目标检测将会渐渐成为过去式,而最近呈风卷残云之势的transformer加入detection阵营将会加速这一时刻的到来。
FCOS有两个free:anchor-free和proposal-free。砍掉了锚框机制,也免除了2-stage网络的推荐框机制。除此之外,FCOS免去了需要CPU复杂计算的NMS,取而代之的是center-ness(中心性)。
2. 网络结构
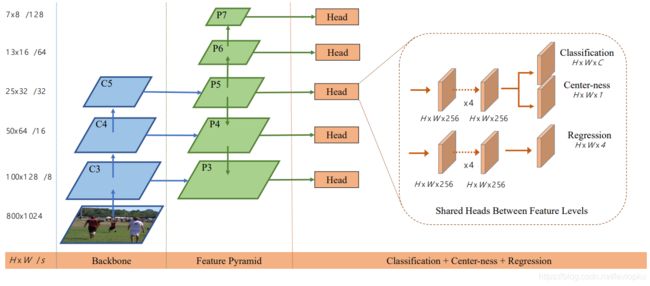
整个检测器由backbone、FP和Head组成。Backbone进行特征抽取,然后将backbone输出的feature map送入FPN得到五个不同尺度的feature map,最后用5个并行的Head,分别处理不同尺度(即不同HW)的feature map。这里特别注意的是:整个网络都只有卷积层。连Regression都用卷积实现,如YOLOv1的做法。
这里五种尺度的feature map,分别负责不同尺度的物体检测。对于大物体,则小feature map对应着粗颗粒度,则可以更好的回归出大物体的B-BOX;对于小物体,更大的feature map对应着细颗粒度,则适用于找精细物体。其他检测器也有类似的trick,比如YOLO v3(链接可戳)用的就是三种尺度。
咱们基于上面的代码输出中间结果,来看最终Head输出的张量shape:

OK,我们看第二个维度的数字,分别有:80、1、4。则对应着上面Head输出的Classification、Center-ness、Regression。然后每个数字都重复5排,对应着5个Head的输出。最后两个维度代表H和W,应该很好理解吧。
2.1 Classification
这个算法是直接拿到COCO数据集跑的,所以有80个类别,从而Classification对应输出的类别维度是80。咱们看一下原文:
Following [15], instead of training a multi-class classifier, we train C binary classifiers.
FCOS用的方法是训练80个二分类器。这也是对应的channel数有80的原因。
对于分类的loss function,这里采用的是Focal Loss(链接可戳),一会儿详解。
2.2 Regression
像其他anchor-free检测器一样,FCOS的B-BOX回归也是先确定中心点,然后回归左上右下四个边的位置;

如上图,l, t, r, b这四个字母对应着left, top, right, bottom这四个单词,即左、上、右、下;
FCOS通过卷积完成回归,最后的输出为H×W×4。最后这个4,就代表左上右下四个边的距离中心点的距离。
2.3 Center-ness
这里的center-ness,翻译成中文就是“中心性”。不妨打开思路:事实上咱们的FCOS是输出框非常dense的检测器,每个H×W规模的feature map天然对应着H×W个检测框(这句话看懂了才说明你懂了FCOS)。实际上,目标物体并不会那么dense,一张图有10个目标就不错了。对于anchor-based的检测器(如Faster RCNN)则通过非极大值抑制(NMS)(不懂的可戳链接)来去除冗余框以稀疏化检测结果。
如果那么检测框那么dense的话,feature map上有的点对于目标来说就可以不那么重要了。那么怎么评价该中心点该不该作为检测框中心呢?这里就有一个Center-ness来进行评估,看公式:

随便代几个数值进去计算,就知道越靠近中心的点center-ness越大,越靠近边缘的点center-ness越小。

咱们再看一段原文:
Center-ness is computed by Eq. (3) and decays from 1 to 0 as the location deviates from the center of the object.
越靠近中心越接近1,越远离中心越接近0。咱们可以进一步看Center-ness的可视化效果:
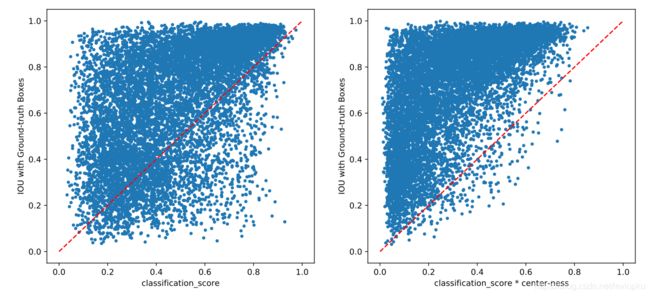
乘上了center-ness以后,那些IOU很低但score很高的检测框就少了很多。完全可以用center-ness代替NMS。并且NMS是CPU操作,计算更会比直接在GPU上运行的center-ness慢不少。
3. Loss Function
任何一个检测器,其loss function一定是重头戏。FCOS的loss function由分类损失函数和回归损失函数构成。
直接看公式:
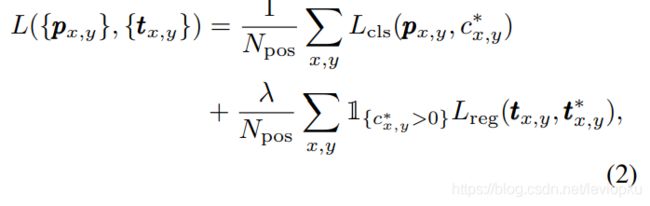
第一部分 采用的是focal loss,第二部分
采用的是focal loss,第二部分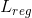 采用的是IOU loss(更多IOU loss可以看《目标检测中的b-box回归损失函数(IOU,GIOU,DIOU,CIOU)》)。如果这里的采用更先进的DIOU或CIOU而不是IOU,说不定有更好的效果。
采用的是IOU loss(更多IOU loss可以看《目标检测中的b-box回归损失函数(IOU,GIOU,DIOU,CIOU)》)。如果这里的采用更先进的DIOU或CIOU而不是IOU,说不定有更好的效果。
公式里都有![]() 和
和![]() 都以x,y为下角标,那么这里的x,y是什么呢? 答:是特征图上的位置。对于H×W的特征图,有H×W个位置,那么就用(x,y)去遍历每一个位置。
都以x,y为下角标,那么这里的x,y是什么呢? 答:是特征图上的位置。对于H×W的特征图,有H×W个位置,那么就用(x,y)去遍历每一个位置。
![]() 代表分类预测结果(即各个类别的score),
代表分类预测结果(即各个类别的score),![]() 代表四边的回归距离。
代表四边的回归距离。
其他参数可以看原文:
Npos denotes the number of positive samples and λ being 1 in this paper is the balance weight for Lreg.
作者设定了![]() 时的预测框为正例(positive),这样就可以算出正例数量
时的预测框为正例(positive),这样就可以算出正例数量 了。而
了。而 只是一个用于平衡的常数,文中设定为1。
只是一个用于平衡的常数,文中设定为1。
最后需要解释的是 , 这个函数在
, 这个函数在![]() 时,取值为1,否则取值为;
时,取值为1,否则取值为;![]() 是什么意思呢?答:在GT中,有类别标注的那个位置。一言以蔽之:只有有目标的位置才值得做回归。
是什么意思呢?答:在GT中,有类别标注的那个位置。一言以蔽之:只有有目标的位置才值得做回归。
文章为本人原创,有问题欢迎留言交流~