hadoop 多机全分布式安装步骤(虚拟机1master+2slave)
文章目录
-
- 1. 虚拟机安装Centos7
- 2. 配置静态IP
- 3. 更改主机名
- 4. 编辑域名映射
- 5. 安装配置Java
- 6. 配置SSH免密登录
- 7 .安装Hadoop
- 8. 关闭防火墙
- 9. 格式化文件系统
- 10. 启动验证
- 11. 第一个MapReduce程序: WordCount
- 12. 关闭Hadoop
参考书:《Hadoop大数据原理与应用》

1. 虚拟机安装Centos7
- 安装3台虚拟机,centos7,一个master,两个slave,安装时可以改hostname, 记得设置密码
- 安装的是4.7Gb的包,选择的 service with GUI
- 选则 NAT 网络链接

ip route show查看路由器网关ipip addr查找本机ip(下面用的着这两个ip)
2. 配置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static # 改静态
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=caf90547-4b5a-46b3-ab7c-2c8fb1f5e4d7
DEVICE=ens33
ONBOOT=yes # 改yes
IPADDR=192.168.253.130 # ip
NETMASK=255.255.255.0
GATEWAY=192.168.253.2 # 网关
DNS1=192.168.253.2 # 跟网关一样即可
保存权限不足,输入w !sudo tee %
- 重启网络
systemctl restart network.service
![]()
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:77:14:71 brd ff:ff:ff:ff:ff:ff
inet 192.168.253.130/24 brd 192.168.253.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::ce06:b26c:ff2d:5288/64 scope link noprefixroute
valid_lft forever preferred_lft forever
同理,另外两台 ip 为:192.168.253.128, 192.168.253.129(个人根据自己的情况来)
3. 更改主机名
- 安装的时候就改了,此处可跳过
- 切换 root 用户,
sudo su vi /etc/hostname, 分别替换内容为 master,slave1, slave2- reboot重启,hostname 查看是否更改

4. 编辑域名映射
为了便捷访问,三台机器都做以下修改,sudo su
在 /etc/hosts追加以下内容,重启
192.168.253.130 master
192.168.253.128 slave1
192.168.253.129 slave2
192.168.31.237 michael
检查各台机器是否能ping通
ping master
ping slave1
ping slave2
5. 安装配置Java
- 卸载
查看java -version
卸载 自带的Oracle OpenJDK,使用Oracle JDK
rpm -qa | grep jdk
yum -y remove java-1.8.0*
yum -y remove java-1.7.0*
-
下载 jdk,位数根据下图来

-
我从宿主机直接考过来安装包
scp root@michael:/home/dnn/jdk-8u281-linux-x64.tar.gz /home/dnn/jdk-8u281-linux-x64.tar.gz
参考 JDK 安装
装到/opt/jdk1.8.0_281/
6. 配置SSH免密登录
- 查询
rpm -qa | grep ssh - 没有的话安装
yum -y install openssh
yum -y install openssh-server
yum -y install openssh-clients
vim /etc/ssh/sshd_config
第43行取消注释,并加一行,3台机器都做
RSAAuthentication yes
PubkeyAuthentication yes
systemctl restart sshd.service,重启服务- 切换普通用户 ctrl+d,回到home
cd ~ ssh-keygen,一直回车cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keys- 将master的公钥复制给slave1,slave2,免密访问从节点
在master里键入以下命令
ssh-copy-id -i ~/.ssh/id_rsa.pub dnn@slave1
ssh slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub dnn@slave2
ssh slave2
ssh master
遇到提示输入 yes, 敲密码
还可以在另外两台里,同样的步骤操作一遍
7 .安装Hadoop
伪分布式可以参考:hadoop 单机伪分布式安装步骤
下载或拷贝 安装包到3台机器
scp dnn@michael:/home/dnn/hadoop-3.3.0.tar.gz /home/dnn/hadoop-3.3.0.tar.gz
到文件目录下,解压 tar -zxvf hadoop-3.3.0.tar.gz
移动到你要放的目录 sudo mv hadoop-3.3.0 /opt/hadoop-3.3.0
赋权限给普通用户dnn,chown -R dnn /opt/hadoop-3.3.0
在主节点上操作:
- 切换 root 用户,新建文件
vim /etc/profile.d/hadoop.sh - 添加内容
export HADOOP_HOME=/opt/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile.d/hadoop.sh
-
切换普通用户,上面已赋权限,
vim /opt/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
54行 改为export JAVA_HOME=/opt/jdk1.8.0_281/
55行添加export HADOOP_SSH_OPTS='-o StrictHostKeyChecking=no'
199行修改export HADOOP_PID_DIR=${HADOOP_HOME}/pids -
vim /opt/hadoop-3.3.0/etc/hadoop/mapred-env.sh
添加export JAVA_HOME=/opt/jdk1.8.0_281/,export HADOOP_MAPRED_PID_DIR=${HADOOP_HOME}/pids -
vim /opt/hadoop-3.3.0/etc/hadoop/yarn-env.sh
添加
export JAVA_HOME=/opt/jdk1.8.0_281/
export YARN_PID_DIR=${HADOOP_HOME}/pids
vim /opt/hadoop-3.3.0/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.253.130:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.0/hdfsdata</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<configuration>
vim /opt/hadoop-3.3.0/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim /opt/hadoop-3.3.0/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 在
/opt/hadoop-3.3.0/etc/hadoop/下,vim workers
删除 localhost, 加入
slave1
slave2
- 同步配置文件到2台slave上
在root下
scp /etc/profile.d/hadoop.sh root@slave1:/etc/profile.d/
scp /etc/profile.d/hadoop.sh root@slave2:/etc/profile.d/
在普通用户下
scp -r /opt/hadoop-3.3.0/etc/hadoop/* dnn@slave1:/opt/hadoop-3.3.0/etc/hadoop/
scp -r /opt/hadoop-3.3.0/etc/hadoop/* dnn@slave2:/opt/hadoop-3.3.0/etc/hadoop/
8. 关闭防火墙
在root下,systemctl disable firewalld.service
重启,再看下状态 systemctl status firewalld.service
显示 inactive(dead), 3台机器都做
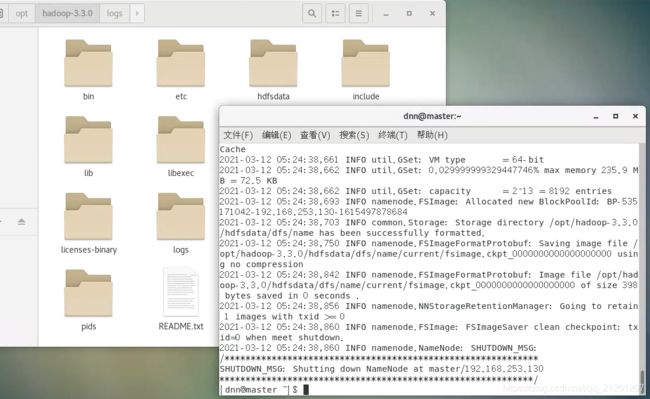
9. 格式化文件系统
只在 master 上 用 普通用户 操作:
hdfs namenode -format
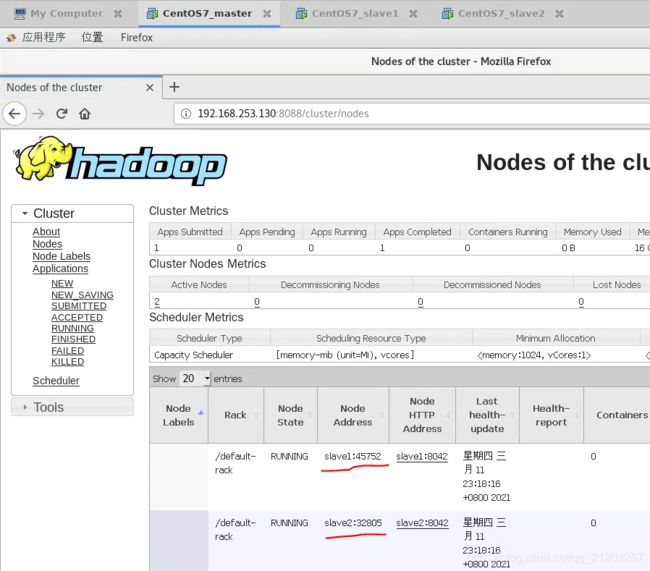
10. 启动验证
在 master 上执行3条命令
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
# 第三条可以用下面的命令,上面的显示过期了,以后弃用
mapred --daemon start historyserver
输入 jps 命令,可以看见进程启动了


11. 第一个MapReduce程序: WordCount
- master:在HDFS根目录下创建目录
[dnn@master ~]$ hdfs dfs -mkdir /InputDataTest
[dnn@master ~]$ hdfs dfs -ls /
Found 2 items
drwxr-xr-x - dnn supergroup 0 2021-03-12 06:49 /InputDataTest
drwxrwx--- - dnn supergroup 0 2021-03-12 06:19 /tmp
- 上传文件到 InputDataTest 文件夹
[dnn@master ~]$ hdfs dfs -put /opt/hadoop-3.3.0/etc/hadoop/hadoop-env.sh /InputDataTest
[dnn@master ~]$ hdfs dfs -put /opt/hadoop-3.3.0/etc/hadoop/mapred-env.sh /InputDataTest
[dnn@master ~]$ hdfs dfs -put /opt/hadoop-3.3.0/etc/hadoop/yarn-env.sh /InputDataTest
[dnn@master ~]$ hdfs dfs -ls /InputDataTest
Found 3 items
-rw-r--r-- 3 dnn supergroup 17017 2021-03-12 06:52 /InputDataTest/hadoop-env.sh
-rw-r--r-- 3 dnn supergroup 1850 2021-03-12 06:53 /InputDataTest/mapred-env.sh
-rw-r--r-- 3 dnn supergroup 6406 2021-03-12 06:53 /InputDataTest/yarn-env.sh
hadoop jar /opt/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /InputDataTest /OutputDataTest
报错: org.apache.hadoop.mapreduce.v2.app.MRAppMaster
vim /opt/hadoop-3.3.0/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop-3.3.0/etc/hadoop:/opt/hadoop-3.3.0/share/hadoop/common/lib/*:/opt/hadoop-3.3.0/share/hadoop/common/*:/opt/hadoop-3.3.0/share/hadoop/hdfs:/opt/hadoop-3.3.0/share/hadoop/hdfs/lib/*:/opt/hadoop-3.3.0/share/hadoop/hdfs/*:/opt/hadoop-3.3.0/share/hadoop/mapreduce/*:/opt/hadoop-3.3.0/share/hadoop/yarn:/opt/hadoop-3.3.0/share/hadoop/yarn/lib/*:/opt/hadoop-3.3.0/share/hadoop/yarn/*
</value>
</property>
</configuration>
重启集群(关闭3条命令,见下面第12节,启动3条命令),再次运行 wordcount 程序
[dnn@master ~]$ hadoop jar /opt/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /InputDataTest /OutputDataTest
2021-03-12 07:11:51,635 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at master/192.168.253.130:8032
2021-03-12 07:11:52,408 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/dnn/.staging/job_1615504213995_0001
2021-03-12 07:11:53,547 INFO input.FileInputFormat: Total input files to process : 3
2021-03-12 07:11:54,066 INFO mapreduce.JobSubmitter: number of splits:3
2021-03-12 07:11:54,271 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1615504213995_0001
2021-03-12 07:11:54,271 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-03-12 07:11:54,624 INFO conf.Configuration: resource-types.xml not found
2021-03-12 07:11:54,624 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-03-12 07:11:55,117 INFO impl.YarnClientImpl: Submitted application application_1615504213995_0001
2021-03-12 07:11:55,164 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1615504213995_0001/
2021-03-12 07:11:55,164 INFO mapreduce.Job: Running job: job_1615504213995_0001
2021-03-12 07:12:05,308 INFO mapreduce.Job: Job job_1615504213995_0001 running in uber mode : false
2021-03-12 07:12:05,319 INFO mapreduce.Job: map 0% reduce 0%
2021-03-12 07:12:21,455 INFO mapreduce.Job: map 33% reduce 0%
2021-03-12 07:12:22,460 INFO mapreduce.Job: map 100% reduce 0%
2021-03-12 07:12:29,514 INFO mapreduce.Job: map 100% reduce 100%
2021-03-12 07:12:29,526 INFO mapreduce.Job: Job job_1615504213995_0001 completed successfully
2021-03-12 07:12:29,652 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=20470
FILE: Number of bytes written=1097885
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=25631
HDFS: Number of bytes written=12134
HDFS: Number of read operations=14
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=42362
Total time spent by all reduces in occupied slots (ms)=4808
Total time spent by all map tasks (ms)=42362
Total time spent by all reduce tasks (ms)=4808
Total vcore-milliseconds taken by all map tasks=42362
Total vcore-milliseconds taken by all reduce tasks=4808
Total megabyte-milliseconds taken by all map tasks=43378688
Total megabyte-milliseconds taken by all reduce tasks=4923392
Map-Reduce Framework
Map input records=667
Map output records=3682
Map output bytes=39850
Map output materialized bytes=20482
Input split bytes=358
Combine input records=3682
Combine output records=1261
Reduce input groups=912
Reduce shuffle bytes=20482
Reduce input records=1261
Reduce output records=912
Spilled Records=2522
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=800
CPU time spent (ms)=2970
Physical memory (bytes) snapshot=615825408
Virtual memory (bytes) snapshot=10951270400
Total committed heap usage (bytes)=385785856
Peak Map Physical memory (bytes)=168960000
Peak Map Virtual memory (bytes)=2738552832
Peak Reduce Physical memory (bytes)=110534656
Peak Reduce Virtual memory (bytes)=2742329344
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=25273
File Output Format Counters
Bytes Written=12134
- 查看结果
[dnn@master ~]$ hdfs dfs -ls /OutputDataTest
Found 2 items
-rw-r--r-- 3 dnn supergroup 0 2021-03-12 07:12 /OutputDataTest/_SUCCESS
-rw-r--r-- 3 dnn supergroup 12134 2021-03-12 07:12 /OutputDataTest/part-r-00000
_SUCCESS 表示运行成功
结果文件是 part-r-00000
hdfs dfs -cat /OutputDataTest/part-r-00000查看结果
[dnn@master ~]$ hdfs dfs -cat /OutputDataTest/part-r-00000
"AS 3
"License"); 3
"log 1
# 466
## 32
### 53
#export 14
$HADOOP_YARN_HOME/share/hadoop/yarn/yarn-service-examples 1
$USER 1
${HADOOP_HOME}/logs 1
${HOME}/.hadooprc 1
'-' 1
'.' 1
'hadoop 1
'mapred 1
'yarn 1
( 1
(ASF) 3
(BUT 1
(Java 2
(Note 1
(command)_(subcommand)_USER. 1
(e.g., 1
(file/dir 1
(i.e., 2
(period) 1
(primarily) 1
(such 1
(superficially) 1
(the 3
) 1
**MUST 1
**MUST** 1
*NOT* 1
+'%Y%m%d%H%M')" 4
--config) 1
--daemon 1
-Dcom.sun.management.jmxremote.authenticate=false 2
-Dcom.sun.management.jmxremote.port=1026" 2
-Dcom.sun.management.jmxremote.ssl=false 2
-Dhadoop.security.logger=foo). 1
-Dsun.security.krb5.debug=true 1
-Dsun.security.spnego.debug" 1
-Dyarn.server.resourcemanager.appsummary.logger=INFO,RMSUMMARY" 1
-XX:+PrintGCDateStamps 2
-XX:+PrintGCDateStamps" 1
-XX:+PrintGCDetails 3
-XX:+PrintGCTimeStamps 3
-Xloggc:${HADOOP_LOG_DIR}/gc-rm.log-$(date 4
-Xms). 1
-Xmx). 1
-blah). 1
-f 1
-ls 1
-o 2
-s)} 1
. 1
.. 1
... 2
.hadooprc 1
/etc/profile.d 2
/tmp 1
10 1
2.0 3
2NN 1
<----- 1
= 1
> 12
12. 关闭Hadoop
mr-jobhistory-daemon.sh stop historyserver
# 或者 mapred --daemon stop historyserver
stop-yarn.sh
stop-dfs.sh
好几天了,跟着书,终于安装成功了!
我的CSDN博客地址 https://michael.blog.csdn.net/
长按或扫码关注我的公众号(Michael阿明),一起加油、一起学习进步!
